 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsID-Gen: View-Consistent and Identity-Preserving Image-to-Video Generation
Feb 10, 2026Image-to-Video generation (I2V) animates a static image into a temporally coherent video sequence following textual instructions, yet preserving fine-grained object identity under changing viewpoints remains a persistent challenge. Unlike text-to-video models, existing I2V pipelines often suffer from appearance drift and geometric distortion, artifacts we attribute to the sparsity of single-view 2D observations and weak cross-modal alignment. Here we address this problem from both data and model perspectives. First, we curate ConsIDVid, a large-scale object-centric dataset built with a scalable pipeline for high-quality, temporally aligned videos, and establish ConsIDVid-Bench, where we present a novel benchmarking and evaluation framework for multi-view consistency using metrics sensitive to subtle geometric and appearance deviations. We further propose ConsID-Gen, a view-assisted I2V generation framework that augments the first frame with unposed auxiliary views and fuses semantic and structural cues via a dual-stream visual-geometric encoder as well as a text-visual connector, yielding unified conditioning for a Diffusion Transformer backbone. Experiments across ConsIDVid-Bench demonstrate that ConsID-Gen consistently outperforms in multiple metrics, with the best overall performance surpassing leading video generation models like Wan2.1 and HunyuanVideo, delivering superior identity fidelity and temporal coherence under challenging real-world scenarios. We will release our model and dataset at https://myangwu.github.io/ConsID-Gen.
Batch Speculative Decoding Done Right
Oct 26, 2025



Speculative decoding speeds up LLM inference by using a small draft model to propose multiple tokens that a target model verifies in parallel. Extending this idea to batches is essential for production serving, but it introduces the ragged tensor problem: sequences in the same batch accept different numbers of draft tokens, breaking right-alignment and corrupting position IDs, attention masks, and KV-cache state. We show that several existing batch implementations violate output equivalence-the fundamental requirement that speculative decoding must produce identical token sequences to standard autoregressive generation. These violations occur precisely due to improper handling of the ragged tensor problem. In response, we (1) characterize the synchronization requirements that guarantee correctness, (2) present a correctness-first batch speculative decoding EQSPEC that exposes realignment as consuming 40% of overhead, and (3) introduce EXSPEC, which maintains a sliding pool of sequences and dynamically forms same-length groups, to reduce the realignment overhead while preserving per-sequence speculative speedups. On the SpecBench dataset, across Vicuna-7B/68M, Qwen3-8B/0.6B, and GLM-4-9B/0.6B target/draft pairs, our approach achieves up to 3$\times$ throughput improvement at batch size 8 compared to batch size 1, with efficient scaling through batch size 8, while maintaining 95% output equivalence. Our method requires no custom kernels and integrates cleanly with existing inference stacks. Our code is available at https://github.com/eBay/spec_dec.
BroadGen: A Framework for Generating Effective and Efficient Advertiser Broad Match Keyphrase Recommendations
May 25, 2025



In the domain of sponsored search advertising, the focus of Keyphrase recommendation has largely been on exact match types, which pose issues such as high management expenses, limited targeting scope, and evolving search query patterns. Alternatives like Broad match types can alleviate certain drawbacks of exact matches but present challenges like poor targeting accuracy and minimal supervisory signals owing to limited advertiser usage. This research defines the criteria for an ideal broad match, emphasizing on both efficiency and effectiveness, ensuring that a significant portion of matched queries are relevant. We propose BroadGen, an innovative framework that recommends efficient and effective broad match keyphrases by utilizing historical search query data. Additionally, we demonstrate that BroadGen, through token correspondence modeling, maintains better query stability over time. BroadGen's capabilities allow it to serve daily, millions of sellers at eBay with over 2.3 billion items.
To Judge or not to Judge: Using LLM Judgements for Advertiser Keyphrase Relevance at eBay
May 07, 2025



E-commerce sellers are recommended keyphrases based on their inventory on which they advertise to increase buyer engagement (clicks/sales). The relevance of advertiser keyphrases plays an important role in preventing the inundation of search systems with numerous irrelevant items that compete for attention in auctions, in addition to maintaining a healthy seller perception. In this work, we describe the shortcomings of training Advertiser keyphrase relevance filter models on click/sales/search relevance signals and the importance of aligning with human judgment, as sellers have the power to adopt or reject said keyphrase recommendations. In this study, we frame Advertiser keyphrase relevance as a complex interaction between 3 dynamical systems -- seller judgment, which influences seller adoption of our product, Advertising, which provides the keyphrases to bid on, and Search, who holds the auctions for the same keyphrases. This study discusses the practicalities of using human judgment via a case study at eBay Advertising and demonstrate that using LLM-as-a-judge en-masse as a scalable proxy for seller judgment to train our relevance models achieves a better harmony across the three systems -- provided that they are bound by a meticulous evaluation framework grounded in business metrics.
GraphEx: A Graph-based Extraction Method for Advertiser Keyphrase Recommendation
Sep 05, 2024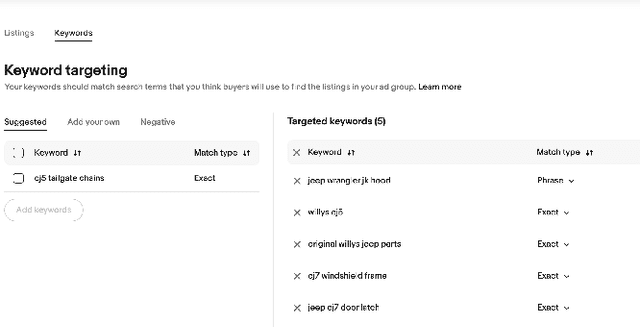
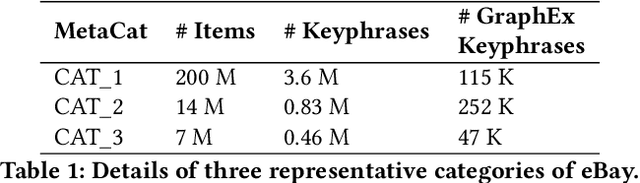
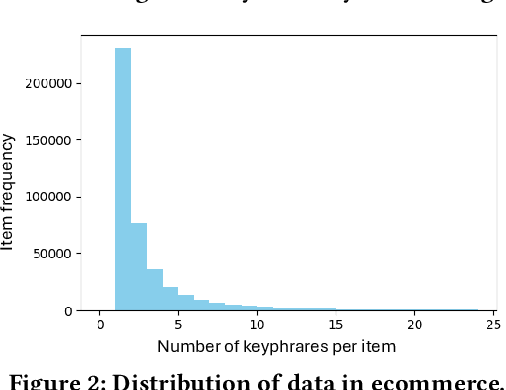
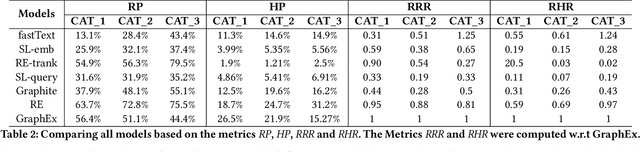
Online sellers and advertisers are recommended keyphrases for their listed products, which they bid on to enhance their sales. One popular paradigm that generates such recommendations is Extreme Multi-Label Classification (XMC), which involves tagging/mapping keyphrases to items. We outline the limitations of using traditional item-query based tagging or mapping techniques for keyphrase recommendations on E-Commerce platforms. We introduce GraphEx, an innovative graph-based approach that recommends keyphrases to sellers using extraction of token permutations from item titles. Additionally, we demonstrate that relying on traditional metrics such as precision/recall can be misleading in practical applications, thereby necessitating a combination of metrics to evaluate performance in real-world scenarios. These metrics are designed to assess the relevance of keyphrases to items and the potential for buyer outreach. GraphEx outperforms production models at eBay, achieving the objectives mentioned above. It supports near real-time inferencing in resource-constrained production environments and scales effectively for billions of items.
From Lazy to Prolific: Tackling Missing Labels in Open Vocabulary Extreme Classification by Positive-Unlabeled Sequence Learning
Aug 22, 2024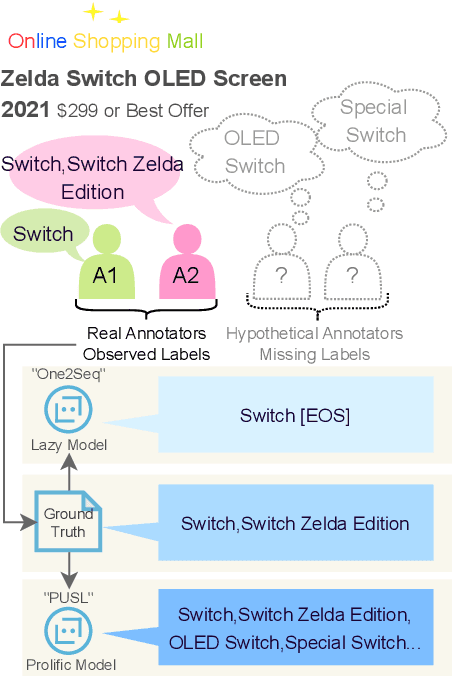
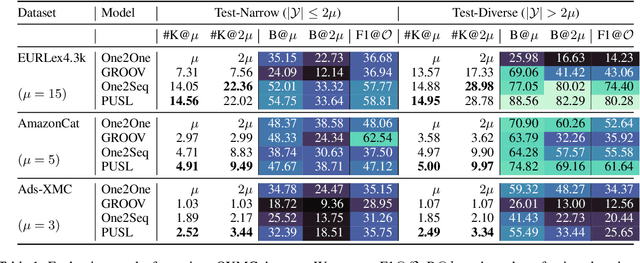
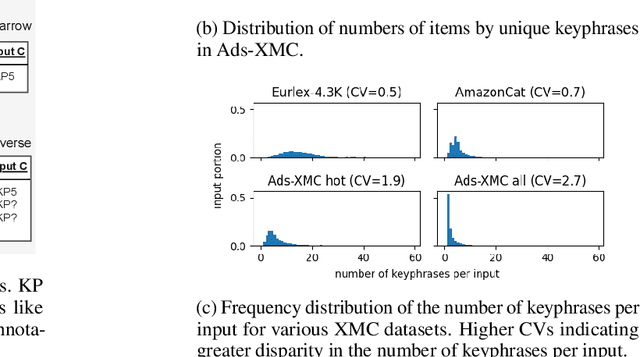
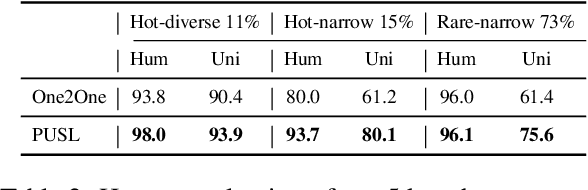
Open-vocabulary Extreme Multi-label Classification (OXMC) extends traditional XMC by allowing prediction beyond an extremely large, predefined label set (typically $10^3$ to $10^{12}$ labels), addressing the dynamic nature of real-world labeling tasks. However, self-selection bias in data annotation leads to significant missing labels in both training and test data, particularly for less popular inputs. This creates two critical challenges: generation models learn to be "lazy'" by under-generating labels, and evaluation becomes unreliable due to insufficient annotation in the test set. In this work, we introduce Positive-Unlabeled Sequence Learning (PUSL), which reframes OXMC as an infinite keyphrase generation task, addressing the generation model's laziness. Additionally, we propose to adopt a suite of evaluation metrics, F1@$\mathcal{O}$ and newly proposed B@$k$, to reliably assess OXMC models with incomplete ground truths. In a highly imbalanced e-commerce dataset with substantial missing labels, PUSL generates 30% more unique labels, and 72% of its predictions align with actual user queries. On the less skewed EURLex-4.3k dataset, PUSL demonstrates superior F1 scores, especially as label counts increase from 15 to 30. Our approach effectively tackles both the modeling and evaluation challenges in OXMC with missing labels.
GPT-3 Powered Information Extraction for Building Robust Knowledge Bases
Jul 31, 2024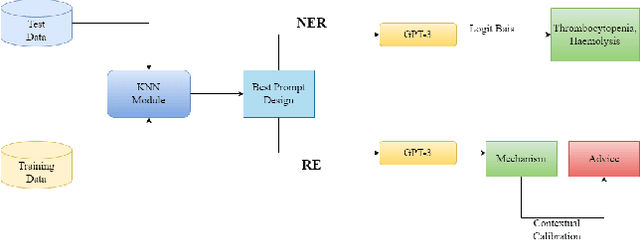
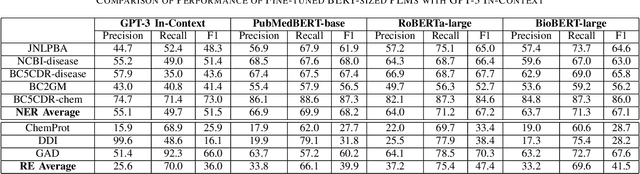
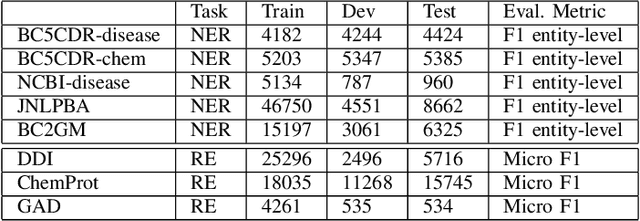
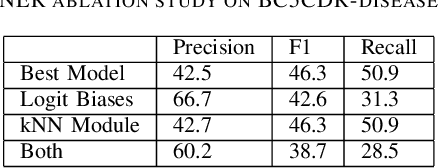
This work uses the state-of-the-art language model GPT-3 to offer a novel method of information extraction for knowledge base development. The suggested method attempts to solve the difficulties associated with obtaining relevant entities and relationships from unstructured text in order to extract structured information. We conduct experiments on a huge corpus of text from diverse fields to assess the performance of our suggested technique. The evaluation measures, which are frequently employed in information extraction tasks, include precision, recall, and F1-score. The findings demonstrate that GPT-3 can be used to efficiently and accurately extract pertinent and correct information from text, hence increasing the precision and productivity of knowledge base creation. We also assess how well our suggested approach performs in comparison to the most advanced information extraction techniques already in use. The findings show that by utilizing only a small number of instances in in-context learning, our suggested strategy yields competitive outcomes with notable savings in terms of data annotation and engineering expense. Additionally, we use our proposed method to retrieve Biomedical information, demonstrating its practicality in a real-world setting. All things considered, our suggested method offers a viable way to overcome the difficulties involved in obtaining structured data from unstructured text in order to create knowledge bases. It can greatly increase the precision and effectiveness of information extraction, which is necessary for many applications including chatbots, recommendation engines, and question-answering systems.
Graphite: A Graph-based Extreme Multi-Label Short Text Classifier for Keyphrase Recommendation
Jul 29, 2024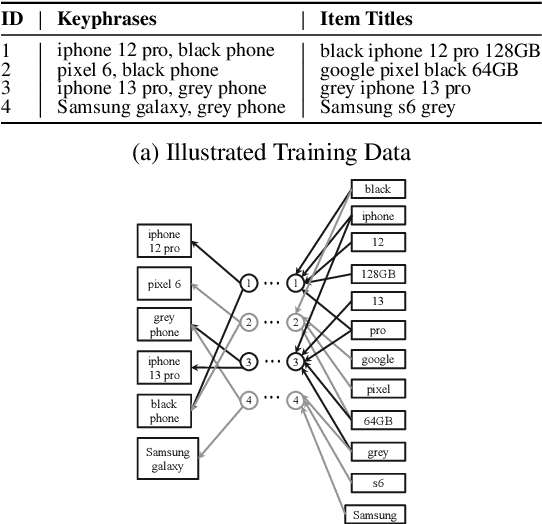
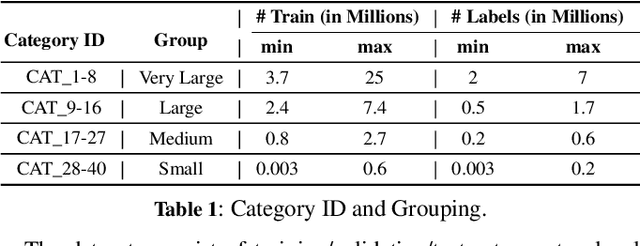
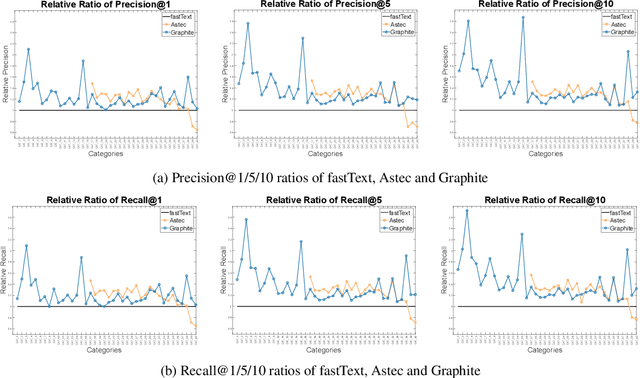
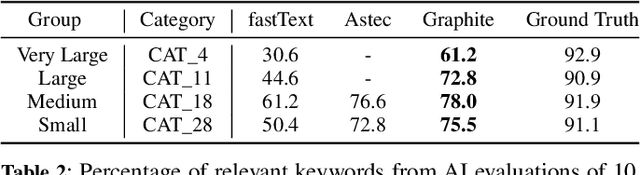
Keyphrase Recommendation has been a pivotal problem in advertising and e-commerce where advertisers/sellers are recommended keyphrases (search queries) to bid on to increase their sales. It is a challenging task due to the plethora of items shown on online platforms and various possible queries that users search while showing varying interest in the displayed items. Moreover, query/keyphrase recommendations need to be made in real-time and in a resource-constrained environment. This problem can be framed as an Extreme Multi-label (XML) Short text classification by tagging the input text with keywords as labels. Traditional neural network models are either infeasible or have slower inference latency due to large label spaces. We present Graphite, a graph-based classifier model that provides real-time keyphrase recommendations that are on par with standard text classification models. Furthermore, it doesn't utilize GPU resources, which can be limited in production environments. Due to its lightweight nature and smaller footprint, it can train on very large datasets, where state-of-the-art XML models fail due to extreme resource requirements. Graphite is deterministic, transparent, and intrinsically more interpretable than neural network-based models. We present a comprehensive analysis of our model's performance across forty categories spanning eBay's English-speaking sites.
Analysis of Multidomain Abstractive Summarization Using Salience Allocation
Feb 19, 2024

This paper explores the realm of abstractive text summarization through the lens of the SEASON (Salience Allocation as Guidance for Abstractive SummarizatiON) technique, a model designed to enhance summarization by leveraging salience allocation techniques. The study evaluates SEASON's efficacy by comparing it with prominent models like BART, PEGASUS, and ProphetNet, all fine-tuned for various text summarization tasks. The assessment is conducted using diverse datasets including CNN/Dailymail, SAMSum, and Financial-news based Event-Driven Trading (EDT), with a specific focus on a financial dataset containing a substantial volume of news articles from 2020/03/01 to 2021/05/06. This paper employs various evaluation metrics such as ROUGE, METEOR, BERTScore, and MoverScore to evaluate the performance of these models fine-tuned for generating abstractive summaries. The analysis of these metrics offers a thorough insight into the strengths and weaknesses demonstrated by each model in summarizing news dataset, dialogue dataset and financial text dataset. The results presented in this paper not only contribute to the evaluation of the SEASON model's effectiveness but also illuminate the intricacies of salience allocation techniques across various types of datasets.