 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPD:An Incremental Prototype based DBSCAN for large-scale data with cluster representatives
Feb 16, 2022
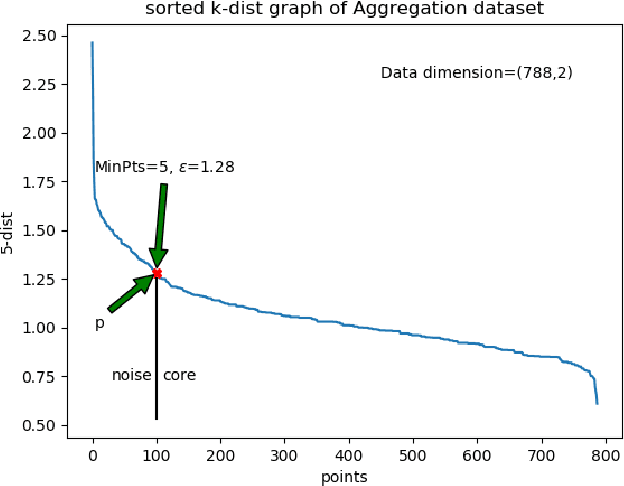
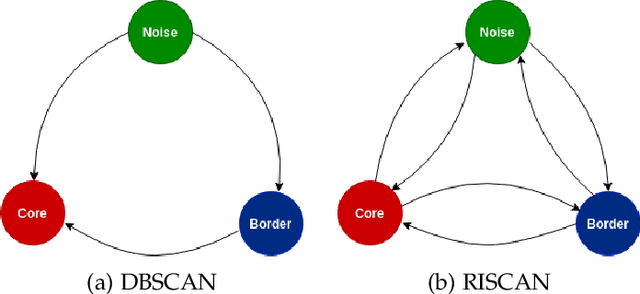
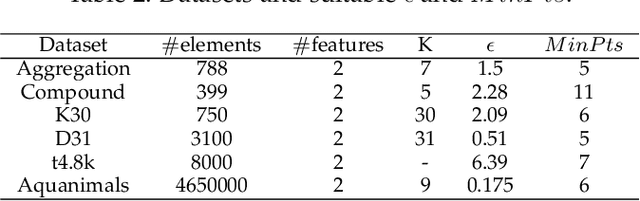
DBSCAN is a fundamental density-based clustering technique that identifies any arbitrary shape of the clusters. However, it becomes infeasible while handling big data. On the other hand, centroid-based clustering is important for detecting patterns in a dataset since unprocessed data points can be labeled to their nearest centroid. However, it can not detect non-spherical clusters. For a large data, it is not feasible to store and compute labels of every samples. These can be done as and when the information is required. The purpose can be accomplished when clustering act as a tool to identify cluster representatives and query is served by assigning cluster labels of nearest representative. In this paper, we propose an Incremental Prototype-based DBSCAN (IPD) algorithm which is designed to identify arbitrary-shaped clusters for large-scale data. Additionally, it chooses a set of representatives for each cluster.
Novel Radiomic Feature for Survival Prediction of Lung Cancer Patients using Low-Dose CBCT Images
Mar 07, 2020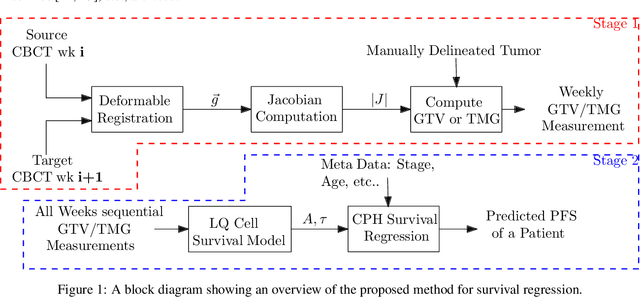

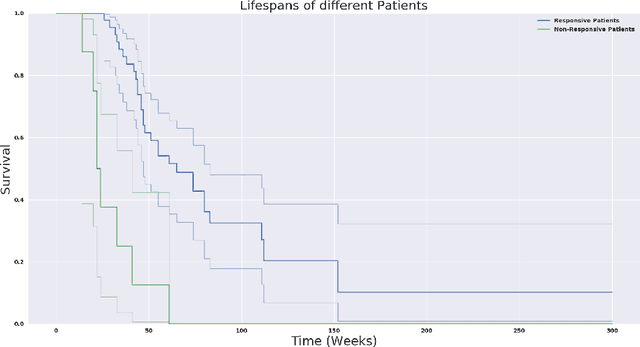

Prediction of survivability in a patient for tumor progression is useful to estimate the effectiveness of a treatment protocol. In our work, we present a model to take into account the heterogeneous nature of a tumor to predict survival. The tumor heterogeneity is measured in terms of its mass by combining information regarding the radiodensity obtained in images with the gross tumor volume (GTV). We propose a novel feature called Tumor Mass within a GTV (TMG), that improves the prediction of survivability, compared to existing models which use GTV. Weekly variation in TMG of a patient is computed from the image data and also estimated from a cell survivability model. The parameters obtained from the cell survivability model are indicatives of changes in TMG over the treatment period. We use these parameters along with other patient metadata to perform survival analysis and regression. Cox's Proportional Hazard survival regression was performed using these data. Significant improvement in the average concordance index from 0.47 to 0.64 was observed when TMG is used in the model instead of GTV. The experiments show that there is a difference in the treatment response in responsive and non-responsive patients and that the proposed method can be used to predict patient survivability.
Early Response Assessment in Lung Cancer Patients using Spatio-temporal CBCT Images
Mar 07, 2020
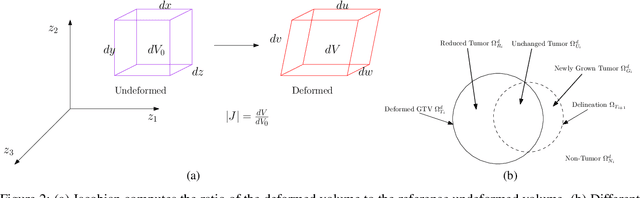
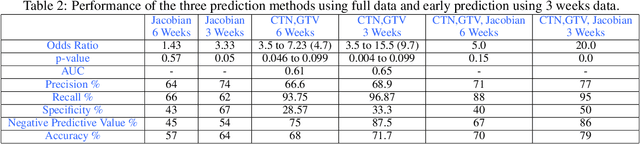
We report a model to predict patient's radiological response to curative radiation therapy (RT) for non-small-cell lung cancer (NSCLC). Cone-Beam Computed Tomography images acquired weekly during the six-week course of RT were contoured with the Gross Tumor Volume (GTV) by senior radiation oncologists for 53 patients (7 images per patient). Deformable registration of the images yielded six deformation fields for each pair of consecutive images per patient. Jacobian of a field provides a measure of local expansion/contraction and is used in our model. Delineations were compared post-registration to compute unchanged ($U$), newly grown ($G$), and reduced ($R$) regions within GTV. The mean Jacobian of these regions $\mu_U$, $\mu_G$ and $\mu_R$ are statistically compared and a response assessment model is proposed. A good response is hypothesized if $\mu_R < 1.0$, $\mu_R < \mu_U$, and $\mu_G < \mu_U$. For early prediction of post-treatment response, first, three weeks' images are used. Our model predicted clinical response with a precision of $74\%$. Using reduction in CT numbers (CTN) and percentage GTV reduction as features in logistic regression, yielded an area-under-curve of 0.65 with p=0.005. Combining logistic regression model with the proposed hypothesis yielded an odds ratio of 20.0 (p=0.0).
A CNN With Multi-scale Convolution for Hyperspectral Image Classification using Target-Pixel-Orientation scheme
Feb 02, 2020


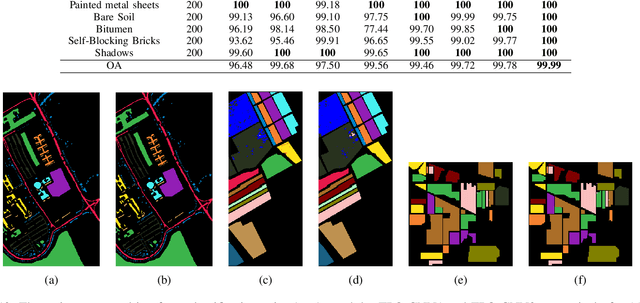
Recently, CNN is a popular choice to handle the hyperspectral image classification challenges. In spite of having such large spectral information in Hyper-Spectral Image(s) (HSI), it creates a curse of dimensionality. Also, large spatial variability of spectral signature adds more difficulty in classification problem. Additionally, training a CNN in the end to end fashion with scarced training examples is another challenging and interesting problem. In this paper, a novel target-patch-orientation method is proposed to train a CNN based network. Also, we have introduced a hybrid of 3D-CNN and 2D-CNN based network architecture to implement band reduction and feature extraction methods, respectively. Experimental results show that our method outperforms the accuracies reported in the existing state of the art methods.
CNAK : Cluster Number Assisted K-means
Nov 20, 2019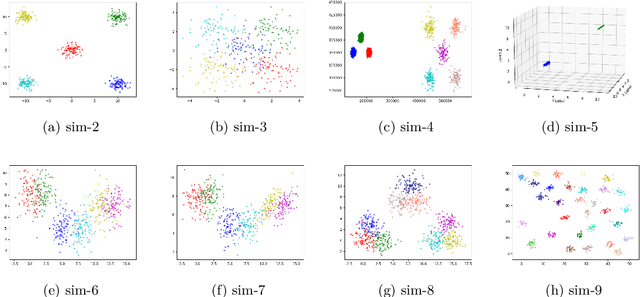
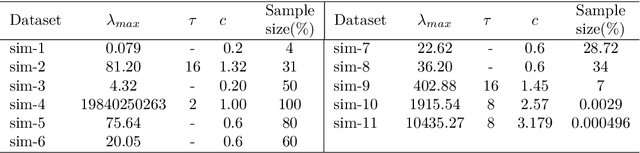
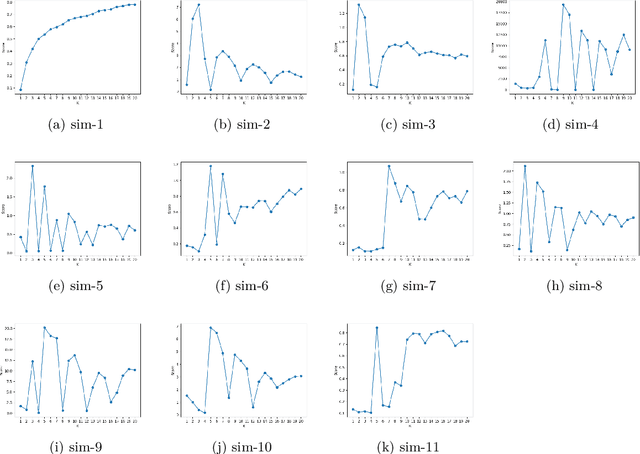
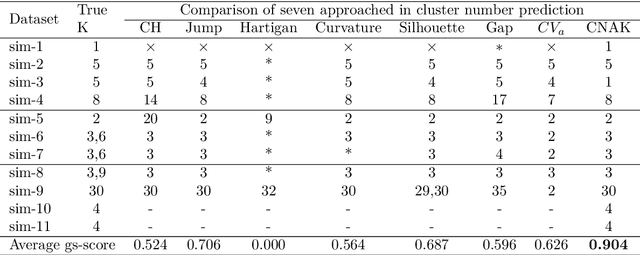
Determining the number of clusters present in a dataset is an important problem in cluster analysis. Conventional clustering techniques generally assume this parameter to be provided up front. %user supplied. %Recently, robustness of any given clustering algorithm is analyzed to measure cluster stability/instability which in turn determines the cluster number. In this paper, we propose a method which analyzes cluster stability for predicting the cluster number. Under the same computational framework, the technique also finds representatives of the clusters. The method is apt for handling big data, as we design the algorithm using \emph{Monte-Carlo} simulation. Also, we explore a few pertinent issues found to be of also clustering. Experiments reveal that the proposed method is capable of identifying a single cluster. It is robust in handling high dimensional dataset and performs reasonably well over datasets having cluster imbalance. Moreover, it can indicate cluster hierarchy, if present. Overall we have observed significant improvement in speed and quality for predicting cluster numbers as well as the composition of clusters in a large dataset.
HSD-CNN: Hierarchically self decomposing CNN architecture using class specific filter sensitivity analysis
Nov 21, 2018
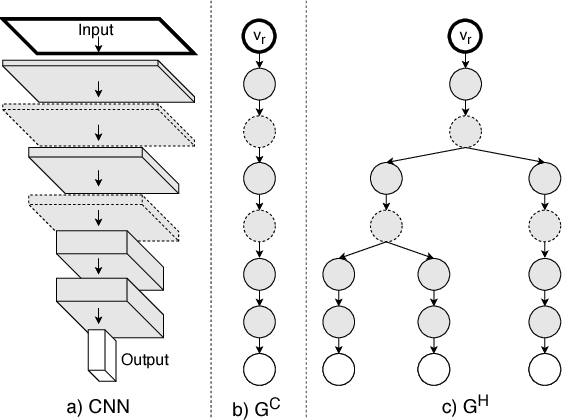

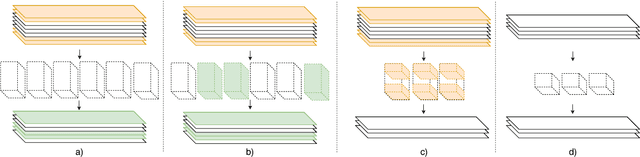
Conventional Convolutional neural networks (CNN) are trained on large domain datasets and are hence typically over-represented and inefficient in limited class applications. An efficient way to convert such large many-class pre-trained networks into small few-class networks is through a hierarchical decomposition of its feature maps. To alleviate this issue, we propose an automated framework for such decomposition in Hierarchically Self Decomposing CNN (HSD-CNN), in four steps. HSD-CNN is derived automatically using a class-specific filter sensitivity analysis that quantifies the impact of specific features on a class prediction. The decomposed hierarchical network can be utilized and deployed directly to obtain sub-networks for a subset of classes, and it is shown to perform better without the requirement of retraining these sub-networks. Experimental results show that HSD-CNN generally does not degrade accuracy if the full set of classes are used. Interestingly, when operating on known subsets of classes, HSD-CNN has an improvement in accuracy with a much smaller model size, requiring much fewer operations. HSD-CNN flow is verified on the CIFAR10, CIFAR100 and CALTECH101 data sets. We report accuracies up to $85.6\%$ ( $94.75\%$ ) on scenarios with 13 ( 4 ) classes of CIFAR100, using a pre-trained VGG-16 network on the full data set. In this case, the proposed HSD-CNN requires $3.97 \times$ fewer parameters and has $71.22\%$ savings in operations, in comparison to baseline VGG-16 containing features for all 100 classes.
Anveshak - A Groundtruth Generation Tool for Foreground Regions of Document Images
Aug 09, 2017
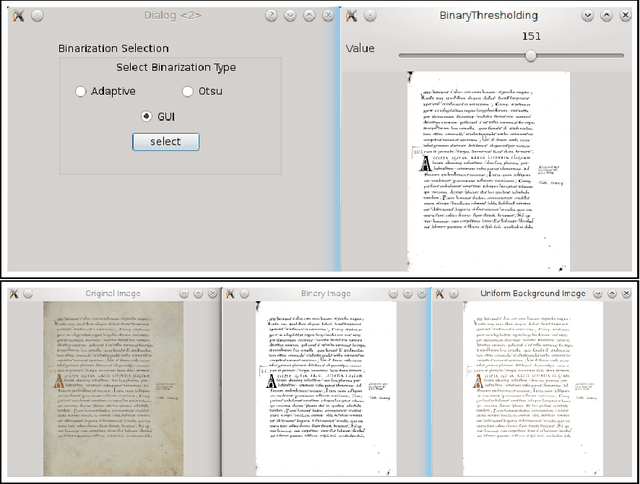
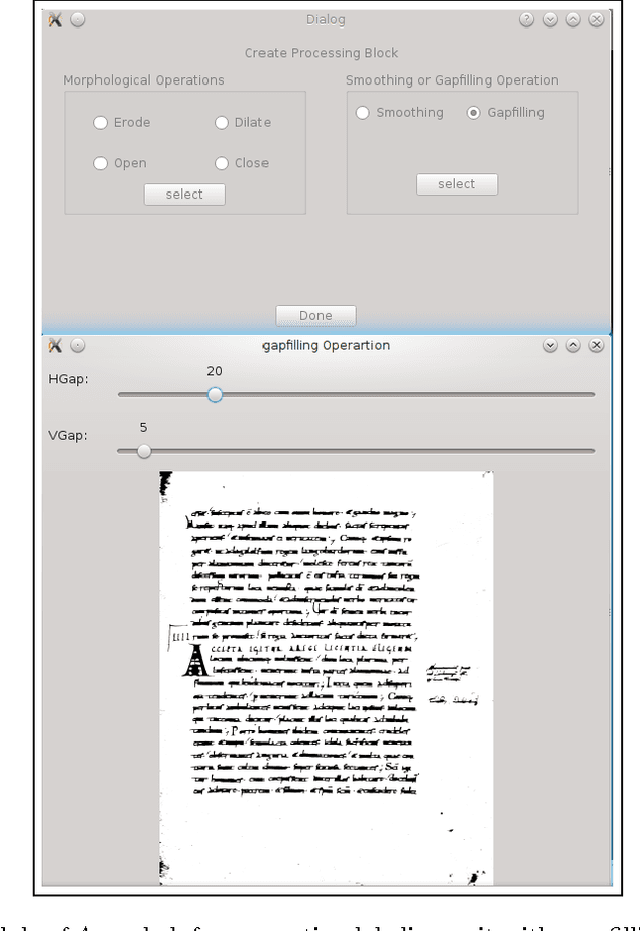

We propose a graphical user interface based groundtruth generation tool in this paper. Here, annotation of an input document image is done based on the foreground pixels. Foreground pixels are grouped together with user interaction to form labeling units. These units are then labeled by the user with the user defined labels. The output produced by the tool is an image with an XML file containing its metadata information. This annotated data can be further used in different applications of document image analysis.
Low-complexity feedback-channel-free distributed video coding using Local Rank Transform
Jul 15, 2016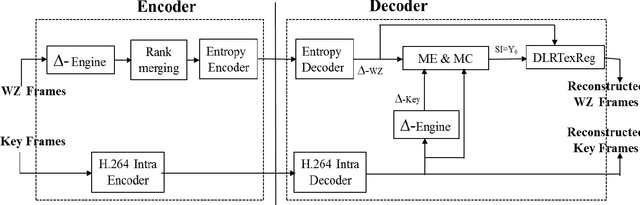
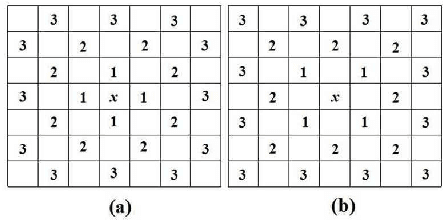
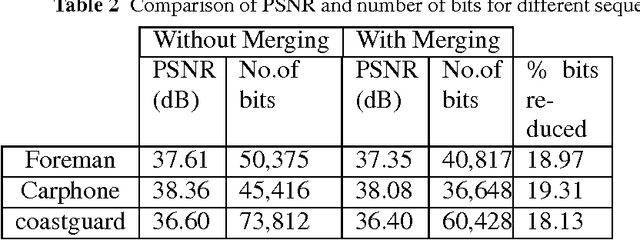
In this paper, we propose a new feedback-channel-free Distributed Video Coding (DVC) algorithm using Local Rank Transform (LRT). The encoder computes LRT by considering selected neighborhood pixels of Wyner-Ziv frame. The ranks from the modified LRT are merged, and their positions are entropy coded and sent to the decoder. In addition, means of each block of Wyner-Ziv frame are also transmitted to assist motion estimation. Using these measurements, the decoder generates side information (SI) by implementing motion estimation and compensation in LRT domain. An iterative algorithm is executed on SI using LRT to reconstruct the Wyner-Ziv frame. Experimental results show that the coding efficiency of our codec is close to the efficiency of pixel domain distributed video coders based on Low-Density Parity Check and Accumulate (LDPCA) or turbo codes, with less encoder complexity.