 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2WTM: Spherical Sliced-Wasserstein Autoencoder for Topic Modeling
Jul 16, 2025



Modeling latent representations in a hyperspherical space has proven effective for capturing directional similarities in high-dimensional text data, benefiting topic modeling. Variational autoencoder-based neural topic models (VAE-NTMs) commonly adopt the von Mises-Fisher prior to encode hyperspherical structure. However, VAE-NTMs often suffer from posterior collapse, where the KL divergence term in the objective function highly diminishes, leading to ineffective latent representations. To mitigate this issue while modeling hyperspherical structure in the latent space, we propose the Spherical Sliced Wasserstein Autoencoder for Topic Modeling (S2WTM). S2WTM employs a prior distribution supported on the unit hypersphere and leverages the Spherical Sliced-Wasserstein distance to align the aggregated posterior distribution with the prior. Experimental results demonstrate that S2WTM outperforms state-of-the-art topic models, generating more coherent and diverse topics while improving performance on downstream tasks.
DTECT: Dynamic Topic Explorer & Context Tracker
Jul 10, 2025The explosive growth of textual data over time presents a significant challenge in uncovering evolving themes and trends. Existing dynamic topic modeling techniques, while powerful, often exist in fragmented pipelines that lack robust support for interpretation and user-friendly exploration. We introduce DTECT (Dynamic Topic Explorer & Context Tracker), an end-to-end system that bridges the gap between raw textual data and meaningful temporal insights. DTECT provides a unified workflow that supports data preprocessing, multiple model architectures, and dedicated evaluation metrics to analyze the topic quality of temporal topic models. It significantly enhances interpretability by introducing LLM-driven automatic topic labeling, trend analysis via temporally salient words, interactive visualizations with document-level summarization, and a natural language chat interface for intuitive data querying. By integrating these features into a single, cohesive platform, DTECT empowers users to more effectively track and understand thematic dynamics. DTECT is open-source and available at https://github.com/AdhyaSuman/DTECT.
Evaluating LLMs and Pre-trained Models for Text Summarization Across Diverse Datasets
Feb 26, 2025Text summarization plays a crucial role in natural language processing by condensing large volumes of text into concise and coherent summaries. As digital content continues to grow rapidly and the demand for effective information retrieval increases, text summarization has become a focal point of research in recent years. This study offers a thorough evaluation of four leading pre-trained and open-source large language models: BART, FLAN-T5, LLaMA-3-8B, and Gemma-7B, across five diverse datasets CNN/DM, Gigaword, News Summary, XSum, and BBC News. The evaluation employs widely recognized automatic metrics, including ROUGE-1, ROUGE-2, ROUGE-L, BERTScore, and METEOR, to assess the models' capabilities in generating coherent and informative summaries. The results reveal the comparative strengths and limitations of these models in processing various text types.
How Green are Neural Language Models? Analyzing Energy Consumption in Text Summarization Fine-tuning
Jan 26, 2025



Artificial intelligence systems significantly impact the environment, particularly in natural language processing (NLP) tasks. These tasks often require extensive computational resources to train deep neural networks, including large-scale language models containing billions of parameters. This study analyzes the trade-offs between energy consumption and performance across three neural language models: two pre-trained models (T5-base and BART-base), and one large language model (LLaMA 3-8B). These models were fine-tuned for the text summarization task, focusing on generating research paper highlights that encapsulate the core themes of each paper. A wide range of evaluation metrics, including ROUGE, METEOR, MoverScore, BERTScore, and SciBERTScore, were employed to assess their performance. Furthermore, the carbon footprint associated with fine-tuning each model was measured, offering a comprehensive assessment of their environmental impact. This research underscores the importance of incorporating environmental considerations into the design and implementation of neural language models and calls for the advancement of energy-efficient AI methodologies.
Can pre-trained language models generate titles for research papers?
Sep 22, 2024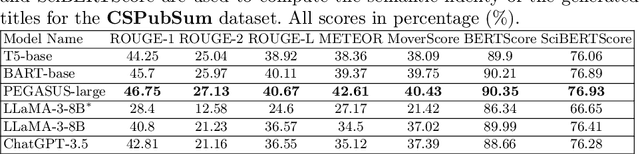



The title of a research paper communicates in a succinct style the main theme and, sometimes, the findings of the paper. Coming up with the right title is often an arduous task, and therefore, it would be beneficial to authors if title generation can be automated. In this paper, we fine-tune pre-trained and large language models to generate titles of papers from their abstracts. We also use ChatGPT in a zero-shot setting to generate paper titles. The performance of the models is measured with ROUGE, METEOR, MoverScore, BERTScore and SciBERTScore metrics.
Transfer Learning and Transformer Architecture for Financial Sentiment Analysis
Apr 28, 2024Financial sentiment analysis allows financial institutions like Banks and Insurance Companies to better manage the credit scoring of their customers in a better way. Financial domain uses specialized mechanisms which makes sentiment analysis difficult. In this paper, we propose a pre-trained language model which can help to solve this problem with fewer labelled data. We extend on the principles of Transfer learning and Transformation architecture principles and also take into consideration recent outbreak of pandemics like COVID. We apply the sentiment analysis to two different sets of data. We also take smaller training set and fine tune the same as part of the model.
* 12 pages, 9 figures
GINopic: Topic Modeling with Graph Isomorphism Network
Apr 02, 2024



Topic modeling is a widely used approach for analyzing and exploring large document collections. Recent research efforts have incorporated pre-trained contextualized language models, such as BERT embeddings, into topic modeling. However, they often neglect the intrinsic informational value conveyed by mutual dependencies between words. In this study, we introduce GINopic, a topic modeling framework based on graph isomorphism networks to capture the correlation between words. By conducting intrinsic (quantitative as well as qualitative) and extrinsic evaluations on diverse benchmark datasets, we demonstrate the effectiveness of GINopic compared to existing topic models and highlight its potential for advancing topic modeling.
Hallucination Reduction in Long Input Text Summarization
Sep 28, 2023
Hallucination in text summarization refers to the phenomenon where the model generates information that is not supported by the input source document. Hallucination poses significant obstacles to the accuracy and reliability of the generated summaries. In this paper, we aim to reduce hallucinated outputs or hallucinations in summaries of long-form text documents. We have used the PubMed dataset, which contains long scientific research documents and their abstracts. We have incorporated the techniques of data filtering and joint entity and summary generation (JAENS) in the fine-tuning of the Longformer Encoder-Decoder (LED) model to minimize hallucinations and thereby improve the quality of the generated summary. We have used the following metrics to measure factual consistency at the entity level: precision-source, and F1-target. Our experiments show that the fine-tuned LED model performs well in generating the paper abstract. Data filtering techniques based on some preprocessing steps reduce entity-level hallucinations in the generated summaries in terms of some of the factual consistency metrics.
CitePrompt: Using Prompts to Identify Citation Intent in Scientific Papers
May 03, 2023Citations in scientific papers not only help us trace the intellectual lineage but also are a useful indicator of the scientific significance of the work. Citation intents prove beneficial as they specify the role of the citation in a given context. In this paper, we present CitePrompt, a framework which uses the hitherto unexplored approach of prompt-based learning for citation intent classification. We argue that with the proper choice of the pretrained language model, the prompt template, and the prompt verbalizer, we can not only get results that are better than or comparable to those obtained with the state-of-the-art methods but also do it with much less exterior information about the scientific document. We report state-of-the-art results on the ACL-ARC dataset, and also show significant improvement on the SciCite dataset over all baseline models except one. As suitably large labelled datasets for citation intent classification can be quite hard to find, in a first, we propose the conversion of this task to the few-shot and zero-shot settings. For the ACL-ARC dataset, we report a 53.86% F1 score for the zero-shot setting, which improves to 63.61% and 66.99% for the 5-shot and 10-shot settings, respectively.
What Does the Indian Parliament Discuss? An Exploratory Analysis of the Question Hour in the Lok Sabha
Apr 01, 2023



The TCPD-IPD dataset is a collection of questions and answers discussed in the Lower House of the Parliament of India during the Question Hour between 1999 and 2019. Although it is difficult to analyze such a huge collection manually, modern text analysis tools can provide a powerful means to navigate it. In this paper, we perform an exploratory analysis of the dataset. In particular, we present insightful corpus-level statistics and a detailed analysis of three subsets of the dataset. In the latter analysis, the focus is on understanding the temporal evolution of topics using a dynamic topic model. We observe that the parliamentary conversation indeed mirrors the political and socio-economic tensions of each period.