 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCM-Bench: A Comprehensive Cross-Modal Feature Matching Benchmark Bridging Visible and Infrared Images
Mar 13, 2026Infrared-visible (IR-VIS) feature matching plays an essential role in cross-modality visual localization, navigation and perception. Along with the rapid development of deep learning techniques, a number of representative image matching methods have been proposed. However, crossmodal feature matching is still a challenging task due to the significant appearance difference. A significant gap for cross-modal feature matching research lies in the absence of standardized benchmarks and metrics for evaluations. In this paper, we introduce a comprehensive cross-modal feature matching benchmark, CM-Bench, which encompasses 30 feature matching algorithms across diverse cross-modal datasets. Specifically, state-of-the-art traditional and deep learning-based methods are first summarized and categorized into sparse, semidense, and dense methods. These methods are evaluated by different tasks including homography estimation, relative pose estimation, and feature-matching-based geo-localization. In addition, we introduce a classification-network-based adaptive preprocessing front-end that automatically selects suitable enhancement strategies before matching. We also present a novel infrared-satellite cross-modal dataset with manually annotated ground-truth correspondences for practical geo-localization evaluation. The dataset and resource will be available at: https://github.com/SLZ98/CM-Bench.
ConsID-Gen: View-Consistent and Identity-Preserving Image-to-Video Generation
Feb 10, 2026Image-to-Video generation (I2V) animates a static image into a temporally coherent video sequence following textual instructions, yet preserving fine-grained object identity under changing viewpoints remains a persistent challenge. Unlike text-to-video models, existing I2V pipelines often suffer from appearance drift and geometric distortion, artifacts we attribute to the sparsity of single-view 2D observations and weak cross-modal alignment. Here we address this problem from both data and model perspectives. First, we curate ConsIDVid, a large-scale object-centric dataset built with a scalable pipeline for high-quality, temporally aligned videos, and establish ConsIDVid-Bench, where we present a novel benchmarking and evaluation framework for multi-view consistency using metrics sensitive to subtle geometric and appearance deviations. We further propose ConsID-Gen, a view-assisted I2V generation framework that augments the first frame with unposed auxiliary views and fuses semantic and structural cues via a dual-stream visual-geometric encoder as well as a text-visual connector, yielding unified conditioning for a Diffusion Transformer backbone. Experiments across ConsIDVid-Bench demonstrate that ConsID-Gen consistently outperforms in multiple metrics, with the best overall performance surpassing leading video generation models like Wan2.1 and HunyuanVideo, delivering superior identity fidelity and temporal coherence under challenging real-world scenarios. We will release our model and dataset at https://myangwu.github.io/ConsID-Gen.
Batch Speculative Decoding Done Right
Oct 26, 2025



Speculative decoding speeds up LLM inference by using a small draft model to propose multiple tokens that a target model verifies in parallel. Extending this idea to batches is essential for production serving, but it introduces the ragged tensor problem: sequences in the same batch accept different numbers of draft tokens, breaking right-alignment and corrupting position IDs, attention masks, and KV-cache state. We show that several existing batch implementations violate output equivalence-the fundamental requirement that speculative decoding must produce identical token sequences to standard autoregressive generation. These violations occur precisely due to improper handling of the ragged tensor problem. In response, we (1) characterize the synchronization requirements that guarantee correctness, (2) present a correctness-first batch speculative decoding EQSPEC that exposes realignment as consuming 40% of overhead, and (3) introduce EXSPEC, which maintains a sliding pool of sequences and dynamically forms same-length groups, to reduce the realignment overhead while preserving per-sequence speculative speedups. On the SpecBench dataset, across Vicuna-7B/68M, Qwen3-8B/0.6B, and GLM-4-9B/0.6B target/draft pairs, our approach achieves up to 3$\times$ throughput improvement at batch size 8 compared to batch size 1, with efficient scaling through batch size 8, while maintaining 95% output equivalence. Our method requires no custom kernels and integrates cleanly with existing inference stacks. Our code is available at https://github.com/eBay/spec_dec.
Uni-DocDiff: A Unified Document Restoration Model Based on Diffusion
Aug 06, 2025Removing various degradations from damaged documents greatly benefits digitization, downstream document analysis, and readability. Previous methods often treat each restoration task independently with dedicated models, leading to a cumbersome and highly complex document processing system. Although recent studies attempt to unify multiple tasks, they often suffer from limited scalability due to handcrafted prompts and heavy preprocessing, and fail to fully exploit inter-task synergy within a shared architecture. To address the aforementioned challenges, we propose Uni-DocDiff, a Unified and highly scalable Document restoration model based on Diffusion. Uni-DocDiff develops a learnable task prompt design, ensuring exceptional scalability across diverse tasks. To further enhance its multi-task capabilities and address potential task interference, we devise a novel \textbf{Prior \textbf{P}ool}, a simple yet comprehensive mechanism that combines both local high-frequency features and global low-frequency features. Additionally, we design the \textbf{Prior \textbf{F}usion \textbf{M}odule (PFM)}, which enables the model to adaptively select the most relevant prior information for each specific task. Extensive experiments show that the versatile Uni-DocDiff achieves performance comparable or even superior performance compared with task-specific expert models, and simultaneously holds the task scalability for seamless adaptation to new tasks.
Gather and Trace: Rethinking Video TextVQA from an Instance-oriented Perspective
Aug 06, 2025Video text-based visual question answering (Video TextVQA) aims to answer questions by explicitly reading and reasoning about the text involved in a video. Most works in this field follow a frame-level framework which suffers from redundant text entities and implicit relation modeling, resulting in limitations in both accuracy and efficiency. In this paper, we rethink the Video TextVQA task from an instance-oriented perspective and propose a novel model termed GAT (Gather and Trace). First, to obtain accurate reading result for each video text instance, a context-aggregated instance gathering module is designed to integrate the visual appearance, layout characteristics, and textual contents of the related entities into a unified textual representation. Then, to capture dynamic evolution of text in the video flow, an instance-focused trajectory tracing module is utilized to establish spatio-temporal relationships between instances and infer the final answer. Extensive experiments on several public Video TextVQA datasets validate the effectiveness and generalization of our framework. GAT outperforms existing Video TextVQA methods, video-language pretraining methods, and video large language models in both accuracy and inference speed. Notably, GAT surpasses the previous state-of-the-art Video TextVQA methods by 3.86\% in accuracy and achieves ten times of faster inference speed than video large language models. The source code is available at https://github.com/zhangyan-ucas/GAT.
BroadGen: A Framework for Generating Effective and Efficient Advertiser Broad Match Keyphrase Recommendations
May 25, 2025



In the domain of sponsored search advertising, the focus of Keyphrase recommendation has largely been on exact match types, which pose issues such as high management expenses, limited targeting scope, and evolving search query patterns. Alternatives like Broad match types can alleviate certain drawbacks of exact matches but present challenges like poor targeting accuracy and minimal supervisory signals owing to limited advertiser usage. This research defines the criteria for an ideal broad match, emphasizing on both efficiency and effectiveness, ensuring that a significant portion of matched queries are relevant. We propose BroadGen, an innovative framework that recommends efficient and effective broad match keyphrases by utilizing historical search query data. Additionally, we demonstrate that BroadGen, through token correspondence modeling, maintains better query stability over time. BroadGen's capabilities allow it to serve daily, millions of sellers at eBay with over 2.3 billion items.
To Judge or not to Judge: Using LLM Judgements for Advertiser Keyphrase Relevance at eBay
May 07, 2025



E-commerce sellers are recommended keyphrases based on their inventory on which they advertise to increase buyer engagement (clicks/sales). The relevance of advertiser keyphrases plays an important role in preventing the inundation of search systems with numerous irrelevant items that compete for attention in auctions, in addition to maintaining a healthy seller perception. In this work, we describe the shortcomings of training Advertiser keyphrase relevance filter models on click/sales/search relevance signals and the importance of aligning with human judgment, as sellers have the power to adopt or reject said keyphrase recommendations. In this study, we frame Advertiser keyphrase relevance as a complex interaction between 3 dynamical systems -- seller judgment, which influences seller adoption of our product, Advertising, which provides the keyphrases to bid on, and Search, who holds the auctions for the same keyphrases. This study discusses the practicalities of using human judgment via a case study at eBay Advertising and demonstrate that using LLM-as-a-judge en-masse as a scalable proxy for seller judgment to train our relevance models achieves a better harmony across the three systems -- provided that they are bound by a meticulous evaluation framework grounded in business metrics.
GraphEx: A Graph-based Extraction Method for Advertiser Keyphrase Recommendation
Sep 05, 2024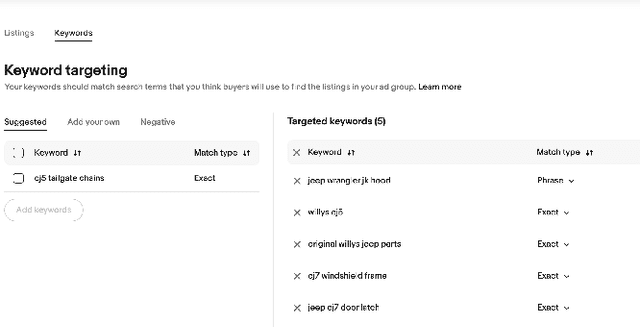
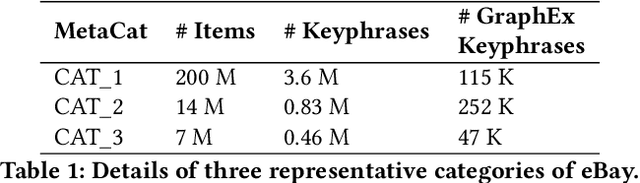
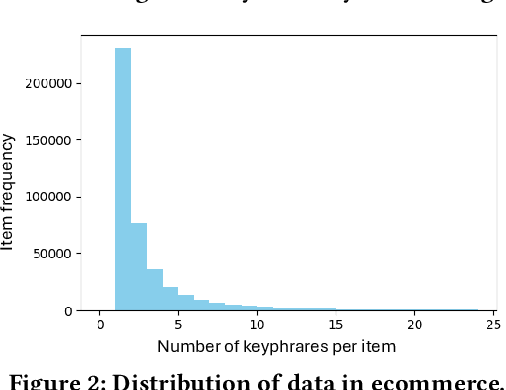
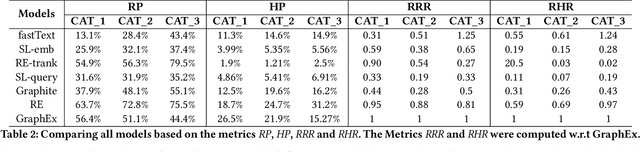
Online sellers and advertisers are recommended keyphrases for their listed products, which they bid on to enhance their sales. One popular paradigm that generates such recommendations is Extreme Multi-Label Classification (XMC), which involves tagging/mapping keyphrases to items. We outline the limitations of using traditional item-query based tagging or mapping techniques for keyphrase recommendations on E-Commerce platforms. We introduce GraphEx, an innovative graph-based approach that recommends keyphrases to sellers using extraction of token permutations from item titles. Additionally, we demonstrate that relying on traditional metrics such as precision/recall can be misleading in practical applications, thereby necessitating a combination of metrics to evaluate performance in real-world scenarios. These metrics are designed to assess the relevance of keyphrases to items and the potential for buyer outreach. GraphEx outperforms production models at eBay, achieving the objectives mentioned above. It supports near real-time inferencing in resource-constrained production environments and scales effectively for billions of items.
From Lazy to Prolific: Tackling Missing Labels in Open Vocabulary Extreme Classification by Positive-Unlabeled Sequence Learning
Aug 22, 2024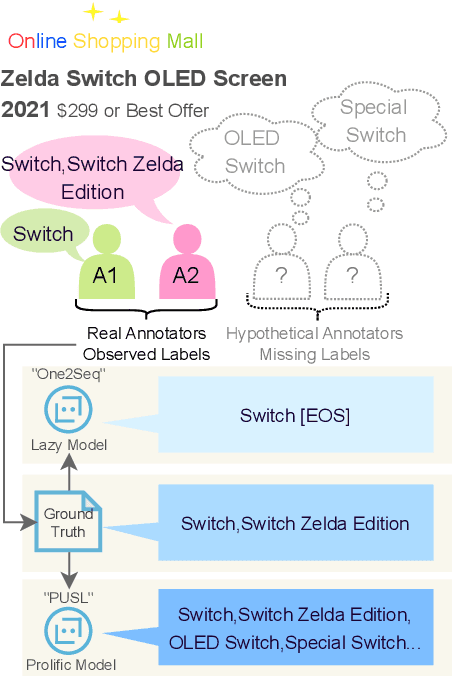
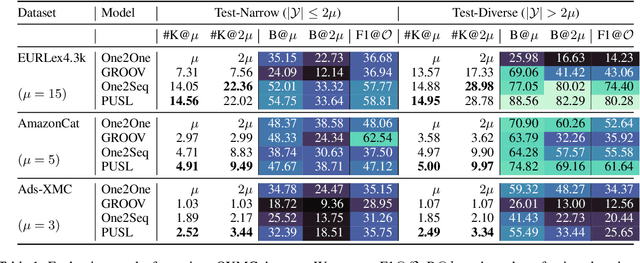
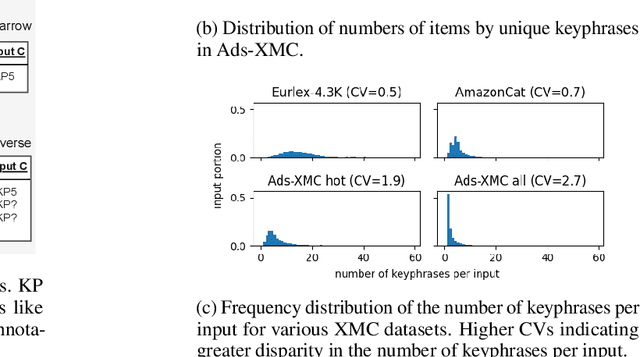
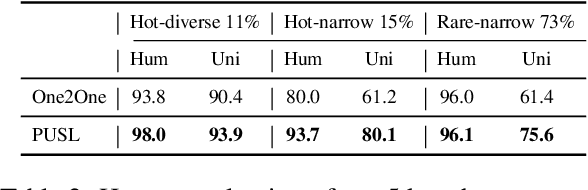
Open-vocabulary Extreme Multi-label Classification (OXMC) extends traditional XMC by allowing prediction beyond an extremely large, predefined label set (typically $10^3$ to $10^{12}$ labels), addressing the dynamic nature of real-world labeling tasks. However, self-selection bias in data annotation leads to significant missing labels in both training and test data, particularly for less popular inputs. This creates two critical challenges: generation models learn to be "lazy'" by under-generating labels, and evaluation becomes unreliable due to insufficient annotation in the test set. In this work, we introduce Positive-Unlabeled Sequence Learning (PUSL), which reframes OXMC as an infinite keyphrase generation task, addressing the generation model's laziness. Additionally, we propose to adopt a suite of evaluation metrics, F1@$\mathcal{O}$ and newly proposed B@$k$, to reliably assess OXMC models with incomplete ground truths. In a highly imbalanced e-commerce dataset with substantial missing labels, PUSL generates 30% more unique labels, and 72% of its predictions align with actual user queries. On the less skewed EURLex-4.3k dataset, PUSL demonstrates superior F1 scores, especially as label counts increase from 15 to 30. Our approach effectively tackles both the modeling and evaluation challenges in OXMC with missing labels.
Graphite: A Graph-based Extreme Multi-Label Short Text Classifier for Keyphrase Recommendation
Jul 29, 2024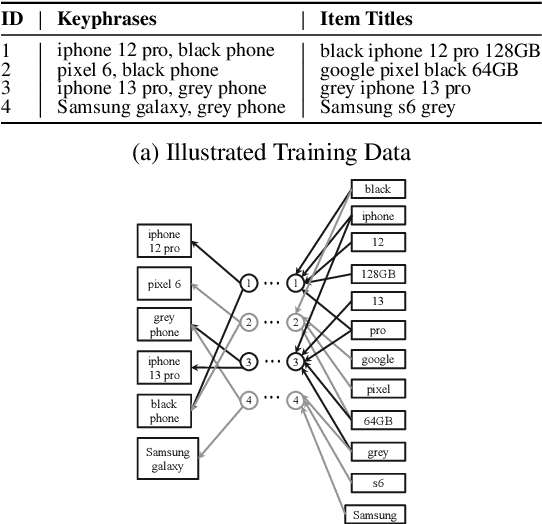
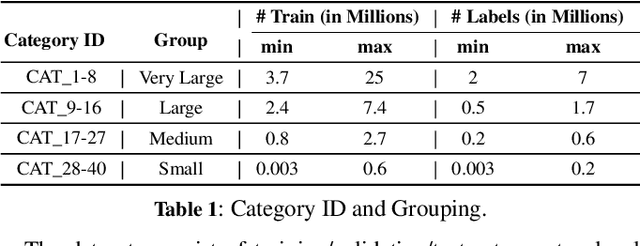
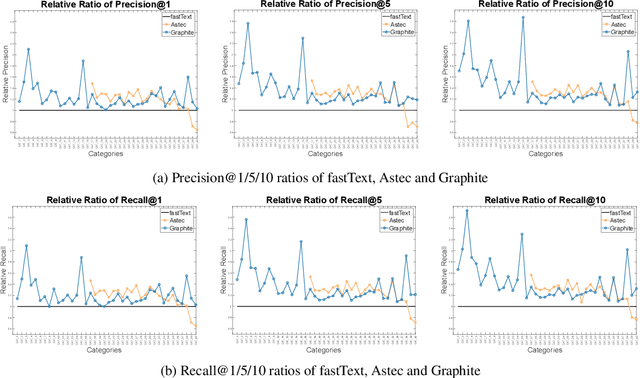
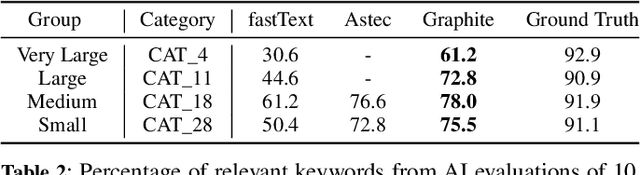
Keyphrase Recommendation has been a pivotal problem in advertising and e-commerce where advertisers/sellers are recommended keyphrases (search queries) to bid on to increase their sales. It is a challenging task due to the plethora of items shown on online platforms and various possible queries that users search while showing varying interest in the displayed items. Moreover, query/keyphrase recommendations need to be made in real-time and in a resource-constrained environment. This problem can be framed as an Extreme Multi-label (XML) Short text classification by tagging the input text with keywords as labels. Traditional neural network models are either infeasible or have slower inference latency due to large label spaces. We present Graphite, a graph-based classifier model that provides real-time keyphrase recommendations that are on par with standard text classification models. Furthermore, it doesn't utilize GPU resources, which can be limited in production environments. Due to its lightweight nature and smaller footprint, it can train on very large datasets, where state-of-the-art XML models fail due to extreme resource requirements. Graphite is deterministic, transparent, and intrinsically more interpretable than neural network-based models. We present a comprehensive analysis of our model's performance across forty categories spanning eBay's English-speaking sites.