 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating LLMs and Pre-trained Models for Text Summarization Across Diverse Datasets
Feb 26, 2025Text summarization plays a crucial role in natural language processing by condensing large volumes of text into concise and coherent summaries. As digital content continues to grow rapidly and the demand for effective information retrieval increases, text summarization has become a focal point of research in recent years. This study offers a thorough evaluation of four leading pre-trained and open-source large language models: BART, FLAN-T5, LLaMA-3-8B, and Gemma-7B, across five diverse datasets CNN/DM, Gigaword, News Summary, XSum, and BBC News. The evaluation employs widely recognized automatic metrics, including ROUGE-1, ROUGE-2, ROUGE-L, BERTScore, and METEOR, to assess the models' capabilities in generating coherent and informative summaries. The results reveal the comparative strengths and limitations of these models in processing various text types.
How Green are Neural Language Models? Analyzing Energy Consumption in Text Summarization Fine-tuning
Jan 26, 2025



Artificial intelligence systems significantly impact the environment, particularly in natural language processing (NLP) tasks. These tasks often require extensive computational resources to train deep neural networks, including large-scale language models containing billions of parameters. This study analyzes the trade-offs between energy consumption and performance across three neural language models: two pre-trained models (T5-base and BART-base), and one large language model (LLaMA 3-8B). These models were fine-tuned for the text summarization task, focusing on generating research paper highlights that encapsulate the core themes of each paper. A wide range of evaluation metrics, including ROUGE, METEOR, MoverScore, BERTScore, and SciBERTScore, were employed to assess their performance. Furthermore, the carbon footprint associated with fine-tuning each model was measured, offering a comprehensive assessment of their environmental impact. This research underscores the importance of incorporating environmental considerations into the design and implementation of neural language models and calls for the advancement of energy-efficient AI methodologies.
Integrative CAM: Adaptive Layer Fusion for Comprehensive Interpretation of CNNs
Dec 02, 2024
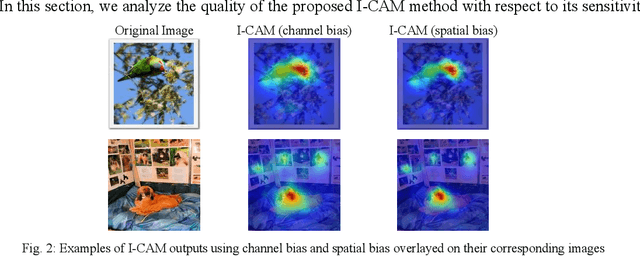
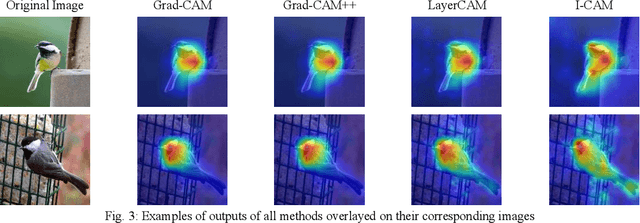

With the growing demand for interpretable deep learning models, this paper introduces Integrative CAM, an advanced Class Activation Mapping (CAM) technique aimed at providing a holistic view of feature importance across Convolutional Neural Networks (CNNs). Traditional gradient-based CAM methods, such as Grad-CAM and Grad-CAM++, primarily use final layer activations to highlight regions of interest, often neglecting critical features derived from intermediate layers. Integrative CAM addresses this limitation by fusing insights across all network layers, leveraging both gradient and activation scores to adaptively weight layer contributions, thus yielding a comprehensive interpretation of the model's internal representation. Our approach includes a novel bias term in the saliency map calculation, a factor frequently omitted in existing CAM techniques, but essential for capturing a more complete feature importance landscape, as modern CNNs rely on both weighted activations and biases to make predictions. Additionally, we generalize the alpha term from Grad-CAM++ to apply to any smooth function, expanding CAM applicability across a wider range of models. Through extensive experiments on diverse and complex datasets, Integrative CAM demonstrates superior fidelity in feature importance mapping, effectively enhancing interpretability for intricate fusion scenarios and complex decision-making tasks. By advancing interpretability methods to capture multi-layered model insights, Integrative CAM provides a valuable tool for fusion-driven applications, promoting the trustworthy and insightful deployment of deep learning models.
Can pre-trained language models generate titles for research papers?
Sep 22, 2024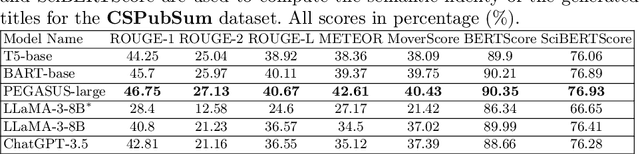



The title of a research paper communicates in a succinct style the main theme and, sometimes, the findings of the paper. Coming up with the right title is often an arduous task, and therefore, it would be beneficial to authors if title generation can be automated. In this paper, we fine-tune pre-trained and large language models to generate titles of papers from their abstracts. We also use ChatGPT in a zero-shot setting to generate paper titles. The performance of the models is measured with ROUGE, METEOR, MoverScore, BERTScore and SciBERTScore metrics.
Transfer Learning and Transformer Architecture for Financial Sentiment Analysis
Apr 28, 2024Financial sentiment analysis allows financial institutions like Banks and Insurance Companies to better manage the credit scoring of their customers in a better way. Financial domain uses specialized mechanisms which makes sentiment analysis difficult. In this paper, we propose a pre-trained language model which can help to solve this problem with fewer labelled data. We extend on the principles of Transfer learning and Transformation architecture principles and also take into consideration recent outbreak of pandemics like COVID. We apply the sentiment analysis to two different sets of data. We also take smaller training set and fine tune the same as part of the model.
* 12 pages, 9 figures
Analysis of Multidomain Abstractive Summarization Using Salience Allocation
Feb 19, 2024

This paper explores the realm of abstractive text summarization through the lens of the SEASON (Salience Allocation as Guidance for Abstractive SummarizatiON) technique, a model designed to enhance summarization by leveraging salience allocation techniques. The study evaluates SEASON's efficacy by comparing it with prominent models like BART, PEGASUS, and ProphetNet, all fine-tuned for various text summarization tasks. The assessment is conducted using diverse datasets including CNN/Dailymail, SAMSum, and Financial-news based Event-Driven Trading (EDT), with a specific focus on a financial dataset containing a substantial volume of news articles from 2020/03/01 to 2021/05/06. This paper employs various evaluation metrics such as ROUGE, METEOR, BERTScore, and MoverScore to evaluate the performance of these models fine-tuned for generating abstractive summaries. The analysis of these metrics offers a thorough insight into the strengths and weaknesses demonstrated by each model in summarizing news dataset, dialogue dataset and financial text dataset. The results presented in this paper not only contribute to the evaluation of the SEASON model's effectiveness but also illuminate the intricacies of salience allocation techniques across various types of datasets.
Generative AI for Software Metadata: Overview of the Information Retrieval in Software Engineering Track at FIRE 2023
Oct 27, 2023The Information Retrieval in Software Engineering (IRSE) track aims to develop solutions for automated evaluation of code comments in a machine learning framework based on human and large language model generated labels. In this track, there is a binary classification task to classify comments as useful and not useful. The dataset consists of 9048 code comments and surrounding code snippet pairs extracted from open source github C based projects and an additional dataset generated individually by teams using large language models. Overall 56 experiments have been submitted by 17 teams from various universities and software companies. The submissions have been evaluated quantitatively using the F1-Score and qualitatively based on the type of features developed, the supervised learning model used and their corresponding hyper-parameters. The labels generated from large language models increase the bias in the prediction model but lead to less over-fitted results.
An Evaluation of Non-Contrastive Self-Supervised Learning for Federated Medical Image Analysis
Mar 09, 2023



Privacy and annotation bottlenecks are two major issues that profoundly affect the practicality of machine learning-based medical image analysis. Although significant progress has been made in these areas, these issues are not yet fully resolved. In this paper, we seek to tackle these concerns head-on and systematically explore the applicability of non-contrastive self-supervised learning (SSL) algorithms under federated learning (FL) simulations for medical image analysis. We conduct thorough experimentation of recently proposed state-of-the-art non-contrastive frameworks under standard FL setups. With the SoTA Contrastive Learning algorithm, SimCLR as our comparative baseline, we benchmark the performances of our 4 chosen non-contrastive algorithms under non-i.i.d. data conditions and with a varying number of clients. We present a holistic evaluation of these techniques on 6 standardized medical imaging datasets. We further analyse different trends inferred from the findings of our research, with the aim to find directions for further research based on ours. To the best of our knowledge, ours is the first to perform such a thorough analysis of federated self-supervised learning for medical imaging. All of our source code will be made public upon acceptance of the paper.
Exploring Self-Supervised Representation Learning For Low-Resource Medical Image Analysis
Mar 03, 2023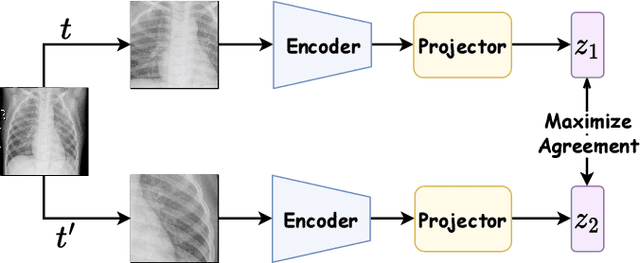
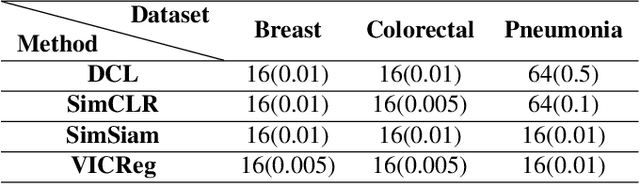
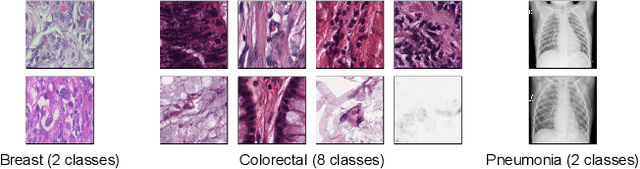
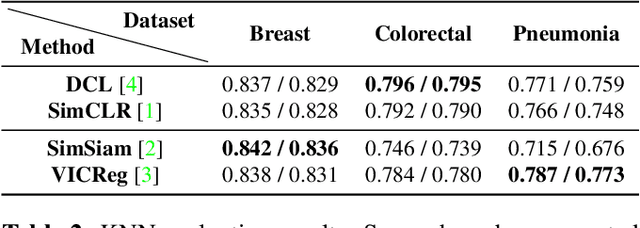
The success of self-supervised learning (SSL) has mostly been attributed to the availability of unlabeled yet large-scale datasets. However, in a specialized domain such as medical imaging which is a lot different from natural images, the assumption of data availability is unrealistic and impractical, as the data itself is scanty and found in small databases, collected for specific prognosis tasks. To this end, we seek to investigate the applicability of self-supervised learning algorithms on small-scale medical imaging datasets. In particular, we evaluate $4$ state-of-the-art SSL methods on three publicly accessible \emph{small} medical imaging datasets. Our investigation reveals that in-domain low-resource SSL pre-training can yield competitive performance to transfer learning from large-scale datasets (such as ImageNet). Furthermore, we extensively analyse our empirical findings to provide valuable insights that can motivate for further research towards circumventing the need for pre-training on a large image corpus. To the best of our knowledge, this is the first attempt to holistically explore self-supervision on low-resource medical datasets.
Abstractive Text Summarization using Attentive GRU based Encoder-Decoder
Feb 25, 2023In todays era huge volume of information exists everywhere. Therefore, it is very crucial to evaluate that information and extract useful, and often summarized, information out of it so that it may be used for relevant purposes. This extraction can be achieved through a crucial technique of artificial intelligence, namely, machine learning. Indeed automatic text summarization has emerged as an important application of machine learning in text processing. In this paper, an english text summarizer has been built with GRU-based encoder and decoder. Bahdanau attention mechanism has been added to overcome the problem of handling long sequences in the input text. A news-summary dataset has been used to train the model. The output is observed to outperform competitive models in the literature. The generated summary can be used as a newspaper headline.
* 9 pages, 2 Tables, 5 Figures