 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPC-Bench: A Fine-grained Benchmark for Research Paper Comprehension
Jan 14, 2026Understanding research papers remains challenging for foundation models due to specialized scientific discourse and complex figures and tables, yet existing benchmarks offer limited fine-grained evaluation at scale. To address this gap, we introduce RPC-Bench, a large-scale question-answering benchmark built from review-rebuttal exchanges of high-quality computer science papers, containing 15K human-verified QA pairs. We design a fine-grained taxonomy aligned with the scientific research flow to assess models' ability to understand and answer why, what, and how questions in scholarly contexts. We also define an elaborate LLM-human interaction annotation framework to support large-scale labeling and quality control. Following the LLM-as-a-Judge paradigm, we develop a scalable framework that evaluates models on correctness-completeness and conciseness, with high agreement to human judgment. Experiments reveal that even the strongest models (GPT-5) achieve only 68.2% correctness-completeness, dropping to 37.46% after conciseness adjustment, highlighting substantial gaps in precise academic paper understanding. Our code and data are available at https://rpc-bench.github.io/.
MoRA: Missing Modality Low-Rank Adaptation for Visual Recognition
Nov 09, 2025Pre-trained vision language models have shown remarkable performance on visual recognition tasks, but they typically assume the availability of complete multimodal inputs during both training and inference. In real-world scenarios, however, modalities may be missing due to privacy constraints, collection difficulties, or resource limitations. While previous approaches have addressed this challenge using prompt learning techniques, they fail to capture the cross-modal relationships necessary for effective multimodal visual recognition and suffer from inevitable computational overhead. In this paper, we introduce MoRA, a parameter-efficient fine-tuning method that explicitly models cross-modal interactions while maintaining modality-specific adaptations. MoRA introduces modality-common parameters between text and vision encoders, enabling bidirectional knowledge transfer. Additionally, combined with the modality-specific parameters, MoRA allows the backbone model to maintain inter-modality interaction and enable intra-modality flexibility. Extensive experiments on standard benchmarks demonstrate that MoRA achieves an average performance improvement in missing-modality scenarios by 5.24% and uses only 25.90% of the inference time compared to the SOTA method while requiring only 0.11% of trainable parameters compared to full fine-tuning.
Windsock is Dancing: Adaptive Multimodal Retrieval-Augmented Generation
Oct 26, 2025Multimodal Retrieval-Augmented Generation (MRAG) has emerged as a promising method to generate factual and up-to-date responses of Multimodal Large Language Models (MLLMs) by incorporating non-parametric knowledge from external knowledge bases. However, existing MRAG approaches suffer from static retrieval strategies, inflexible modality selection, and suboptimal utilization of retrieved information, leading to three critical challenges: determining when to retrieve, what modality to incorporate, and how to utilize retrieved information effectively. To address these challenges, we introduce Windsock, a query-dependent module making decisions on retrieval necessity and modality selection, effectively reducing computational overhead and improving response quality. Additionally, we propose Dynamic Noise-Resistance (DANCE) Instruction Tuning, an adaptive training strategy that enhances MLLMs' ability to utilize retrieved information while maintaining robustness against noise. Moreover, we adopt a self-assessment approach leveraging knowledge within MLLMs to convert question-answering datasets to MRAG training datasets. Extensive experiments demonstrate that our proposed method significantly improves the generation quality by 17.07% while reducing 8.95% retrieval times.
SafeMap: Robust HD Map Construction from Incomplete Observations
Jul 01, 2025Robust high-definition (HD) map construction is vital for autonomous driving, yet existing methods often struggle with incomplete multi-view camera data. This paper presents SafeMap, a novel framework specifically designed to secure accuracy even when certain camera views are missing. SafeMap integrates two key components: the Gaussian-based Perspective View Reconstruction (G-PVR) module and the Distillation-based Bird's-Eye-View (BEV) Correction (D-BEVC) module. G-PVR leverages prior knowledge of view importance to dynamically prioritize the most informative regions based on the relationships among available camera views. Furthermore, D-BEVC utilizes panoramic BEV features to correct the BEV representations derived from incomplete observations. Together, these components facilitate the end-to-end map reconstruction and robust HD map generation. SafeMap is easy to implement and integrates seamlessly into existing systems, offering a plug-and-play solution for enhanced robustness. Experimental results demonstrate that SafeMap significantly outperforms previous methods in both complete and incomplete scenarios, highlighting its superior performance and reliability.
HRScene: How Far Are VLMs from Effective High-Resolution Image Understanding?
Apr 29, 2025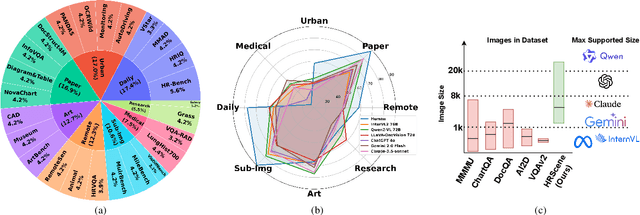
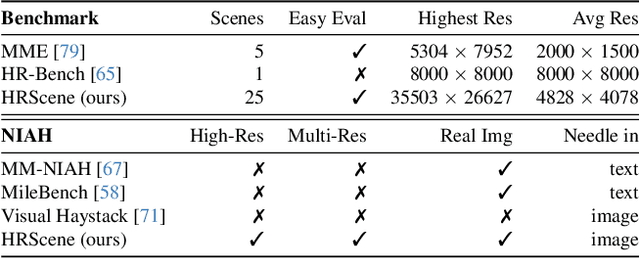
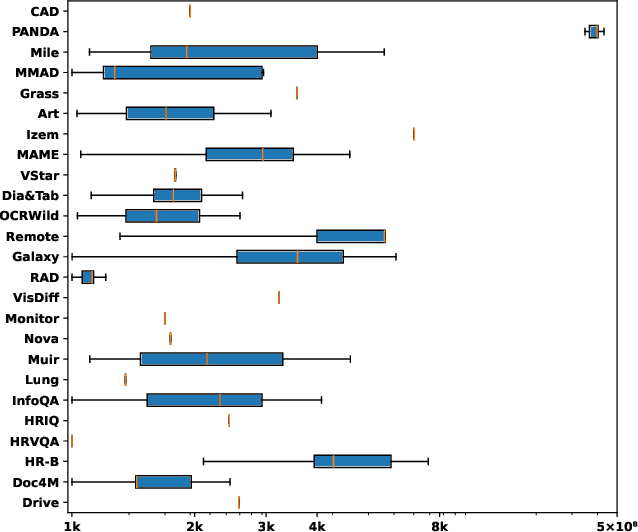
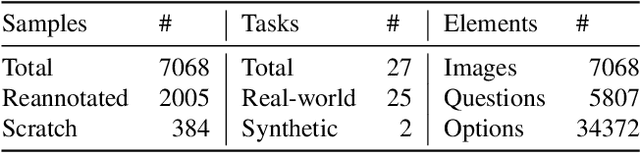
High-resolution image (HRI) understanding aims to process images with a large number of pixels, such as pathological images and agricultural aerial images, both of which can exceed 1 million pixels. Vision Large Language Models (VLMs) can allegedly handle HRIs, however, there is a lack of a comprehensive benchmark for VLMs to evaluate HRI understanding. To address this gap, we introduce HRScene, a novel unified benchmark for HRI understanding with rich scenes. HRScene incorporates 25 real-world datasets and 2 synthetic diagnostic datasets with resolutions ranging from 1,024 $\times$ 1,024 to 35,503 $\times$ 26,627. HRScene is collected and re-annotated by 10 graduate-level annotators, covering 25 scenarios, ranging from microscopic to radiology images, street views, long-range pictures, and telescope images. It includes HRIs of real-world objects, scanned documents, and composite multi-image. The two diagnostic evaluation datasets are synthesized by combining the target image with the gold answer and distracting images in different orders, assessing how well models utilize regions in HRI. We conduct extensive experiments involving 28 VLMs, including Gemini 2.0 Flash and GPT-4o. Experiments on HRScene show that current VLMs achieve an average accuracy of around 50% on real-world tasks, revealing significant gaps in HRI understanding. Results on synthetic datasets reveal that VLMs struggle to effectively utilize HRI regions, showing significant Regional Divergence and lost-in-middle, shedding light on future research.
MapFusion: A Novel BEV Feature Fusion Network for Multi-modal Map Construction
Feb 05, 2025Map construction task plays a vital role in providing precise and comprehensive static environmental information essential for autonomous driving systems. Primary sensors include cameras and LiDAR, with configurations varying between camera-only, LiDAR-only, or camera-LiDAR fusion, based on cost-performance considerations. While fusion-based methods typically perform best, existing approaches often neglect modality interaction and rely on simple fusion strategies, which suffer from the problems of misalignment and information loss. To address these issues, we propose MapFusion, a novel multi-modal Bird's-Eye View (BEV) feature fusion method for map construction. Specifically, to solve the semantic misalignment problem between camera and LiDAR BEV features, we introduce the Cross-modal Interaction Transform (CIT) module, enabling interaction between two BEV feature spaces and enhancing feature representation through a self-attention mechanism. Additionally, we propose an effective Dual Dynamic Fusion (DDF) module to adaptively select valuable information from different modalities, which can take full advantage of the inherent information between different modalities. Moreover, MapFusion is designed to be simple and plug-and-play, easily integrated into existing pipelines. We evaluate MapFusion on two map construction tasks, including High-definition (HD) map and BEV map segmentation, to show its versatility and effectiveness. Compared with the state-of-the-art methods, MapFusion achieves 3.6% and 6.2% absolute improvements on the HD map construction and BEV map segmentation tasks on the nuScenes dataset, respectively, demonstrating the superiority of our approach.
KALAHash: Knowledge-Anchored Low-Resource Adaptation for Deep Hashing
Dec 27, 2024



Deep hashing has been widely used for large-scale approximate nearest neighbor search due to its storage and search efficiency. However, existing deep hashing methods predominantly rely on abundant training data, leaving the more challenging scenario of low-resource adaptation for deep hashing relatively underexplored. This setting involves adapting pre-trained models to downstream tasks with only an extremely small number of training samples available. Our preliminary benchmarks reveal that current methods suffer significant performance degradation due to the distribution shift caused by limited training samples. To address these challenges, we introduce Class-Calibration LoRA (CLoRA), a novel plug-and-play approach that dynamically constructs low-rank adaptation matrices by leveraging class-level textual knowledge embeddings. CLoRA effectively incorporates prior class knowledge as anchors, enabling parameter-efficient fine-tuning while maintaining the original data distribution. Furthermore, we propose Knowledge-Guided Discrete Optimization (KIDDO), a framework to utilize class knowledge to compensate for the scarcity of visual information and enhance the discriminability of hash codes. Extensive experiments demonstrate that our proposed method, Knowledge- Anchored Low-Resource Adaptation Hashing (KALAHash), significantly boosts retrieval performance and achieves a 4x data efficiency in low-resource scenarios.
Temporal-Frequency State Space Duality: An Efficient Paradigm for Speech Emotion Recognition
Dec 22, 2024Speech Emotion Recognition (SER) plays a critical role in enhancing user experience within human-computer interaction. However, existing methods are overwhelmed by temporal domain analysis, overlooking the valuable envelope structures of the frequency domain that are equally important for robust emotion recognition. To overcome this limitation, we propose TF-Mamba, a novel multi-domain framework that captures emotional expressions in both temporal and frequency dimensions.Concretely, we propose a temporal-frequency mamba block to extract temporal- and frequency-aware emotional features, achieving an optimal balance between computational efficiency and model expressiveness. Besides, we design a Complex Metric-Distance Triplet (CMDT) loss to enable the model to capture representative emotional clues for SER. Extensive experiments on the IEMOCAP and MELD datasets show that TF-Mamba surpasses existing methods in terms of model size and latency, providing a more practical solution for future SER applications.
Pre-Training and Prompting for Few-Shot Node Classification on Text-Attributed Graphs
Jul 22, 2024
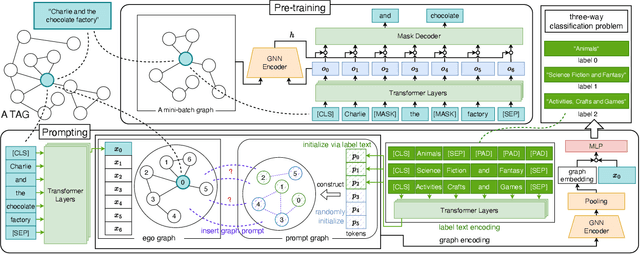
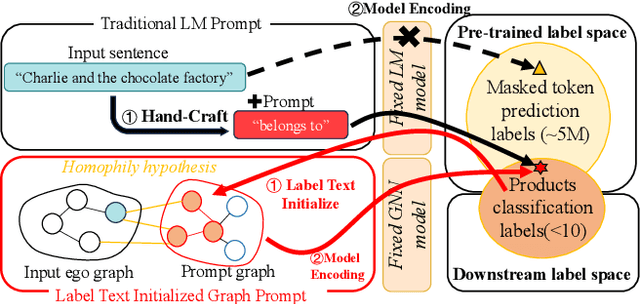
The text-attributed graph (TAG) is one kind of important real-world graph-structured data with each node associated with raw texts. For TAGs, traditional few-shot node classification methods directly conduct training on the pre-processed node features and do not consider the raw texts. The performance is highly dependent on the choice of the feature pre-processing method. In this paper, we propose P2TAG, a framework designed for few-shot node classification on TAGs with graph pre-training and prompting. P2TAG first pre-trains the language model (LM) and graph neural network (GNN) on TAGs with self-supervised loss. To fully utilize the ability of language models, we adapt the masked language modeling objective for our framework. The pre-trained model is then used for the few-shot node classification with a mixed prompt method, which simultaneously considers both text and graph information. We conduct experiments on six real-world TAGs, including paper citation networks and product co-purchasing networks. Experimental results demonstrate that our proposed framework outperforms existing graph few-shot learning methods on these datasets with +18.98% ~ +35.98% improvements.
TableLLM: Enabling Tabular Data Manipulation by LLMs in Real Office Usage Scenarios
Apr 01, 2024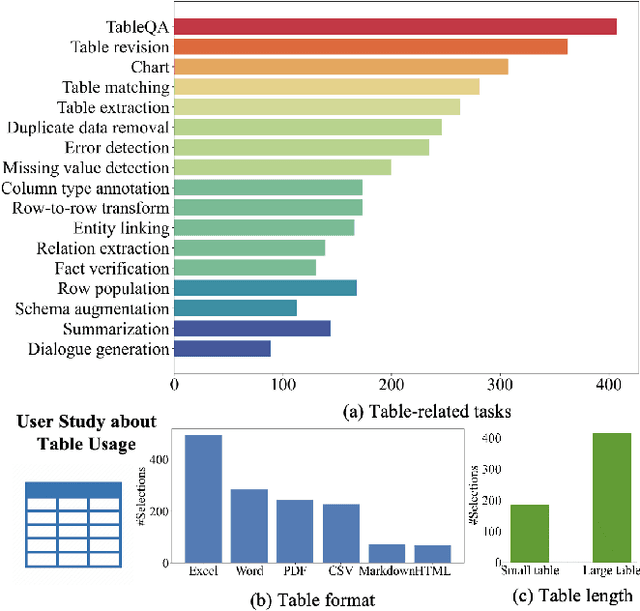

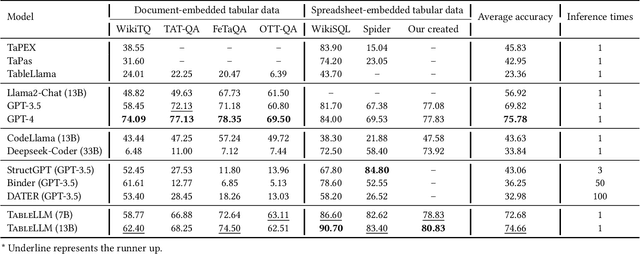
We introduce TableLLM, a robust large language model (LLM) with 13 billion parameters, purpose-built for proficiently handling tabular data manipulation tasks, whether they are embedded within documents or spreadsheets, catering to real-world office scenarios. We propose a distant supervision method for training, which comprises a reasoning process extension strategy, aiding in training LLMs to understand reasoning patterns more effectively as well as a cross-way validation strategy, ensuring the quality of the automatically generated data. To evaluate the performance of TableLLM, we have crafted a benchmark tailored to address both document and spreadsheet formats as well as constructed a well-organized evaluation pipeline capable of handling both scenarios. Thorough evaluations underscore the advantages of TableLLM when compared to various existing general-purpose and tabular data-focused LLMs. We have publicly released the model checkpoint, source code, benchmarks, and a web application for user interaction.Our codes and data are publicly available at https://github.com/TableLLM/TableLLM.