 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopyright Detective: A Forensic System to Evidence LLMs Flickering Copyright Leakage Risks
Feb 05, 2026We present Copyright Detective, the first interactive forensic system for detecting, analyzing, and visualizing potential copyright risks in LLM outputs. The system treats copyright infringement versus compliance as an evidence discovery process rather than a static classification task due to the complex nature of copyright law. It integrates multiple detection paradigms, including content recall testing, paraphrase-level similarity analysis, persuasive jailbreak probing, and unlearning verification, within a unified and extensible framework. Through interactive prompting, response collection, and iterative workflows, our system enables systematic auditing of verbatim memorization and paraphrase-level leakage, supporting responsible deployment and transparent evaluation of LLM copyright risks even with black-box access.
Agentic Reasoning for Large Language Models
Jan 18, 2026Reasoning is a fundamental cognitive process underlying inference, problem-solving, and decision-making. While large language models (LLMs) demonstrate strong reasoning capabilities in closed-world settings, they struggle in open-ended and dynamic environments. Agentic reasoning marks a paradigm shift by reframing LLMs as autonomous agents that plan, act, and learn through continual interaction. In this survey, we organize agentic reasoning along three complementary dimensions. First, we characterize environmental dynamics through three layers: foundational agentic reasoning, which establishes core single-agent capabilities including planning, tool use, and search in stable environments; self-evolving agentic reasoning, which studies how agents refine these capabilities through feedback, memory, and adaptation; and collective multi-agent reasoning, which extends intelligence to collaborative settings involving coordination, knowledge sharing, and shared goals. Across these layers, we distinguish in-context reasoning, which scales test-time interaction through structured orchestration, from post-training reasoning, which optimizes behaviors via reinforcement learning and supervised fine-tuning. We further review representative agentic reasoning frameworks across real-world applications and benchmarks, including science, robotics, healthcare, autonomous research, and mathematics. This survey synthesizes agentic reasoning methods into a unified roadmap bridging thought and action, and outlines open challenges and future directions, including personalization, long-horizon interaction, world modeling, scalable multi-agent training, and governance for real-world deployment.
PEARL: Self-Evolving Assistant for Time Management with Reinforcement Learning
Jan 17, 2026Overlapping calendar invitations force busy professionals to repeatedly decide which meetings to attend, reschedule, or decline. We refer to this preference-driven decision process as calendar conflict resolution. Automating such process is crucial yet challenging. Scheduling logistics drain hours, and human delegation often fails at scale, which motivate we to ask: Can we trust large language model (LLM) or language agent to manager time? To enable systematic study of this question, we introduce CalConflictBench, a benchmark for long-horizon calendar conflict resolution. Conflicts are presented sequentially and agents receive feedback after each round, requiring them to infer and adapt to user preferences progressively. Our experiments show that current LLM agents perform poorly with high error rates, e.g., Qwen-3-30B-Think has 35% average error rate. To address this gap, we propose PEARL, a reinforcement-learning framework that augments language agent with an external memory module and optimized round-wise reward design, enabling agent to progressively infer and adapt to user preferences on-the-fly. Experiments on CalConflictBench shows that PEARL achieves 0.76 error reduction rate, and 55% improvement in average error rate compared to the strongest baseline.
Current Agents Fail to Leverage World Model as Tool for Foresight
Jan 08, 2026Agents built on vision-language models increasingly face tasks that demand anticipating future states rather than relying on short-horizon reasoning. Generative world models offer a promising remedy: agents could use them as external simulators to foresee outcomes before acting. This paper empirically examines whether current agents can leverage such world models as tools to enhance their cognition. Across diverse agentic and visual question answering tasks, we observe that some agents rarely invoke simulation (fewer than 1%), frequently misuse predicted rollouts (approximately 15%), and often exhibit inconsistent or even degraded performance (up to 5%) when simulation is available or enforced. Attribution analysis further indicates that the primary bottleneck lies in the agents' capacity to decide when to simulate, how to interpret predicted outcomes, and how to integrate foresight into downstream reasoning. These findings underscore the need for mechanisms that foster calibrated, strategic interaction with world models, paving the way toward more reliable anticipatory cognition in future agent systems.
From Word to World: Can Large Language Models be Implicit Text-based World Models?
Dec 21, 2025Agentic reinforcement learning increasingly relies on experience-driven scaling, yet real-world environments remain non-adaptive, limited in coverage, and difficult to scale. World models offer a potential way to improve learning efficiency through simulated experience, but it remains unclear whether large language models can reliably serve this role and under what conditions they meaningfully benefit agents. We study these questions in text-based environments, which provide a controlled setting to reinterpret language modeling as next-state prediction under interaction. We introduce a three-level framework for evaluating LLM-based world models: (i) fidelity and consistency, (ii) scalability and robustness, and (iii) agent utility. Across five representative environments, we find that sufficiently trained world models maintain coherent latent state, scale predictably with data and model size, and improve agent performance via action verification, synthetic trajectory generation, and warm-starting reinforcement learning. Meanwhile, these gains depend critically on behavioral coverage and environment complexity, delineating clear boundry on when world modeling effectively supports agent learning.
JustRL: Scaling a 1.5B LLM with a Simple RL Recipe
Dec 18, 2025Recent advances in reinforcement learning for large language models have converged on increasing complexity: multi-stage training pipelines, dynamic hyperparameter schedules, and curriculum learning strategies. This raises a fundamental question: \textbf{Is this complexity necessary?} We present \textbf{JustRL}, a minimal approach using single-stage training with fixed hyperparameters that achieves state-of-the-art performance on two 1.5B reasoning models (54.9\% and 64.3\% average accuracy across nine mathematical benchmarks) while using 2$\times$ less compute than sophisticated approaches. The same hyperparameters transfer across both models without tuning, and training exhibits smooth, monotonic improvement over 4,000+ steps without the collapses or plateaus that typically motivate interventions. Critically, ablations reveal that adding ``standard tricks'' like explicit length penalties and robust verifiers may degrade performance by collapsing exploration. These results suggest that the field may be adding complexity to solve problems that disappear with a stable, scaled-up baseline. We release our models and code to establish a simple, validated baseline for the community.
LoCoBench-Agent: An Interactive Benchmark for LLM Agents in Long-Context Software Engineering
Nov 17, 2025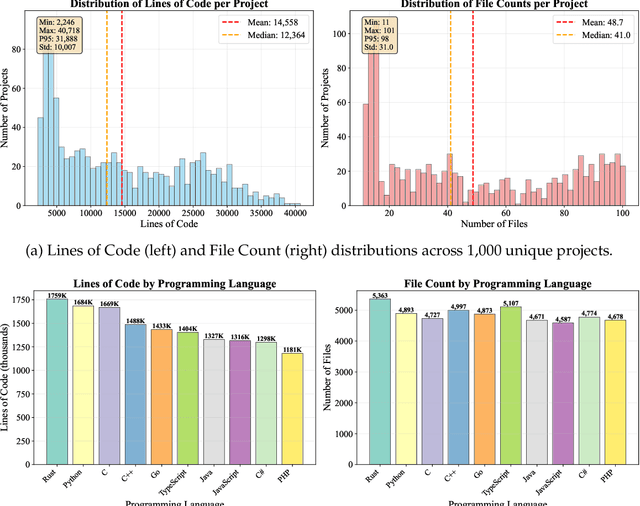
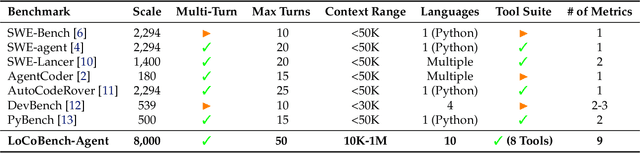

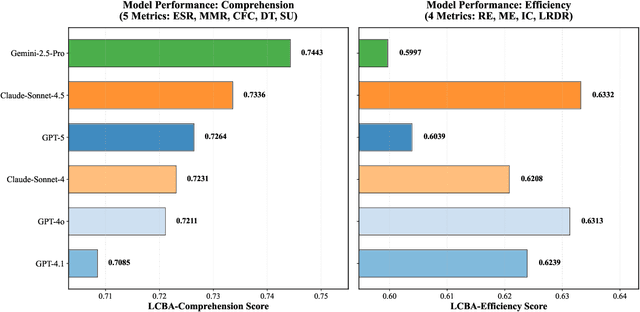
As large language models (LLMs) evolve into sophisticated autonomous agents capable of complex software development tasks, evaluating their real-world capabilities becomes critical. While existing benchmarks like LoCoBench~\cite{qiu2025locobench} assess long-context code understanding, they focus on single-turn evaluation and cannot capture the multi-turn interactive nature, tool usage patterns, and adaptive reasoning required by real-world coding agents. We introduce \textbf{LoCoBench-Agent}, a comprehensive evaluation framework specifically designed to assess LLM agents in realistic, long-context software engineering workflows. Our framework extends LoCoBench's 8,000 scenarios into interactive agent environments, enabling systematic evaluation of multi-turn conversations, tool usage efficiency, error recovery, and architectural consistency across extended development sessions. We also introduce an evaluation methodology with 9 metrics across comprehension and efficiency dimensions. Our framework provides agents with 8 specialized tools (file operations, search, code analysis) and evaluates them across context lengths ranging from 10K to 1M tokens, enabling precise assessment of long-context performance. Through systematic evaluation of state-of-the-art models, we reveal several key findings: (1) agents exhibit remarkable long-context robustness; (2) comprehension-efficiency trade-off exists with negative correlation, where thorough exploration increases comprehension but reduces efficiency; and (3) conversation efficiency varies dramatically across models, with strategic tool usage patterns differentiating high-performing agents. As the first long-context LLM agent benchmark for software engineering, LoCoBench-Agent establishes a rigorous foundation for measuring agent capabilities, identifying performance gaps, and advancing autonomous software development at scale.
Self-Improving LLM Agents at Test-Time
Oct 09, 2025



One paradigm of language model (LM) fine-tuning relies on creating large training datasets, under the assumption that high quantity and diversity will enable models to generalize to novel tasks after post-training. In practice, gathering large sets of data is inefficient, and training on them is prohibitively expensive; worse, there is no guarantee that the resulting model will handle complex scenarios or generalize better. Moreover, existing techniques rarely assess whether a training sample provides novel information or is redundant with the knowledge already acquired by the model, resulting in unnecessary costs. In this work, we explore a new test-time self-improvement method to create more effective and generalizable agentic LMs on-the-fly. The proposed algorithm can be summarized in three steps: (i) first it identifies the samples that model struggles with (self-awareness), (ii) then generates similar examples from detected uncertain samples (self-data augmentation), and (iii) uses these newly generated samples at test-time fine-tuning (self-improvement). We study two variants of this approach: Test-Time Self-Improvement (TT-SI), where the same model generates additional training examples from its own uncertain cases and then learns from them, and contrast this approach with Test-Time Distillation (TT-D), where a stronger model generates similar examples for uncertain cases, enabling student to adapt using distilled supervision. Empirical evaluations across different agent benchmarks demonstrate that TT-SI improves the performance with +5.48% absolute accuracy gain on average across all benchmarks and surpasses other standard learning methods, yet using 68x less training samples. Our findings highlight the promise of TT-SI, demonstrating the potential of self-improvement algorithms at test-time as a new paradigm for building more capable agents toward self-evolution.
Veri-R1: Toward Precise and Faithful Claim Verification via Online Reinforcement Learning
Oct 02, 2025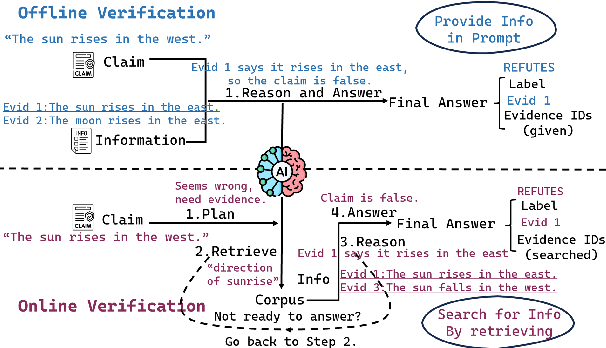
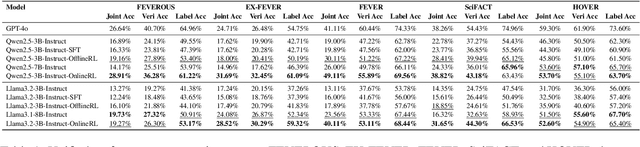
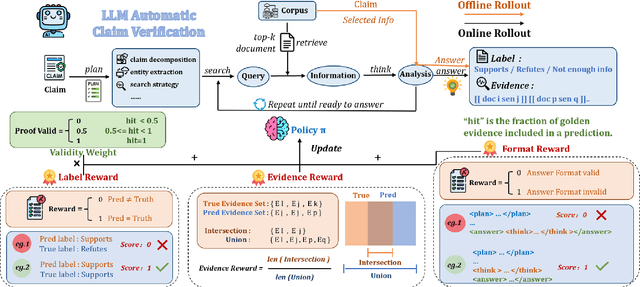

Claim verification with large language models (LLMs) has recently attracted considerable attention, owing to their superior reasoning capabilities and transparent verification pathways compared to traditional answer-only judgments. Online claim verification requires iterative evidence retrieval and reasoning, yet existing approaches mainly rely on prompt engineering or predesigned reasoning workflows without offering a unified training paradigm to improve necessary skills. Therefore, we introduce Veri-R1, an online reinforcement learning (RL) framework that enables an LLM to interact with a search engine and to receive reward signals that explicitly shape its planning, retrieval, and reasoning behaviors. The dynamic interaction between models and retrieval systems more accurately reflects real-world verification scenarios and fosters comprehensive verification skills. Empirical results show that Veri-R1 improves joint accuracy by up to 30% and doubles evidence score, often surpassing larger-scale counterparts. Ablation studies further reveal the impact of reward components and the link between output logits and label accuracy. Our results highlight the effectiveness of online RL for precise and faithful claim verification and provide a foundation for future research. We release our code to support community progress in LLM empowered claim verification.
LoCoBench: A Benchmark for Long-Context Large Language Models in Complex Software Engineering
Sep 11, 2025



The emergence of long-context language models with context windows extending to millions of tokens has created new opportunities for sophisticated code understanding and software development evaluation. We propose LoCoBench, a comprehensive benchmark specifically designed to evaluate long-context LLMs in realistic, complex software development scenarios. Unlike existing code evaluation benchmarks that focus on single-function completion or short-context tasks, LoCoBench addresses the critical evaluation gap for long-context capabilities that require understanding entire codebases, reasoning across multiple files, and maintaining architectural consistency across large-scale software systems. Our benchmark provides 8,000 evaluation scenarios systematically generated across 10 programming languages, with context lengths spanning 10K to 1M tokens, a 100x variation that enables precise assessment of long-context performance degradation in realistic software development settings. LoCoBench introduces 8 task categories that capture essential long-context capabilities: architectural understanding, cross-file refactoring, multi-session development, bug investigation, feature implementation, code comprehension, integration testing, and security analysis. Through a 5-phase pipeline, we create diverse, high-quality scenarios that challenge LLMs to reason about complex codebases at unprecedented scale. We introduce a comprehensive evaluation framework with 17 metrics across 4 dimensions, including 8 new evaluation metrics, combined in a LoCoBench Score (LCBS). Our evaluation of state-of-the-art long-context models reveals substantial performance gaps, demonstrating that long-context understanding in complex software development represents a significant unsolved challenge that demands more attention. LoCoBench is released at: https://github.com/SalesforceAIResearch/LoCoBench.