 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Speculative Decoding Done Right
Oct 26, 2025



Speculative decoding speeds up LLM inference by using a small draft model to propose multiple tokens that a target model verifies in parallel. Extending this idea to batches is essential for production serving, but it introduces the ragged tensor problem: sequences in the same batch accept different numbers of draft tokens, breaking right-alignment and corrupting position IDs, attention masks, and KV-cache state. We show that several existing batch implementations violate output equivalence-the fundamental requirement that speculative decoding must produce identical token sequences to standard autoregressive generation. These violations occur precisely due to improper handling of the ragged tensor problem. In response, we (1) characterize the synchronization requirements that guarantee correctness, (2) present a correctness-first batch speculative decoding EQSPEC that exposes realignment as consuming 40% of overhead, and (3) introduce EXSPEC, which maintains a sliding pool of sequences and dynamically forms same-length groups, to reduce the realignment overhead while preserving per-sequence speculative speedups. On the SpecBench dataset, across Vicuna-7B/68M, Qwen3-8B/0.6B, and GLM-4-9B/0.6B target/draft pairs, our approach achieves up to 3$\times$ throughput improvement at batch size 8 compared to batch size 1, with efficient scaling through batch size 8, while maintaining 95% output equivalence. Our method requires no custom kernels and integrates cleanly with existing inference stacks. Our code is available at https://github.com/eBay/spec_dec.
Enhance Multimodal Consistency and Coherence for Text-Image Plan Generation
Jun 13, 2025People get informed of a daily task plan through diverse media involving both texts and images. However, most prior research only focuses on LLM's capability of textual plan generation. The potential of large-scale models in providing text-image plans remains understudied. Generating high-quality text-image plans faces two main challenges: ensuring consistent alignment between two modalities and keeping coherence among visual steps. To address these challenges, we propose a novel framework that generates and refines text-image plans step-by-step. At each iteration, our framework (1) drafts the next textual step based on the prediction history; (2) edits the last visual step to obtain the next one; (3) extracts PDDL-like visual information; and (4) refines the draft with the extracted visual information. The textual and visual step produced in stage (4) and (2) will then serve as inputs for the next iteration. Our approach offers a plug-and-play improvement to various backbone models, such as Mistral-7B, Gemini-1.5, and GPT-4o. To evaluate the effectiveness of our approach, we collect a new benchmark consisting of 1,100 tasks and their text-image pair solutions covering 11 daily topics. We also design and validate a new set of metrics to evaluate the multimodal consistency and coherence in text-image plans. Extensive experiment results show the effectiveness of our approach on a range of backbone models against competitive baselines. Our code and data are available at https://github.com/psunlpgroup/MPlanner.
HRScene: How Far Are VLMs from Effective High-Resolution Image Understanding?
Apr 29, 2025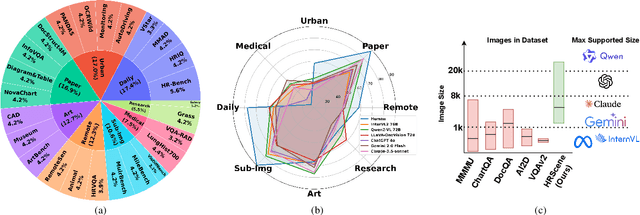
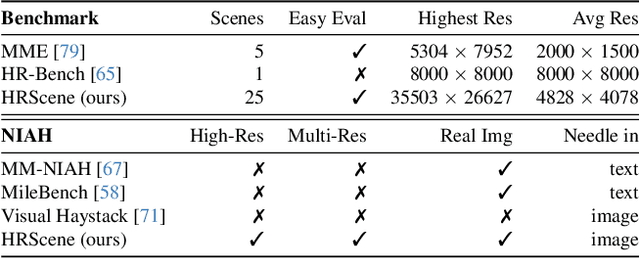
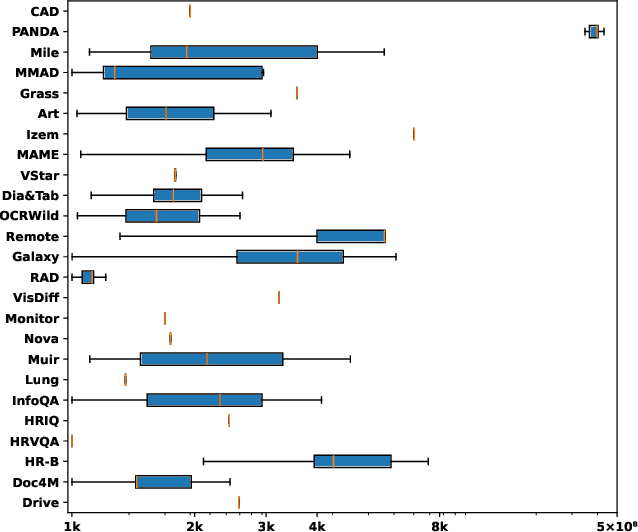
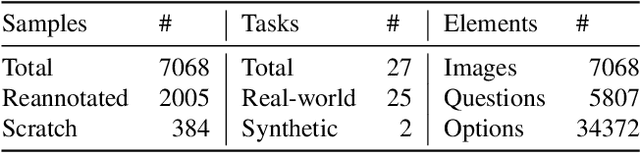
High-resolution image (HRI) understanding aims to process images with a large number of pixels, such as pathological images and agricultural aerial images, both of which can exceed 1 million pixels. Vision Large Language Models (VLMs) can allegedly handle HRIs, however, there is a lack of a comprehensive benchmark for VLMs to evaluate HRI understanding. To address this gap, we introduce HRScene, a novel unified benchmark for HRI understanding with rich scenes. HRScene incorporates 25 real-world datasets and 2 synthetic diagnostic datasets with resolutions ranging from 1,024 $\times$ 1,024 to 35,503 $\times$ 26,627. HRScene is collected and re-annotated by 10 graduate-level annotators, covering 25 scenarios, ranging from microscopic to radiology images, street views, long-range pictures, and telescope images. It includes HRIs of real-world objects, scanned documents, and composite multi-image. The two diagnostic evaluation datasets are synthesized by combining the target image with the gold answer and distracting images in different orders, assessing how well models utilize regions in HRI. We conduct extensive experiments involving 28 VLMs, including Gemini 2.0 Flash and GPT-4o. Experiments on HRScene show that current VLMs achieve an average accuracy of around 50% on real-world tasks, revealing significant gaps in HRI understanding. Results on synthetic datasets reveal that VLMs struggle to effectively utilize HRI regions, showing significant Regional Divergence and lost-in-middle, shedding light on future research.
VisOnlyQA: Large Vision Language Models Still Struggle with Visual Perception of Geometric Information
Dec 01, 2024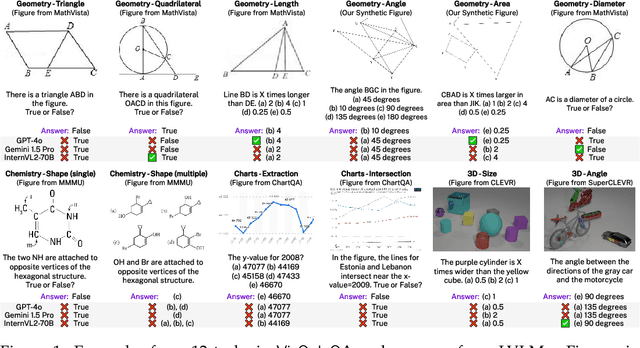

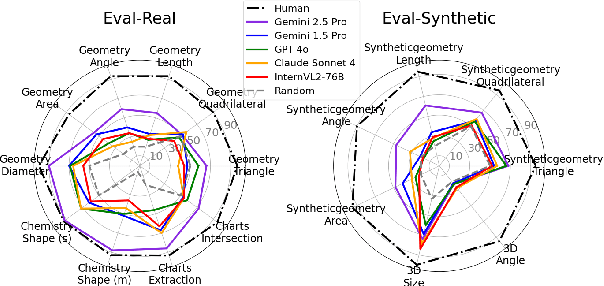
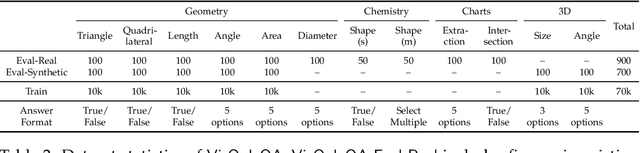
Errors in understanding visual information in images (i.e., visual perception errors) remain a major source of mistakes in Large Vision Language Models (LVLMs). While further analysis is essential, there is a deficiency in datasets for evaluating the visual perception of LVLMs. In this work, we introduce VisOnlyQA, a new dataset designed to directly evaluate the visual perception capabilities of LVLMs on questions about geometric and numerical information in scientific figures. Our dataset enables us to analyze the visual perception of LVLMs for fine-grained visual information, independent of other capabilities such as reasoning. The evaluation set of VisOnlyQA includes 1,200 multiple-choice questions in 12 tasks on four categories of figures. We also provide synthetic training data consisting of 70k instances. Our experiments on VisOnlyQA highlight the following findings: (i) 20 LVLMs we evaluate, including GPT-4o and Gemini 1.5 Pro, work poorly on the visual perception tasks in VisOnlyQA, while human performance is nearly perfect. (ii) Fine-tuning on synthetic training data demonstrates the potential for enhancing the visual perception of LVLMs, but observed improvements are limited to certain tasks and specific models. (iii) Stronger language models improve the visual perception of LVLMs. In summary, our experiments suggest that both training data and model architectures should be improved to enhance the visual perception capabilities of LVLMs. The datasets, code, and model responses are provided at https://github.com/psunlpgroup/VisOnlyQA.
From Lazy to Prolific: Tackling Missing Labels in Open Vocabulary Extreme Classification by Positive-Unlabeled Sequence Learning
Aug 22, 2024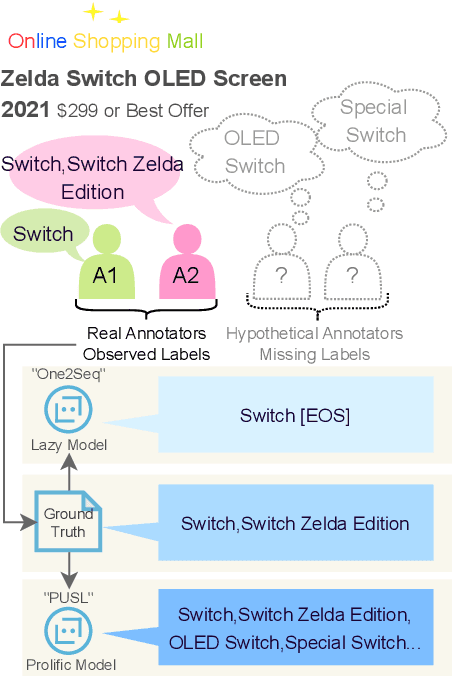
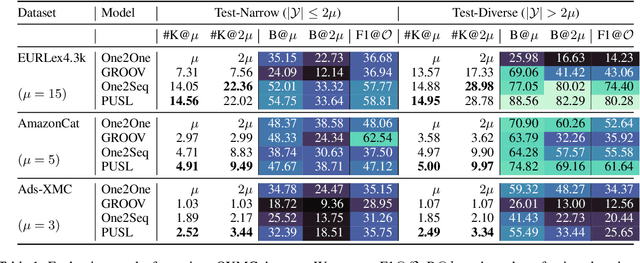
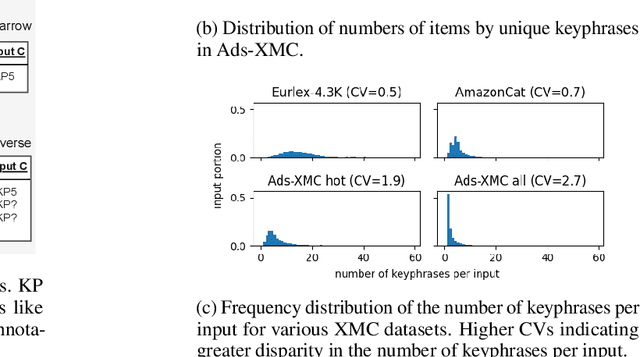
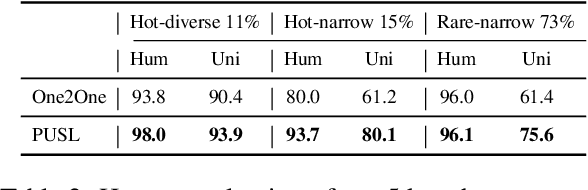
Open-vocabulary Extreme Multi-label Classification (OXMC) extends traditional XMC by allowing prediction beyond an extremely large, predefined label set (typically $10^3$ to $10^{12}$ labels), addressing the dynamic nature of real-world labeling tasks. However, self-selection bias in data annotation leads to significant missing labels in both training and test data, particularly for less popular inputs. This creates two critical challenges: generation models learn to be "lazy'" by under-generating labels, and evaluation becomes unreliable due to insufficient annotation in the test set. In this work, we introduce Positive-Unlabeled Sequence Learning (PUSL), which reframes OXMC as an infinite keyphrase generation task, addressing the generation model's laziness. Additionally, we propose to adopt a suite of evaluation metrics, F1@$\mathcal{O}$ and newly proposed B@$k$, to reliably assess OXMC models with incomplete ground truths. In a highly imbalanced e-commerce dataset with substantial missing labels, PUSL generates 30% more unique labels, and 72% of its predictions align with actual user queries. On the less skewed EURLex-4.3k dataset, PUSL demonstrates superior F1 scores, especially as label counts increase from 15 to 30. Our approach effectively tackles both the modeling and evaluation challenges in OXMC with missing labels.
Evaluating LLMs at Detecting Errors in LLM Responses
Apr 04, 2024



With Large Language Models (LLMs) being widely used across various tasks, detecting errors in their responses is increasingly crucial. However, little research has been conducted on error detection of LLM responses. Collecting error annotations on LLM responses is challenging due to the subjective nature of many NLP tasks, and thus previous research focuses on tasks of little practical value (e.g., word sorting) or limited error types (e.g., faithfulness in summarization). This work introduces ReaLMistake, the first error detection benchmark consisting of objective, realistic, and diverse errors made by LLMs. ReaLMistake contains three challenging and meaningful tasks that introduce objectively assessable errors in four categories (reasoning correctness, instruction-following, context-faithfulness, and parameterized knowledge), eliciting naturally observed and diverse errors in responses of GPT-4 and Llama 2 70B annotated by experts. We use ReaLMistake to evaluate error detectors based on 12 LLMs. Our findings show: 1) Top LLMs like GPT-4 and Claude 3 detect errors made by LLMs at very low recall, and all LLM-based error detectors perform much worse than humans. 2) Explanations by LLM-based error detectors lack reliability. 3) LLMs-based error detection is sensitive to small changes in prompts but remains challenging to improve. 4) Popular approaches to improving LLMs, including self-consistency and majority vote, do not improve the error detection performance. Our benchmark and code are provided at https://github.com/psunlpgroup/ReaLMistake.
Unified Low-Resource Sequence Labeling by Sample-Aware Dynamic Sparse Finetuning
Nov 07, 2023



Unified Sequence Labeling that articulates different sequence labeling problems such as Named Entity Recognition, Relation Extraction, Semantic Role Labeling, etc. in a generalized sequence-to-sequence format opens up the opportunity to make the maximum utilization of large language model knowledge toward structured prediction. Unfortunately, this requires formatting them into specialized augmented format unknown to the base pretrained language model (PLMs) necessitating finetuning to the target format. This significantly bounds its usefulness in data-limited settings where finetuning large models cannot properly generalize to the target format. To address this challenge and leverage PLM knowledge effectively, we propose FISH-DIP, a sample-aware dynamic sparse finetuning strategy that selectively focuses on a fraction of parameters, informed by feedback from highly regressing examples, during the fine-tuning process. By leveraging the dynamism of sparsity, our approach mitigates the impact of well-learned samples and prioritizes underperforming instances for improvement in generalization. Across five tasks of sequence labeling, we demonstrate that FISH-DIP can smoothly optimize the model in low resource settings offering upto 40% performance improvements over full fine-tuning depending on target evaluation settings. Also, compared to in-context learning and other parameter-efficient fine-tuning approaches, FISH-DIP performs comparably or better, notably in extreme low-resource settings.
Exploring the Potential of Large Language Models in Generating Code-Tracing Questions for Introductory Programming Courses
Oct 23, 2023



In this paper, we explore the application of large language models (LLMs) for generating code-tracing questions in introductory programming courses. We designed targeted prompts for GPT4, guiding it to generate code-tracing questions based on code snippets and descriptions. We established a set of human evaluation metrics to assess the quality of questions produced by the model compared to those created by human experts. Our analysis provides insights into the capabilities and potential of LLMs in generating diverse code-tracing questions. Additionally, we present a unique dataset of human and LLM-generated tracing questions, serving as a valuable resource for both the education and NLP research communities. This work contributes to the ongoing dialogue on the potential uses of LLMs in educational settings.
Minimize Exposure Bias of Seq2Seq Models in Joint Entity and Relation Extraction
Oct 06, 2020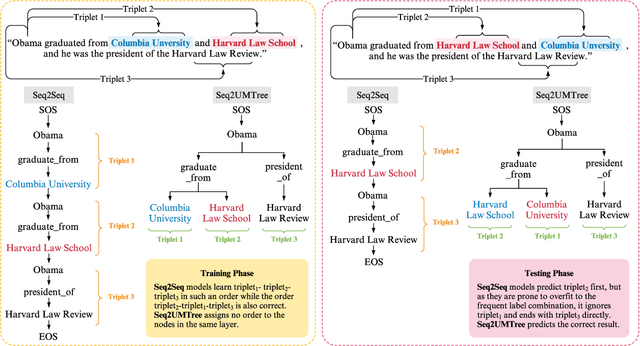
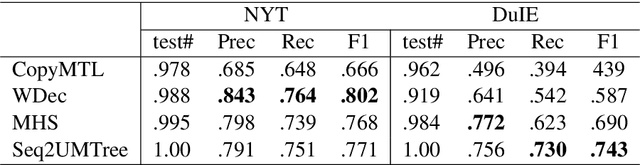
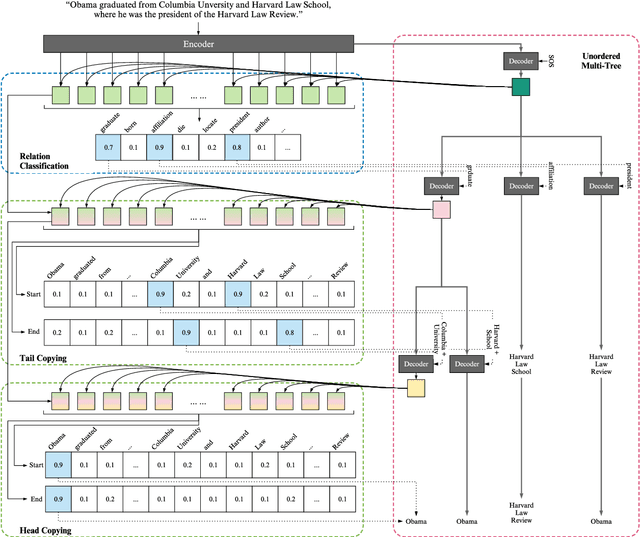
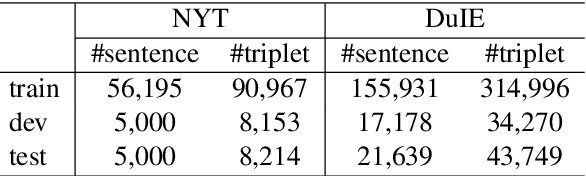
Joint entity and relation extraction aims to extract relation triplets from plain text directly. Prior work leverages Sequence-to-Sequence (Seq2Seq) models for triplet sequence generation. However, Seq2Seq enforces an unnecessary order on the unordered triplets and involves a large decoding length associated with error accumulation. These introduce exposure bias, which may cause the models overfit to the frequent label combination, thus deteriorating the generalization. We propose a novel Sequence-to-Unordered-Multi-Tree (Seq2UMTree) model to minimize the effects of exposure bias by limiting the decoding length to three within a triplet and removing the order among triplets. We evaluate our model on two datasets, DuIE and NYT, and systematically study how exposure bias alters the performance of Seq2Seq models. Experiments show that the state-of-the-art Seq2Seq model overfits to both datasets while Seq2UMTree shows significantly better generalization. Our code is available at https://github.com/WindChimeRan/OpenJERE .