 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Ltri-LLM: Streaming Long Context Inference for LLMs with Training-Free Dynamic Triangular Attention Pattern
Dec 06, 2024

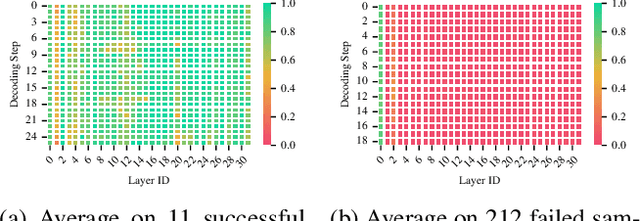

The quadratic computational complexity of the attention mechanism in current Large Language Models (LLMs) renders inference with long contexts prohibitively expensive. To address this challenge, various approaches aim to retain critical portions of the context to optimally approximate Full Attention (FA) through Key-Value (KV) compression or Sparse Attention (SA), enabling the processing of virtually unlimited text lengths in a streaming manner. However, these methods struggle to achieve performance levels comparable to FA, particularly in retrieval tasks. In this paper, our analysis of attention head patterns reveals that LLMs' attention distributions show strong local correlations, naturally reflecting a chunking mechanism for input context. We propose Ltri-LLM framework, which divides KVs into spans, stores them in an offline index, and retrieves the relevant KVs into memory for various queries. Experimental results on popular long text benchmarks show that Ltri-LLM can achieve performance close to FA while maintaining efficient, streaming-based inference.
The 2nd Place Solution for 2023 Waymo Open Sim Agents Challenge
Jun 28, 2023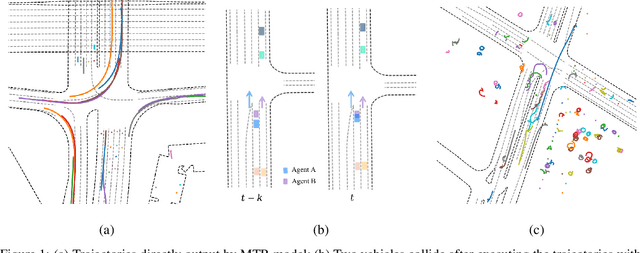
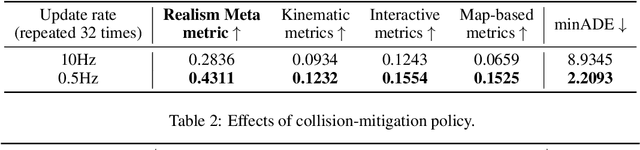

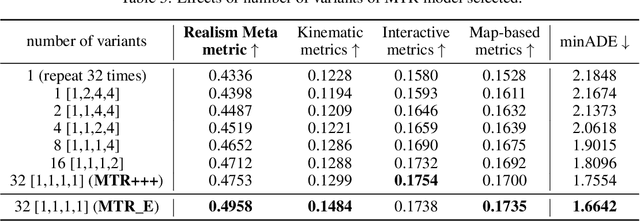
In this technical report, we present the 2nd place solution of 2023 Waymo Open Sim Agents Challenge (WOSAC)[4]. We propose a simple yet effective autoregressive method for simulating multi-agent behaviors, which is built upon a well-known multimodal motion forecasting framework called Motion Transformer (MTR)[5] with postprocessing algorithms applied. Our submission named MTR+++ achieves 0.4697 on the Realism Meta metric in 2023 WOSAC. Besides, a modified model based on MTR named MTR_E is proposed after the challenge, which has a better score 0.4911 and is ranked the 3rd on the leaderboard of WOSAC as of June 25, 2023.