 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Performance Profiling of Large Language Models
May 28, 2026Large language models (LLMs) frequently achieve impressive scores on standardized benchmarks, yet accuracy alone offers a limited view of their capabilities. Evaluating open-source LLMs through leaderboards faces persistent issues like data contamination, narrow task scope, and weak alignment with real-world reliability. Benchmark-based evaluations such as MMLU PRO, BBH, or IFEval primarily capture \textit{what} a model outputs on fixed test sets, not \textit{how} it processes information, calibrates uncertainty, or structures internal knowledge. In this article, we advocate for a shift from benchmark-centric evaluation toward a complementary, \textit{state-centered intrinsic assessment} of LLMs. To this end, we introduce \textbf{Latent Performance Profiling (LPP)} -- a framework that derives task-agnostic diagnostics from hidden activations and output distributions. LPP defines a set of scalar metrics on a model's latent representations and dynamics, revealing scale-independent traits that enable interpretable comparisons and uncover hidden vulnerabilities. Unlike static accuracy scores, LPP provides stable, architecture-sensitive signatures across models of similar size. With extensive empirical analyses across eight LLMs, spanning a size range of 0.5B-14B, we demonstrate that models with similar benchmark scores can exhibit contrasting latent profiles, such as differences in entropy or adaptability. Guided by these insights, we design synthetic probes for uncertainty and symbolic reasoning that align with intrinsic metrics while decoupling from leaderboard bias. We recommend that reporting LPP alongside benchmarks provides a deeper, interpretable understanding of model behavior, enabling more reliable model selection, safety assessment, and evaluation beyond surface-level accuracy.
Generating Key Postures of Bharatanatyam Adavus with Pose Estimation
Mar 31, 2026Preserving intangible cultural dances rooted in centuries of tradition and governed by strict structural and symbolic rules presents unique challenges in the digital era. Among these, Bharatanatyam, a classical Indian dance form, stands out for its emphasis on codified adavus and precise key postures. Accurately generating these postures is crucial not only for maintaining anatomical and stylistic integrity, but also for enabling effective documentation, analysis, and transmission to broader global audiences through digital means. We propose a pose-aware generative framework integrated with a pose estimation module, guided by keypoint-based loss and pose consistency constraints. These supervisory signals ensure anatomical accuracy and stylistic integrity in the synthesized outputs. We evaluate four configurations: standard conditional generative adversarial network (cGAN), cGAN with pose supervision, conditional diffusion, and conditional diffusion with pose supervision. Each model is conditioned on key posture class labels and optimized to maintain geometric structure. In both cGAN and conditional diffusion settings, the integrated pose guidance aligns generated poses with ground-truth keypoint structures, promoting cultural fidelity. Our results demonstrate that incorporating pose supervision significantly enhances the quality, realism, and authenticity of generated Bharatanatyam postures. This framework provides a scalable approach for the digital preservation, education, and dissemination of traditional dance forms, enabling high-fidelity generation without compromising cultural precision. Code is available at https://github.com/jagidsh/Generating-Key-Postures-of-Bharatanatyam-Adavus-with-Pose-Estimation.
* Published in ICVGIP, 2025
In-situ On-demand Digital Image Correlation: A New Data-rich Characterization Paradigm for Deformation and Damage Development in Solids
Jan 24, 2026Digital image correlation (DIC) has become one of the most popular methods for deformation characterization in experimental mechanics. DIC is based on optical images taken during experimentation and post-test image processing. Its advantages include the capability to capture full-field deformation in a non-contact manner, the robustness in characterizing excessive deformation induced by events such as yielding and cracking, and the versatility to integrate optical cameras with a variety of open-source and commercial codes. In this paper, we developed a new paradigm of DIC analysis by integrating camera control into the DIC process flow. The essential idea is to dynamically increase the camera imaging frame rate with excessive deformation or deformation rate, while maintaining a relatively low imaging frame rate with small and slow deformation. We refer to this new DIC paradigm as in-situ on-demand (ISOD) DIC. ISOD DIC enables real-time deformation analysis, visualization, and closed-loop camera control. ISOD DIC has captured approximately 178% more images than conventional DIC for samples undergoing crack growth due to its dynamically adjusted frame rate, with the potential to significantly enhance data richness for damage inspection without consuming excessive storage space and analysis time, thereby benefiting the characterization of intrinsic constitutive behaviors and damage mechanisms
Towards an Action-Centric Ontology for Cooking Procedures Using Temporal Graphs
Sep 04, 2025Formalizing cooking procedures remains a challenging task due to their inherent complexity and ambiguity. We introduce an extensible domain-specific language for representing recipes as directed action graphs, capturing processes, transfers, environments, concurrency, and compositional structure. Our approach enables precise, modular modeling of complex culinary workflows. Initial manual evaluation on a full English breakfast recipe demonstrates the DSL's expressiveness and suitability for future automated recipe analysis and execution. This work represents initial steps towards an action-centric ontology for cooking, using temporal graphs to enable structured machine understanding, precise interpretation, and scalable automation of culinary processes - both in home kitchens and professional culinary settings.
Unsupervised Multi-Clustering and Decision-Making Strategies for 4D-STEM Orientation Mapping
Mar 09, 2025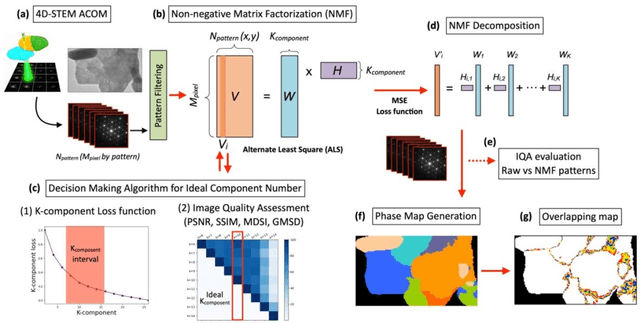
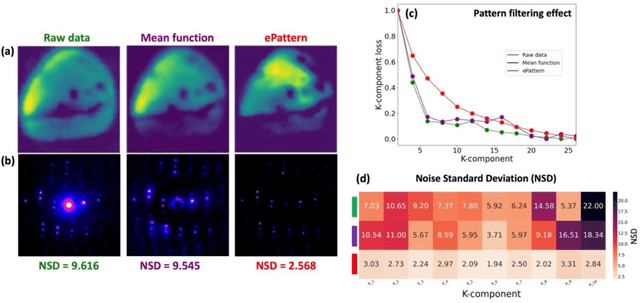
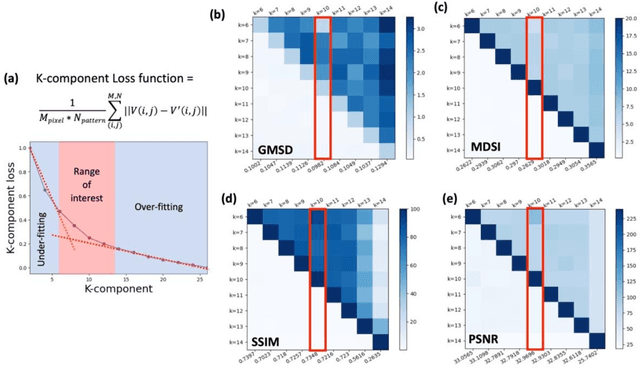
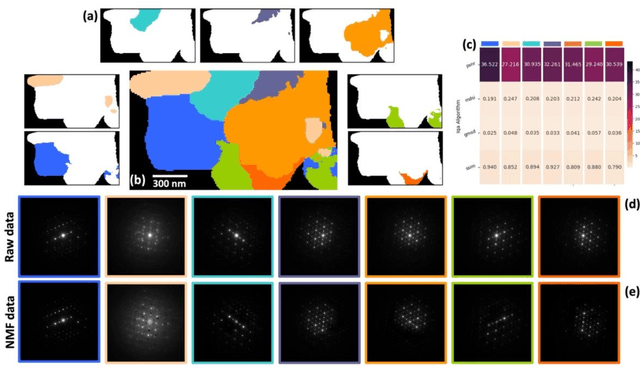
This study presents a novel integration of unsupervised learning and decision-making strategies for the advanced analysis of 4D-STEM datasets, with a focus on non-negative matrix factorization (NMF) as the primary clustering method. Our approach introduces a systematic framework to determine the optimal number of components (k) required for robust and interpretable orientation mapping. By leveraging the K-Component Loss method and Image Quality Assessment (IQA) metrics, we effectively balance reconstruction fidelity and model complexity. Additionally, we highlight the critical role of dataset preprocessing in improving clustering stability and accuracy. Furthermore, our spatial weight matrix analysis provides insights into overlapping regions within the dataset by employing threshold-based visualization, facilitating a detailed understanding of cluster interactions. The results demonstrate the potential of combining NMF with advanced IQA metrics and preprocessing techniques for reliable orientation mapping and structural analysis in 4D-STEM datasets, paving the way for future applications in multi-dimensional material characterization.
Enhancing FKG.in: automating Indian food composition analysis
Dec 09, 2024


This paper presents a novel approach to compute food composition data for Indian recipes using a knowledge graph for Indian food (FKG.in) and LLMs. The primary focus is to provide a broad overview of an automated food composition analysis workflow and describe its core functionalities: nutrition data aggregation, food composition analysis, and LLM-augmented information resolution. This workflow aims to complement FKG.in and iteratively supplement food composition data from verified knowledge bases. Additionally, this paper highlights the challenges of representing Indian food and accessing food composition data digitally. It also reviews three key sources of food composition data: the Indian Food Composition Tables, the Indian Nutrient Databank, and the Nutritionix API. Furthermore, it briefly outlines how users can interact with the workflow to obtain diet-based health recommendations and detailed food composition information for numerous recipes. We then explore the complex challenges of analyzing Indian recipe information across dimensions such as structure, multilingualism, and uncertainty as well as present our ongoing work on LLM-based solutions to address these issues. The methods proposed in this workshop paper for AI-driven knowledge curation and information resolution are application-agnostic, generalizable, and replicable for any domain.
Building FKG.in: a Knowledge Graph for Indian Food
Sep 01, 2024


This paper presents an ontology design along with knowledge engineering, and multilingual semantic reasoning techniques to build an automated system for assimilating culinary information for Indian food in the form of a knowledge graph. The main focus is on designing intelligent methods to derive ontology designs and capture all-encompassing knowledge about food, recipes, ingredients, cooking characteristics, and most importantly, nutrition, at scale. We present our ongoing work in this workshop paper, describe in some detail the relevant challenges in curating knowledge of Indian food, and propose our high-level ontology design. We also present a novel workflow that uses AI, LLM, and language technology to curate information from recipe blog sites in the public domain to build knowledge graphs for Indian food. The methods for knowledge curation proposed in this paper are generic and can be replicated for any domain. The design is application-agnostic and can be used for AI-driven smart analysis, building recommendation systems for Personalized Digital Health, and complementing the knowledge graph for Indian food with contextual information such as user information, food biochemistry, geographic information, agricultural information, etc.
Generative AI for Software Metadata: Overview of the Information Retrieval in Software Engineering Track at FIRE 2023
Oct 27, 2023The Information Retrieval in Software Engineering (IRSE) track aims to develop solutions for automated evaluation of code comments in a machine learning framework based on human and large language model generated labels. In this track, there is a binary classification task to classify comments as useful and not useful. The dataset consists of 9048 code comments and surrounding code snippet pairs extracted from open source github C based projects and an additional dataset generated individually by teams using large language models. Overall 56 experiments have been submitted by 17 teams from various universities and software companies. The submissions have been evaluated quantitatively using the F1-Score and qualitatively based on the type of features developed, the supervised learning model used and their corresponding hyper-parameters. The labels generated from large language models increase the bias in the prediction model but lead to less over-fitted results.
Smart Knowledge Transfer using Google-like Search
Aug 12, 2023


To address the issue of rising software maintenance cost due to program comprehension challenges, we propose SMARTKT (Smart Knowledge Transfer), a search framework, which extracts and integrates knowledge related to various aspects of an application in form of a semantic graph. This graph supports syntax and semantic queries and converts the process of program comprehension into a {\em google-like} search problem.
Improving Contextualized Topic Models with Negative Sampling
Mar 27, 2023



Topic modeling has emerged as a dominant method for exploring large document collections. Recent approaches to topic modeling use large contextualized language models and variational autoencoders. In this paper, we propose a negative sampling mechanism for a contextualized topic model to improve the quality of the generated topics. In particular, during model training, we perturb the generated document-topic vector and use a triplet loss to encourage the document reconstructed from the correct document-topic vector to be similar to the input document and dissimilar to the document reconstructed from the perturbed vector. Experiments for different topic counts on three publicly available benchmark datasets show that in most cases, our approach leads to an increase in topic coherence over that of the baselines. Our model also achieves very high topic diversity.