 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAIRO: Decoupling Order from Scale in Regression
Feb 16, 2026Standard regression methods typically optimize a single pointwise objective, such as mean squared error, which conflates the learning of ordering with the learning of scale. This coupling renders models vulnerable to outliers and heavy-tailed noise. We propose CAIRO (Calibrate After Initial Rank Ordering), a framework that decouples regression into two distinct stages. In the first stage, we learn a scoring function by minimizing a scale-invariant ranking loss; in the second, we recover the target scale via isotonic regression. We theoretically characterize a class of "Optimal-in-Rank-Order" objectives -- including variants of RankNet and Gini covariance -- and prove that they recover the ordering of the true conditional mean under mild assumptions. We further show that subsequent monotone calibration guarantees recovery of the true regression function. Empirically, CAIRO combines the representation learning of neural networks with the robustness of rank-based statistics. It matches the performance of state-of-the-art tree ensembles on tabular benchmarks and significantly outperforms standard regression objectives in regimes with heavy-tailed or heteroskedastic noise.
Flexible Entropy Control in RLVR with Gradient-Preserving Perspective
Feb 10, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a critical method for enhancing the reasoning capabilities of Large Language Models (LLMs). However, continuous training often leads to policy entropy collapse, characterized by a rapid decay in entropy that results in premature overconfidence, reduced output diversity, and vanishing gradient norms that inhibit learning. Gradient-Preserving Clipping is a primary factor influencing these dynamics, but existing mitigation strategies are largely static and lack a framework connecting clipping mechanisms to precise entropy control. This paper proposes reshaping entropy control in RL from the perspective of Gradient-Preserving Clipping. We first theoretically and empirically verify the contributions of specific importance sampling ratio regions to entropy growth and reduction. Leveraging these findings, we introduce a novel regulation mechanism using dynamic clipping threshold to precisely manage entropy. Furthermore, we design and evaluate dynamic entropy control strategies, including increase-then-decrease, decrease-increase-decrease, and oscillatory decay. Experimental results demonstrate that these strategies effectively mitigate entropy collapse, and achieve superior performance across multiple benchmarks.
TreeCUA: Efficiently Scaling GUI Automation with Tree-Structured Verifiable Evolution
Feb 10, 2026Effectively scaling GUI automation is essential for computer-use agents (CUAs); however, existing work primarily focuses on scaling GUI grounding rather than the more crucial GUI planning, which requires more sophisticated data collection. In reality, the exploration process of a CUA across apps/desktops/web pages typically follows a tree structure, with earlier functional entry points often being explored more frequently. Thus, organizing large-scale trajectories into tree structures can reduce data cost and streamline the data scaling of GUI planning. In this work, we propose TreeCUA to efficiently scale GUI automation with tree-structured verifiable evolution. We propose a multi-agent collaborative framework to explore the environment, verify actions, summarize trajectories, and evaluate quality to generate high-quality and scalable GUI trajectories. To improve efficiency, we devise a novel tree-based topology to store and replay duplicate exploration nodes, and design an adaptive exploration algorithm to balance the depth (\emph{i.e.}, trajectory difficulty) and breadth (\emph{i.e.}, trajectory diversity). Moreover, we develop world knowledge guidance and global memory backtracking to avoid low-quality generation. Finally, we naturally extend and propose the TreeCUA-DPO method from abundant tree node information, improving GUI planning capability by referring to the branch information of adjacent trajectories. Experimental results show that TreeCUA and TreeCUA-DPO offer significant improvements, and out-of-domain (OOD) studies further demonstrate strong generalization. All trajectory node information and code will be available at https://github.com/UITron-hub/TreeCUA.
Length-Unbiased Sequence Policy Optimization: Revealing and Controlling Response Length Variation in RLVR
Feb 05, 2026Recent applications of Reinforcement Learning with Verifiable Rewards (RLVR) to Large Language Models (LLMs) and Vision-Language Models (VLMs) have demonstrated significant success in enhancing reasoning capabilities for complex tasks. During RLVR training, an increase in response length is often regarded as a key factor contributing to the growth of reasoning ability. However, the patterns of change in response length vary significantly across different RLVR algorithms during the training process. To provide a fundamental explanation for these variations, this paper conducts an in-depth analysis of the components of mainstream RLVR algorithms. We present a theoretical analysis of the factors influencing response length and validate our theory through extensive experimentation. Building upon these theoretical findings, we propose the Length-Unbiased Sequence Policy Optimization (LUSPO) algorithm. Specifically, we rectify the length bias inherent in Group Sequence Policy Optimization (GSPO), rendering its loss function unbiased with respect to response length and thereby resolving the issue of response length collapse. We conduct extensive experiments across mathematical reasoning benchmarks and multimodal reasoning scenarios, where LUSPO consistently achieves superior performance. Empirical results demonstrate that LUSPO represents a novel, state-of-the-art optimization strategy compared to existing methods such as GRPO and GSPO.
MobileDreamer: Generative Sketch World Model for GUI Agent
Jan 07, 2026Mobile GUI agents have shown strong potential in real-world automation and practical applications. However, most existing agents remain reactive, making decisions mainly from current screen, which limits their performance on long-horizon tasks. Building a world model from repeated interactions enables forecasting action outcomes and supports better decision making for mobile GUI agents. This is challenging because the model must predict post-action states with spatial awareness while remaining efficient enough for practical deployment. In this paper, we propose MobileDreamer, an efficient world-model-based lookahead framework to equip the GUI agents based on the future imagination provided by the world model. It consists of textual sketch world model and rollout imagination for GUI agent. Textual sketch world model forecasts post-action states through a learning process to transform digital images into key task-related sketches, and designs a novel order-invariant learning strategy to preserve the spatial information of GUI elements. The rollout imagination strategy for GUI agent optimizes the action-selection process by leveraging the prediction capability of world model. Experiments on Android World show that MobileDreamer achieves state-of-the-art performance and improves task success by 5.25%. World model evaluations further verify that our textual sketch modeling accurately forecasts key GUI elements.
Learning When to Look: A Disentangled Curriculum for Strategic Perception in Multimodal Reasoning
Dec 19, 2025Multimodal Large Language Models (MLLMs) demonstrate significant potential but remain brittle in complex, long-chain visual reasoning tasks. A critical failure mode is "visual forgetting", where models progressively lose visual grounding as reasoning extends, a phenomenon aptly described as "think longer, see less". We posit this failure stems from current training paradigms prematurely entangling two distinct cognitive skills: (1) abstract logical reasoning "how-to-think") and (2) strategic visual perception ("when-to-look"). This creates a foundational cold-start deficiency -- weakening abstract reasoning -- and a strategic perception deficit, as models lack a policy for when to perceive. In this paper, we propose a novel curriculum-based framework to disentangle these skills. First, we introduce a disentangled Supervised Fine-Tuning (SFT) curriculum that builds a robust abstract reasoning backbone on text-only data before anchoring it to vision with a novel Perception-Grounded Chain-of-Thought (PG-CoT) paradigm. Second, we resolve the strategic perception deficit by formulating timing as a reinforcement learning problem. We design a Pivotal Perception Reward that teaches the model when to look by coupling perceptual actions to linguistic markers of cognitive uncertainty (e.g., "wait", "verify"), thereby learning an autonomous grounding policy. Our contributions include the formalization of these two deficiencies and the development of a principled, two-stage framework to address them, transforming the model from a heuristic-driven observer to a strategic, grounded reasoner. \textbf{Code}: \url{https://github.com/gaozilve-max/learning-when-to-look}.
FutureWeaver: Planning Test-Time Compute for Multi-Agent Systems with Modularized Collaboration
Dec 12, 2025



Scaling test-time computation improves large language model performance without additional training. Recent work demonstrates that techniques such as repeated sampling, self-verification, and self-reflection can significantly enhance task success by allocating more inference-time compute. However, applying these techniques across multiple agents in a multi-agent system is difficult: there does not exist principled mechanisms to allocate compute to foster collaboration among agents, to extend test-time scaling to collaborative interactions, or to distribute compute across agents under explicit budget constraints. To address this gap, we propose FutureWeaver, a framework for planning and optimizing test-time compute allocation in multi-agent systems under fixed budgets. FutureWeaver introduces modularized collaboration, formalized as callable functions that encapsulate reusable multi-agent workflows. These modules are automatically derived through self-play reflection by abstracting recurring interaction patterns from past trajectories. Building on these modules, FutureWeaver employs a dual-level planning architecture that optimizes compute allocation by reasoning over the current task state while also speculating on future steps. Experiments on complex agent benchmarks demonstrate that FutureWeaver consistently outperforms baselines across diverse budget settings, validating its effectiveness for multi-agent collaboration in inference-time optimization.
Metis-HOME: Hybrid Optimized Mixture-of-Experts for Multimodal Reasoning
Oct 23, 2025Inspired by recent advancements in LLM reasoning, the field of multimodal reasoning has seen remarkable progress, achieving significant performance gains on intricate tasks such as mathematical problem-solving. Despite this progress, current multimodal large reasoning models exhibit two key limitations. They tend to employ computationally expensive reasoning even for simple queries, leading to inefficiency. Furthermore, this focus on specialized reasoning often impairs their broader, more general understanding capabilities. In this paper, we propose Metis-HOME: a Hybrid Optimized Mixture-of-Experts framework designed to address this trade-off. Metis-HOME enables a ''Hybrid Thinking'' paradigm by structuring the original dense model into two distinct expert branches: a thinking branch tailored for complex, multi-step reasoning, and a non-thinking branch optimized for rapid, direct inference on tasks like general VQA and OCR. A lightweight, trainable router dynamically allocates queries to the most suitable expert. We instantiate Metis-HOME by adapting the Qwen2.5-VL-7B into an MoE architecture. Comprehensive evaluations reveal that our approach not only substantially enhances complex reasoning abilities but also improves the model's general capabilities, reversing the degradation trend observed in other reasoning-specialized models. Our work establishes a new paradigm for building powerful and versatile MLLMs, effectively resolving the prevalent reasoning-vs-generalization dilemma.
Metis-RISE: RL Incentivizes and SFT Enhances Multimodal Reasoning Model Learning
Jun 16, 2025Recent advancements in large language models (LLMs) have witnessed a surge in the development of advanced reasoning paradigms, which are now being integrated into multimodal large language models (MLLMs). However, existing approaches often fall short: methods solely employing reinforcement learning (RL) can struggle with sample inefficiency and activating entirely absent reasoning capabilities, while conventional pipelines that initiate with a cold-start supervised fine-tuning (SFT) phase before RL may restrict the model's exploratory capacity and face suboptimal convergence. In this work, we introduce \textbf{Metis-RISE} (\textbf{R}L \textbf{I}ncentivizes and \textbf{S}FT \textbf{E}nhances) for multimodal reasoning model learning. Unlike conventional approaches, Metis-RISE distinctively omits an initial SFT stage, beginning instead with an RL phase (e.g., using a Group Relative Policy Optimization variant) to incentivize and activate the model's latent reasoning capacity. Subsequently, the targeted SFT stage addresses two key challenges identified during RL: (1) \textit{inefficient trajectory sampling} for tasks where the model possesses but inconsistently applies correct reasoning, which we tackle using self-distilled reasoning trajectories from the RL model itself; and (2) \textit{fundamental capability absence}, which we address by injecting expert-augmented knowledge for prompts where the model entirely fails. This strategic application of RL for incentivization followed by SFT for enhancement forms the core of Metis-RISE, leading to two versions of our MLLMs (7B and 72B parameters). Evaluations on the OpenCompass Multimodal Reasoning Leaderboard demonstrate that both models achieve state-of-the-art performance among similar-sized models, with the 72B version ranking fourth overall.
HRScene: How Far Are VLMs from Effective High-Resolution Image Understanding?
Apr 29, 2025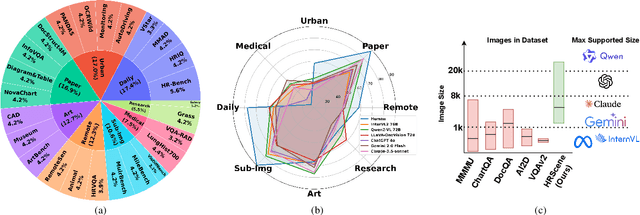
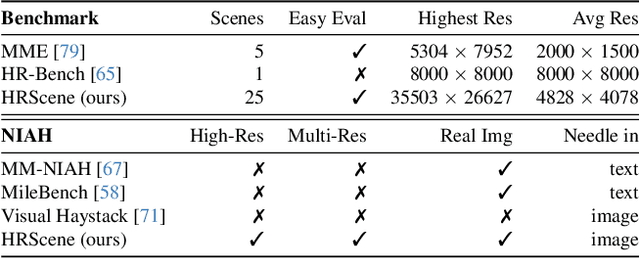
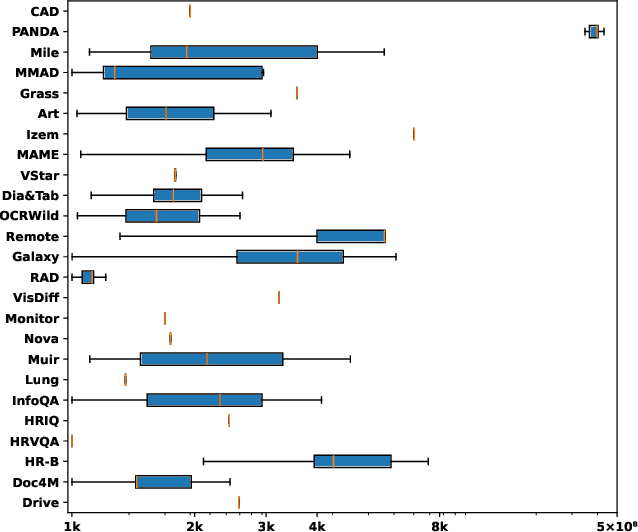
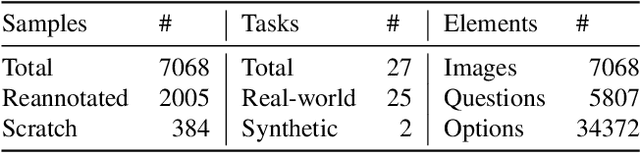
High-resolution image (HRI) understanding aims to process images with a large number of pixels, such as pathological images and agricultural aerial images, both of which can exceed 1 million pixels. Vision Large Language Models (VLMs) can allegedly handle HRIs, however, there is a lack of a comprehensive benchmark for VLMs to evaluate HRI understanding. To address this gap, we introduce HRScene, a novel unified benchmark for HRI understanding with rich scenes. HRScene incorporates 25 real-world datasets and 2 synthetic diagnostic datasets with resolutions ranging from 1,024 $\times$ 1,024 to 35,503 $\times$ 26,627. HRScene is collected and re-annotated by 10 graduate-level annotators, covering 25 scenarios, ranging from microscopic to radiology images, street views, long-range pictures, and telescope images. It includes HRIs of real-world objects, scanned documents, and composite multi-image. The two diagnostic evaluation datasets are synthesized by combining the target image with the gold answer and distracting images in different orders, assessing how well models utilize regions in HRI. We conduct extensive experiments involving 28 VLMs, including Gemini 2.0 Flash and GPT-4o. Experiments on HRScene show that current VLMs achieve an average accuracy of around 50% on real-world tasks, revealing significant gaps in HRI understanding. Results on synthetic datasets reveal that VLMs struggle to effectively utilize HRI regions, showing significant Regional Divergence and lost-in-middle, shedding light on future research.