 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongRAG: A Dual-Perspective Retrieval-Augmented Generation Paradigm for Long-Context Question Answering
Oct 23, 2024Long-Context Question Answering (LCQA), a challenging task, aims to reason over long-context documents to yield accurate answers to questions. Existing long-context Large Language Models (LLMs) for LCQA often struggle with the "lost in the middle" issue. Retrieval-Augmented Generation (RAG) mitigates this issue by providing external factual evidence. However, its chunking strategy disrupts the global long-context information, and its low-quality retrieval in long contexts hinders LLMs from identifying effective factual details due to substantial noise. To this end, we propose LongRAG, a general, dual-perspective, and robust LLM-based RAG system paradigm for LCQA to enhance RAG's understanding of complex long-context knowledge (i.e., global information and factual details). We design LongRAG as a plug-and-play paradigm, facilitating adaptation to various domains and LLMs. Extensive experiments on three multi-hop datasets demonstrate that LongRAG significantly outperforms long-context LLMs (up by 6.94%), advanced RAG (up by 6.16%), and Vanilla RAG (up by 17.25%). Furthermore, we conduct quantitative ablation studies and multi-dimensional analyses, highlighting the effectiveness of the system's components and fine-tuning strategies. Data and code are available at https://github.com/QingFei1/LongRAG.
Why are hyperbolic neural networks effective? A study on hierarchical representation capability
Feb 04, 2024Hyperbolic Neural Networks (HNNs), operating in hyperbolic space, have been widely applied in recent years, motivated by the existence of an optimal embedding in hyperbolic space that can preserve data hierarchical relationships (termed Hierarchical Representation Capability, HRC) more accurately than Euclidean space. However, there is no evidence to suggest that HNNs can achieve this theoretical optimal embedding, leading to much research being built on flawed motivations. In this paper, we propose a benchmark for evaluating HRC and conduct a comprehensive analysis of why HNNs are effective through large-scale experiments. Inspired by the analysis results, we propose several pre-training strategies to enhance HRC and improve the performance of downstream tasks, further validating the reliability of the analysis. Experiments show that HNNs cannot achieve the theoretical optimal embedding. The HRC is significantly affected by the optimization objectives and hierarchical structures, and enhancing HRC through pre-training strategies can significantly improve the performance of HNNs.
Are Intermediate Layers and Labels Really Necessary? A General Language Model Distillation Method
Jun 11, 2023



The large scale of pre-trained language models poses a challenge for their deployment on various devices, with a growing emphasis on methods to compress these models, particularly knowledge distillation. However, current knowledge distillation methods rely on the model's intermediate layer features and the golden labels (also called hard labels), which usually require aligned model architecture and enough labeled data respectively. Moreover, the parameters of vocabulary are usually neglected in existing methods. To address these problems, we propose a general language model distillation (GLMD) method that performs two-stage word prediction distillation and vocabulary compression, which is simple and surprisingly shows extremely strong performance. Specifically, GLMD supports more general application scenarios by eliminating the constraints of dimension and structure between models and the need for labeled datasets through the absence of intermediate layers and golden labels. Meanwhile, based on the long-tailed distribution of word frequencies in the data, GLMD designs a strategy of vocabulary compression through decreasing vocabulary size instead of dimensionality. Experimental results show that our method outperforms 25 state-of-the-art methods on the SuperGLUE benchmark, achieving an average score that surpasses the best method by 3%.
GKD: A General Knowledge Distillation Framework for Large-scale Pre-trained Language Model
Jun 11, 2023



Currently, the reduction in the parameter scale of large-scale pre-trained language models (PLMs) through knowledge distillation has greatly facilitated their widespread deployment on various devices. However, the deployment of knowledge distillation systems faces great challenges in real-world industrial-strength applications, which require the use of complex distillation methods on even larger-scale PLMs (over 10B), limited by memory on GPUs and the switching of methods. To overcome these challenges, we propose GKD, a general knowledge distillation framework that supports distillation on larger-scale PLMs using various distillation methods. With GKD, developers can build larger distillation models on memory-limited GPUs and easily switch and combine different distillation methods within a single framework. Experimental results show that GKD can support the distillation of at least 100B-scale PLMs and 25 mainstream methods on 8 NVIDIA A100 (40GB) GPUs.
Coherence-Based Distributed Document Representation Learning for Scientific Documents
Jan 08, 2022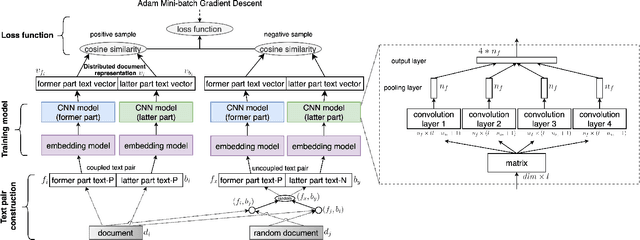
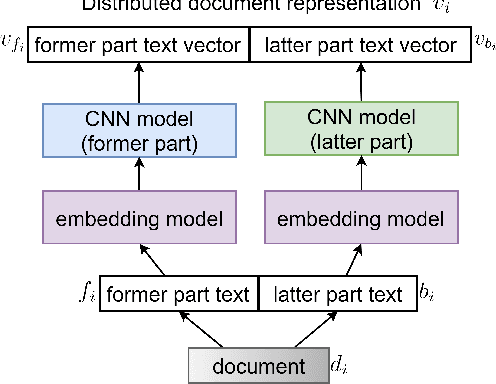
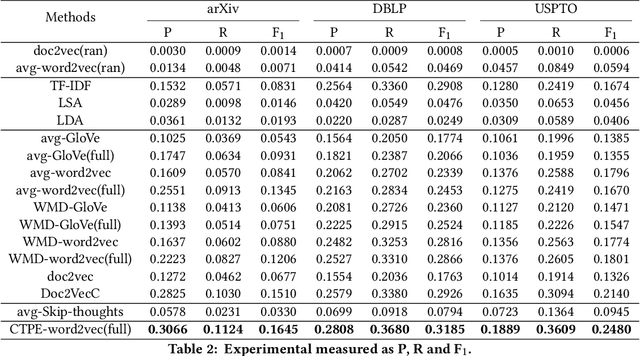
Distributed document representation is one of the basic problems in natural language processing. Currently distributed document representation methods mainly consider the context information of words or sentences. These methods do not take into account the coherence of the document as a whole, e.g., a relation between the paper title and abstract, headline and description, or adjacent bodies in the document. The coherence shows whether a document is meaningful, both logically and syntactically, especially in scientific documents (papers or patents, etc.). In this paper, we propose a coupled text pair embedding (CTPE) model to learn the representation of scientific documents, which maintains the coherence of the document with coupled text pairs formed by segmenting the document. First, we divide the document into two parts (e.g., title and abstract, etc) which construct a coupled text pair. Then, we adopt negative sampling to construct uncoupled text pairs whose two parts are from different documents. Finally, we train the model to judge whether the text pair is coupled or uncoupled and use the obtained embedding of coupled text pairs as the embedding of documents. We perform experiments on three datasets for one information retrieval task and two recommendation tasks. The experimental results verify the effectiveness of the proposed CTPE model.