 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATLAS: All-round Testing of Long-context Abilities across Scales
May 27, 2026Long-context language models now advertise context windows up to millions of tokens, yet evaluations typically report a single length or a narrow task family, masking two failure modes: performance can collapse as length grows, and strong retrieval need not transfer to downstream use. We present ATLAS, a benchmarking framework that redefines long-context evaluation as length-dependent capability profiling. ATLAS contributes three methodological principles:(i) a layered taxonomy separating foundational operations from application workloads so failures can be attributed, (ii) length-aware AUC scoring that integrates score-length curves over a fixed 8K-1M grid, replacing single-point metrics with full degradation profiles, and (iii) ATLAScore, a harmonic-mean aggregate over taxonomy categories that penalizes imbalanced profiles, with end-to-end uncertainty propagation from subset scores through the nonlinear final aggregate. We instantiate the framework across eight capability dimensions with nine auditable components and 6,438 instances, and evaluate 26 models. Gemini-3.1-Pro-Preview leads at 128K, Claude-Opus-4.6 leads at 1M. Rankings reshuffle substantially between ATLASscore@8K-128K and ATLASscore@8K-1M: 7 models move by at least two ranks, and the two taxonomy layers share only 61% of cross-model variance, with individual rank gaps up to 12 positions. These results support reporting long-context quality by capability and length, not by a single headline score.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Efficient Context Scaling with LongCat ZigZag Attention
Dec 30, 2025We introduce LongCat ZigZag Attention (LoZA), which is a sparse attention scheme designed to transform any existing full-attention models into sparse versions with rather limited compute budget. In long-context scenarios, LoZA can achieve significant speed-ups both for prefill-intensive (e.g., retrieval-augmented generation) and decode-intensive (e.g., tool-integrated reasoning) cases. Specifically, by applying LoZA to LongCat-Flash during mid-training, we serve LongCat-Flash-Exp as a long-context foundation model that can swiftly process up to 1 million tokens, enabling efficient long-term reasoning and long-horizon agentic capabilities.
IIET: Efficient Numerical Transformer via Implicit Iterative Euler Method
Sep 26, 2025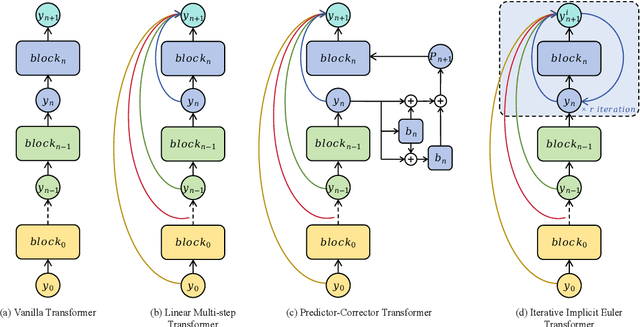
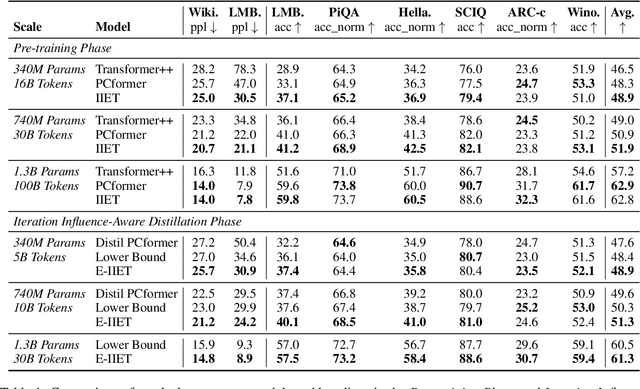
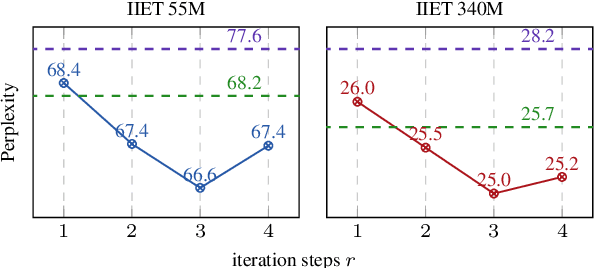

High-order numerical methods enhance Transformer performance in tasks like NLP and CV, but introduce a performance-efficiency trade-off due to increased computational overhead. Our analysis reveals that conventional efficiency techniques, such as distillation, can be detrimental to the performance of these models, exemplified by PCformer. To explore more optimizable ODE-based Transformer architectures, we propose the \textbf{I}terative \textbf{I}mplicit \textbf{E}uler \textbf{T}ransformer \textbf{(IIET)}, which simplifies high-order methods using an iterative implicit Euler approach. This simplification not only leads to superior performance but also facilitates model compression compared to PCformer. To enhance inference efficiency, we introduce \textbf{I}teration \textbf{I}nfluence-\textbf{A}ware \textbf{D}istillation \textbf{(IIAD)}. Through a flexible threshold, IIAD allows users to effectively balance the performance-efficiency trade-off. On lm-evaluation-harness, IIET boosts average accuracy by 2.65\% over vanilla Transformers and 0.8\% over PCformer. Its efficient variant, E-IIET, significantly cuts inference overhead by 55\% while retaining 99.4\% of the original task accuracy. Moreover, the most efficient IIET variant achieves an average performance gain exceeding 1.6\% over vanilla Transformer with comparable speed.
NeedleInATable: Exploring Long-Context Capability of Large Language Models towards Long-Structured Tables
Apr 09, 2025Processing structured tabular data, particularly lengthy tables, constitutes a fundamental yet challenging task for large language models (LLMs). However, existing long-context benchmarks primarily focus on unstructured text, neglecting the challenges of long and complex structured tables. To address this gap, we introduce NeedleInATable (NIAT), a novel task that treats each table cell as a "needle" and requires the model to extract the target cell under different queries. Evaluation results of mainstream LLMs on this benchmark show they lack robust long-table comprehension, often relying on superficial correlations or shortcuts for complex table understanding tasks, revealing significant limitations in processing intricate tabular data. To this end, we propose a data synthesis method to enhance models' long-table comprehension capabilities. Experimental results show that our synthesized training data significantly enhances LLMs' performance on the NIAT task, outperforming both long-context LLMs and long-table agent methods. This work advances the evaluation of LLMs' genuine long-structured table comprehension capabilities and paves the way for progress in long-context and table understanding applications.
Ltri-LLM: Streaming Long Context Inference for LLMs with Training-Free Dynamic Triangular Attention Pattern
Dec 06, 2024


The quadratic computational complexity of the attention mechanism in current Large Language Models (LLMs) renders inference with long contexts prohibitively expensive. To address this challenge, various approaches aim to retain critical portions of the context to optimally approximate Full Attention (FA) through Key-Value (KV) compression or Sparse Attention (SA), enabling the processing of virtually unlimited text lengths in a streaming manner. However, these methods struggle to achieve performance levels comparable to FA, particularly in retrieval tasks. In this paper, our analysis of attention head patterns reveals that LLMs' attention distributions show strong local correlations, naturally reflecting a chunking mechanism for input context. We propose Ltri-LLM framework, which divides KVs into spans, stores them in an offline index, and retrieves the relevant KVs into memory for various queries. Experimental results on popular long text benchmarks show that Ltri-LLM can achieve performance close to FA while maintaining efficient, streaming-based inference.
GKD: A General Knowledge Distillation Framework for Large-scale Pre-trained Language Model
Jun 11, 2023



Currently, the reduction in the parameter scale of large-scale pre-trained language models (PLMs) through knowledge distillation has greatly facilitated their widespread deployment on various devices. However, the deployment of knowledge distillation systems faces great challenges in real-world industrial-strength applications, which require the use of complex distillation methods on even larger-scale PLMs (over 10B), limited by memory on GPUs and the switching of methods. To overcome these challenges, we propose GKD, a general knowledge distillation framework that supports distillation on larger-scale PLMs using various distillation methods. With GKD, developers can build larger distillation models on memory-limited GPUs and easily switch and combine different distillation methods within a single framework. Experimental results show that GKD can support the distillation of at least 100B-scale PLMs and 25 mainstream methods on 8 NVIDIA A100 (40GB) GPUs.
Multi-task Transformer with Relation-attention and Type-attention for Named Entity Recognition
Mar 20, 2023Named entity recognition (NER) is an important research problem in natural language processing. There are three types of NER tasks, including flat, nested and discontinuous entity recognition. Most previous sequential labeling models are task-specific, while recent years have witnessed the rising of generative models due to the advantage of unifying all NER tasks into the seq2seq model framework. Although achieving promising performance, our pilot studies demonstrate that existing generative models are ineffective at detecting entity boundaries and estimating entity types. This paper proposes a multi-task Transformer, which incorporates an entity boundary detection task into the named entity recognition task. More concretely, we achieve entity boundary detection by classifying the relations between tokens within the sentence. To improve the accuracy of entity-type mapping during decoding, we adopt an external knowledge base to calculate the prior entity-type distributions and then incorporate the information into the model via the self and cross-attention mechanisms. We perform experiments on an extensive set of NER benchmarks, including two flat, three nested, and three discontinuous NER datasets. Experimental results show that our approach considerably improves the generative NER model's performance.
Inflected Forms Are Redundant in Question Generation Models
Jan 01, 2023Neural models with an encoder-decoder framework provide a feasible solution to Question Generation (QG). However, after analyzing the model vocabulary we find that current models (both RNN-based and pre-training based) have more than 23\% inflected forms. As a result, the encoder will generate separate embeddings for the inflected forms, leading to a waste of training data and parameters. Even worse, in decoding these models are vulnerable to irrelevant noise and they suffer from high computational costs. In this paper, we propose an approach to enhance the performance of QG by fusing word transformation. Firstly, we identify the inflected forms of words from the input of encoder, and replace them with the root words, letting the encoder pay more attention to the repetitive root words. Secondly, we propose to adapt QG as a combination of the following actions in the encode-decoder framework: generating a question word, copying a word from the source sequence or generating a word transformation type. Such extension can greatly decrease the size of predicted words in the decoder as well as noise. We apply our approach to a typical RNN-based model and \textsc{UniLM} to get the improved versions. We conduct extensive experiments on SQuAD and MS MARCO datasets. The experimental results show that the improved versions can significantly outperform the corresponding baselines in terms of BLEU, ROUGE-L and METEOR as well as time cost.
CLOWER: A Pre-trained Language Model with Contrastive Learning over Word and Character Representations
Aug 23, 2022

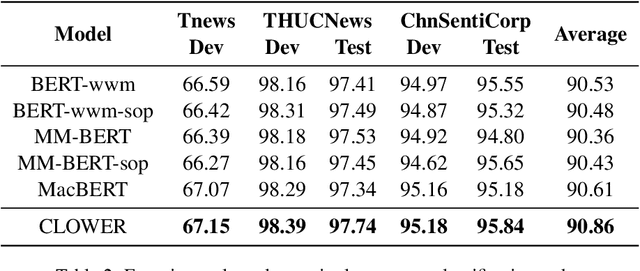
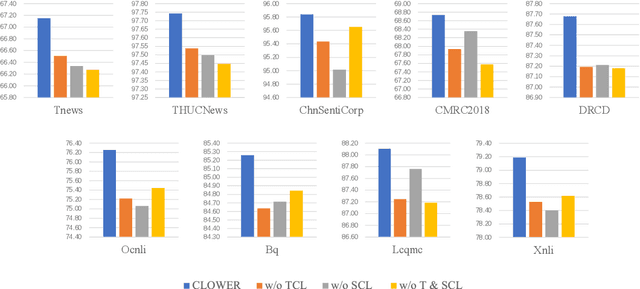
Pre-trained Language Models (PLMs) have achieved remarkable performance gains across numerous downstream tasks in natural language understanding. Various Chinese PLMs have been successively proposed for learning better Chinese language representation. However, most current models use Chinese characters as inputs and are not able to encode semantic information contained in Chinese words. While recent pre-trained models incorporate both words and characters simultaneously, they usually suffer from deficient semantic interactions and fail to capture the semantic relation between words and characters. To address the above issues, we propose a simple yet effective PLM CLOWER, which adopts the Contrastive Learning Over Word and charactER representations. In particular, CLOWER implicitly encodes the coarse-grained information (i.e., words) into the fine-grained representations (i.e., characters) through contrastive learning on multi-grained information. CLOWER is of great value in realistic scenarios since it can be easily incorporated into any existing fine-grained based PLMs without modifying the production pipelines.Extensive experiments conducted on a range of downstream tasks demonstrate the superior performance of CLOWER over several state-of-the-art baselines.