 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Score for Unsupervised Foreground Background Separation of Document Images
Apr 03, 2022
Foreground-background separation is an important problem in document image analysis. Popular unsupervised binarization methods (such as the Sauvola's algorithm) employ adaptive thresholding to classify pixels as foreground or background. In this work, we propose a novel approach for computing confidence scores of the classification in such algorithms. This score provides an insight of the confidence level of the prediction. The computational complexity of the proposed approach is the same as the underlying binarization algorithm. Our experiments illustrate the utility of the proposed scores in various applications like document binarization, document image cleanup, and texture addition.
PAMMELA: Policy Administration Methodology using Machine Learning
Nov 13, 2021



In recent years, Attribute-Based Access Control (ABAC) has become quite popular and effective for enforcing access control in dynamic and collaborative environments. Implementation of ABAC requires the creation of a set of attribute-based rules which cumulatively form a policy. Designing an ABAC policy ab initio demands a substantial amount of effort from the system administrator. Moreover, organizational changes may necessitate the inclusion of new rules in an already deployed policy. In such a case, re-mining the entire ABAC policy will require a considerable amount of time and administrative effort. Instead, it is better to incrementally augment the policy. Keeping these aspects of reducing administrative overhead in mind, in this paper, we propose PAMMELA, a Policy Administration Methodology using Machine Learning to help system administrators in creating new ABAC policies as well as augmenting existing ones. PAMMELA can generate a new policy for an organization by learning the rules of a policy currently enforced in a similar organization. For policy augmentation, PAMMELA can infer new rules based on the knowledge gathered from the existing rules. Experimental results show that our proposed approach provides a reasonably good performance in terms of the various machine learning evaluation metrics as well as execution time.
Light-weight Document Image Cleanup using Perceptual Loss
May 19, 2021



Smartphones have enabled effortless capturing and sharing of documents in digital form. The documents, however, often undergo various types of degradation due to aging, stains, or shortcoming of capturing environment such as shadow, non-uniform lighting, etc., which reduces the comprehensibility of the document images. In this work, we consider the problem of document image cleanup on embedded applications such as smartphone apps, which usually have memory, energy, and latency limitations due to the device and/or for best human user experience. We propose a light-weight encoder decoder based convolutional neural network architecture for removing the noisy elements from document images. To compensate for generalization performance with a low network capacity, we incorporate the perceptual loss for knowledge transfer from pre-trained deep CNN network in our loss function. In terms of the number of parameters and product-sum operations, our models are 65-1030 and 3-27 times, respectively, smaller than existing state-of-the-art document enhancement models. Overall, the proposed models offer a favorable resource versus accuracy trade-off and we empirically illustrate the efficacy of our approach on several real-world benchmark datasets.
Tabular Structure Detection from Document Images for Resource Constrained Devices Using A Row Based Similarity Measure
Aug 26, 2020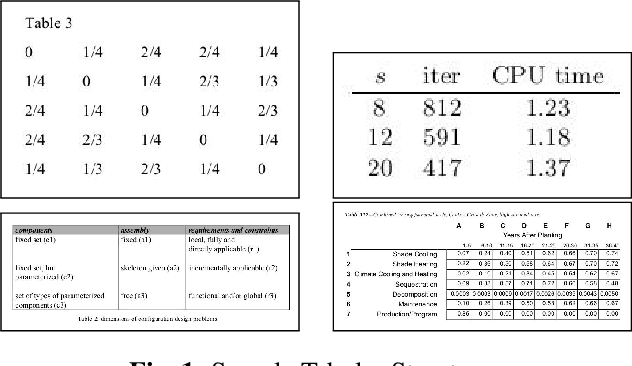
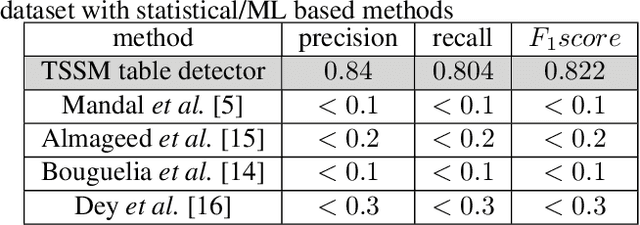

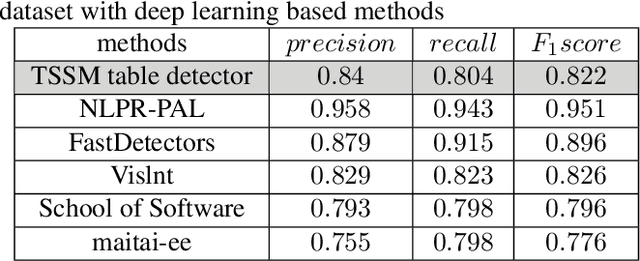
Tabular structures are used to present crucial information in a structured and crisp manner. Detection of such regions is of great importance for proper understanding of a document. Tabular structures can be of various layouts and types. Therefore, detection of these regions is a hard problem. Most of the existing techniques detect tables from a document image by using prior knowledge of the structures of the tables. However, these methods are not applicable for generalized tabular structures. In this work, we propose a similarity measure to find similarities between pairs of rows in a tabular structure. This similarity measure is utilized to identify a tabular region. Since the tabular regions are detected exploiting the similarities among all rows, the method is inherently independent of layouts of the tabular regions present in the training data. Moreover, the proposed similarity measure can be used to identify tabular regions without using large sets of parameters associated with recent deep learning based methods. Thus, the proposed method can easily be used with resource constrained devices such as mobile devices without much of an overhead.
Anveshak - A Groundtruth Generation Tool for Foreground Regions of Document Images
Aug 09, 2017
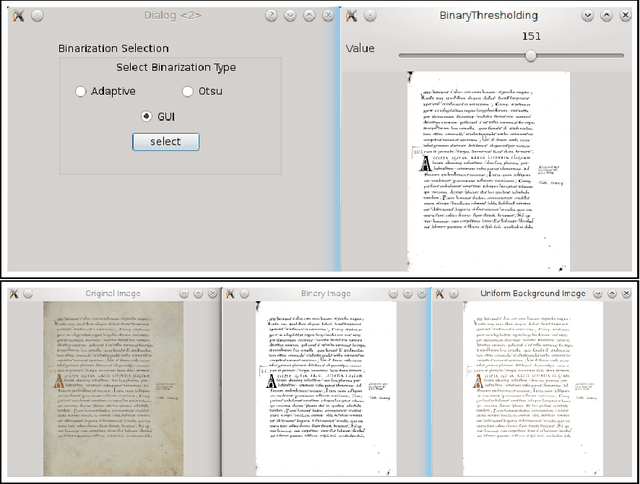
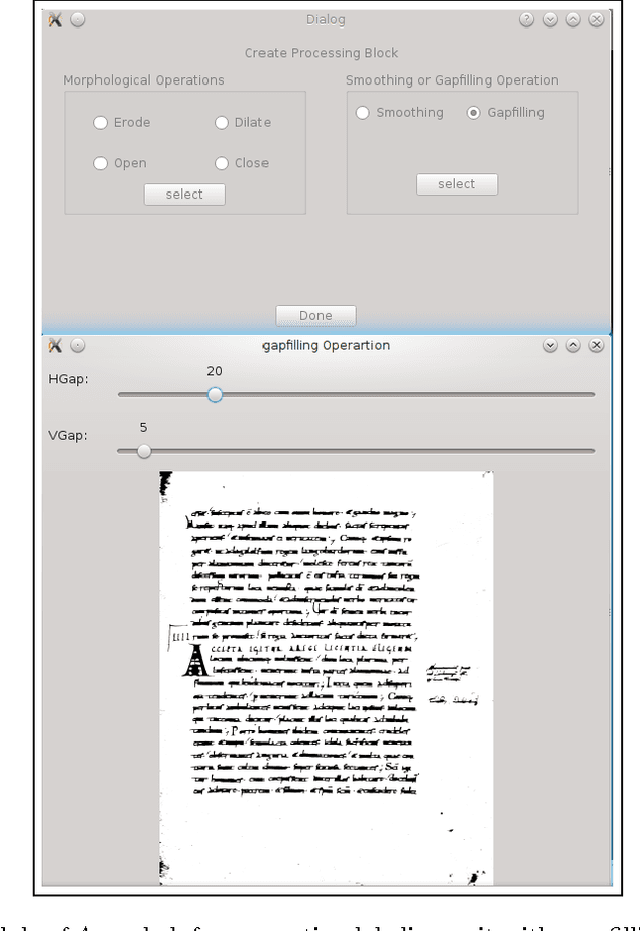

We propose a graphical user interface based groundtruth generation tool in this paper. Here, annotation of an input document image is done based on the foreground pixels. Foreground pixels are grouped together with user interaction to form labeling units. These units are then labeled by the user with the user defined labels. The output produced by the tool is an image with an XML file containing its metadata information. This annotated data can be further used in different applications of document image analysis.