 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimSD: Simple Speculative Decoding in Diffusion Language Models
Jun 01, 2026Diffusion large language models (dLLMs) have recently emerged as a promising alternative to autoregressive (AR) LLMs, offering faster inference through parallel or blockwise decoding. However, their masked language modeling formulation remains incompatible with standard token-level speculative decoding, one of the most effective acceleration techniques for AR models. In AR decoding, the causal mask preserves temporally valid token-level contexts, enabling a target model to verify multiple drafted tokens in a single forward pass. In contrast, dLLMs rely on mask tokens and bidirectional attention, causing the effective context to change across denoising steps and preventing direct token-level speculative verification. To bridge this gap, we propose a simple but effective speculative decoding algorithm for diffusion language models, named SimSD, which mainly adopts a plug-and-play masking strategy that equips dLLMs with temporally valid token-level contexts for speculative decoding. Our method explicitly introduces reference tokens from draft-model predictions and designs an attention mask that regulates their interaction with current-step tokens, allowing dLLMs to compute valid logits for drafted tokens in a single forward pass. This restores the key verification ability provided by causal masking in AR models while preserving the parallel decoding advantages of dLLMs. The proposed method is training-free and can be flexibly integrated with other acceleration techniques such as KV cache and blockwise decoding. Experiments on SDAR-family dLLMs across four benchmarks show that our method achieves up to 7.46x higher decoding throughput while maintaining and even improving average generation quality.
Cog-DRIFT: Exploration on Adaptively Reformulated Instances Enables Learning from Hard Reasoning Problems
Apr 06, 2026Reinforcement learning from verifiable rewards (RLVR) has improved the reasoning abilities of LLMs, yet a fundamental limitation remains: models cannot learn from problems that are too difficult to solve under their current policy, as these yield no meaningful reward signal. We propose a simple yet effective solution based on task reformulation. We transform challenging open-ended problems into cognitively simpler variants -- such as multiple-choice and cloze formats -- that preserve the original answer while reducing the effective search space and providing denser learning signals. These reformulations span a spectrum from discriminative to generative tasks, which we exploit to bootstrap learning: models first learn from structured, easier formats, and this knowledge transfers back to improve performance on the original open-ended problems. Building on this insight, we introduce Cog-DRIFT, a framework that constructs reformulated variants and organizes them into an adaptive curriculum based on difficulty. Training progresses from easier to harder formats, enabling the model to learn from problems that previously yielded zero signal under standard RL post-training. Cog-DRIFT not only improves on the originally unsolvable hard problems (absolute +10.11% for Qwen and +8.64% for Llama) but also generalizes well to other held-out datasets. Across 2 models and 6 reasoning benchmarks, our method consistently outperforms standard GRPO and strong guided-exploration baselines. On average, Cog-DRIFT shows +4.72% (Qwen) and +3.23% (Llama) improvements over the second-best baseline. We further show that Cog-DRIFT improves pass@k at test time, and the curriculum improves sample efficiency. Overall, our results highlight task reformulation and curriculum learning as an effective paradigm for overcoming the exploration barrier in LLM post-training.
Steer2Adapt: Dynamically Composing Steering Vectors Elicits Efficient Adaptation of LLMs
Feb 07, 2026Activation steering has emerged as a promising approach for efficiently adapting large language models (LLMs) to downstream behaviors. However, most existing steering methods rely on a single static direction per task or concept, making them inflexible under task variation and inadequate for complex tasks that require multiple coordinated capabilities. To address this limitation, we propose STEER2ADAPT, a lightweight framework that adapts LLMs by composing steering vectors rather than learning new ones from scratch. In many domains (e.g., reasoning or safety), tasks share a small set of underlying concept dimensions. STEER2ADAPT captures these dimensions as a reusable, low-dimensional semantic prior subspace, and adapts to new tasks by dynamically discovering a linear combination of basis vectors from only a handful of examples. Experiments across 9 tasks and 3 models in both reasoning and safety domains demonstrate the effectiveness of STEER2ADAPT, achieving an average improvement of 8.2%. Extensive analyses further show that STEER2ADAPT is a data-efficient, stable, and transparent inference-time adaptation method for LLMs.
Finish First, Perfect Later: Test-Time Token-Level Cross-Validation for Diffusion Large Language Models
Oct 06, 2025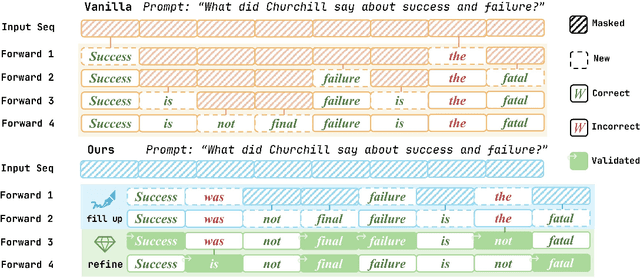
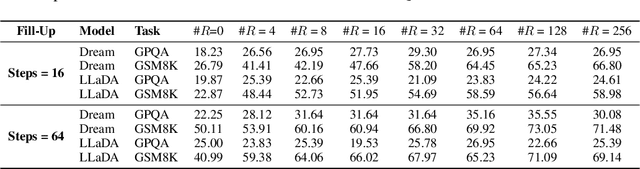
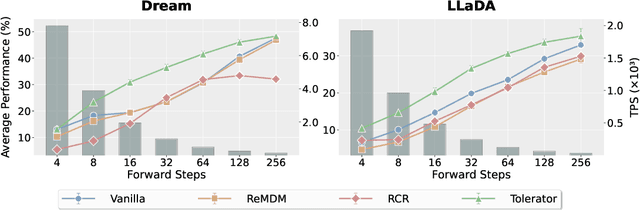
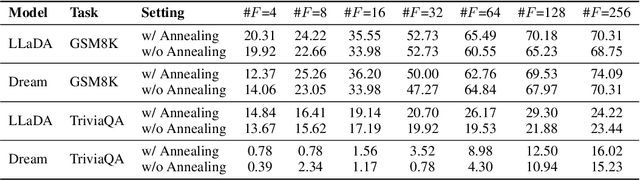
Diffusion large language models (dLLMs) have recently emerged as a promising alternative to autoregressive (AR) models, offering advantages such as accelerated parallel decoding and bidirectional context modeling. However, the vanilla decoding strategy in discrete dLLMs suffers from a critical limitation: once a token is accepted, it can no longer be revised in subsequent steps. As a result, early mistakes persist across iterations, harming both intermediate predictions and final output quality. To address this issue, we propose Tolerator (Token-Level Cross-Validation Refinement), a training-free decoding strategy that leverages cross-validation among predicted tokens. Unlike existing methods that follow a single progressive unmasking procedure, Tolerator introduces a two-stage process: (i) sequence fill-up and (ii) iterative refinement by remasking and decoding a subset of tokens while treating the remaining as context. This design enables previously accepted tokens to be reconsidered and corrected when necessary, leading to more reliable diffusion decoding outputs. We evaluate Tolerator on five standard benchmarks covering language understanding, code generation, and mathematics. Experiments show that our method achieves consistent improvements over the baselines under the same computational budget. These findings suggest that decoding algorithms are crucial to realizing the full potential of diffusion large language models. Code and data are publicly available.
Topic Coverage-based Demonstration Retrieval for In-Context Learning
Sep 15, 2025The effectiveness of in-context learning relies heavily on selecting demonstrations that provide all the necessary information for a given test input. To achieve this, it is crucial to identify and cover fine-grained knowledge requirements. However, prior methods often retrieve demonstrations based solely on embedding similarity or generation probability, resulting in irrelevant or redundant examples. In this paper, we propose TopicK, a topic coverage-based retrieval framework that selects demonstrations to comprehensively cover topic-level knowledge relevant to both the test input and the model. Specifically, TopicK estimates the topics required by the input and assesses the model's knowledge on those topics. TopicK then iteratively selects demonstrations that introduce previously uncovered required topics, in which the model exhibits low topical knowledge. We validate the effectiveness of TopicK through extensive experiments across various datasets and both open- and closed-source LLMs. Our source code is available at https://github.com/WonbinKweon/TopicK_EMNLP2025.
Beyond True or False: Retrieval-Augmented Hierarchical Analysis of Nuanced Claims
Jun 12, 2025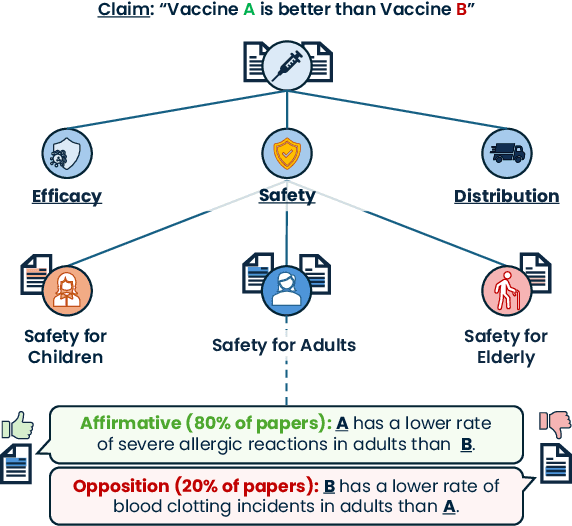
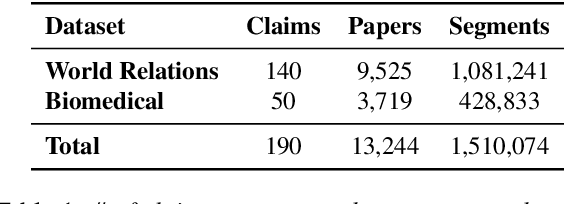
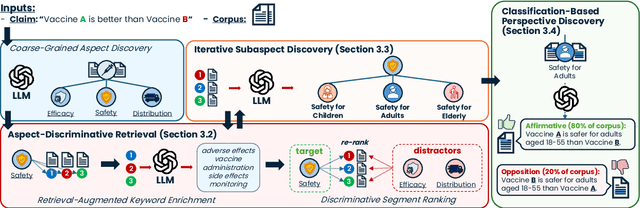
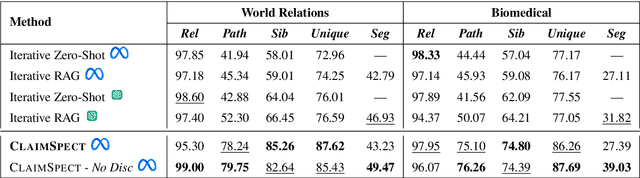
Claims made by individuals or entities are oftentimes nuanced and cannot be clearly labeled as entirely "true" or "false" -- as is frequently the case with scientific and political claims. However, a claim (e.g., "vaccine A is better than vaccine B") can be dissected into its integral aspects and sub-aspects (e.g., efficacy, safety, distribution), which are individually easier to validate. This enables a more comprehensive, structured response that provides a well-rounded perspective on a given problem while also allowing the reader to prioritize specific angles of interest within the claim (e.g., safety towards children). Thus, we propose ClaimSpect, a retrieval-augmented generation-based framework for automatically constructing a hierarchy of aspects typically considered when addressing a claim and enriching them with corpus-specific perspectives. This structure hierarchically partitions an input corpus to retrieve relevant segments, which assist in discovering new sub-aspects. Moreover, these segments enable the discovery of varying perspectives towards an aspect of the claim (e.g., support, neutral, or oppose) and their respective prevalence (e.g., "how many biomedical papers believe vaccine A is more transportable than B?"). We apply ClaimSpect to a wide variety of real-world scientific and political claims featured in our constructed dataset, showcasing its robustness and accuracy in deconstructing a nuanced claim and representing perspectives within a corpus. Through real-world case studies and human evaluation, we validate its effectiveness over multiple baselines.
LLM-Based Compact Reranking with Document Features for Scientific Retrieval
May 19, 2025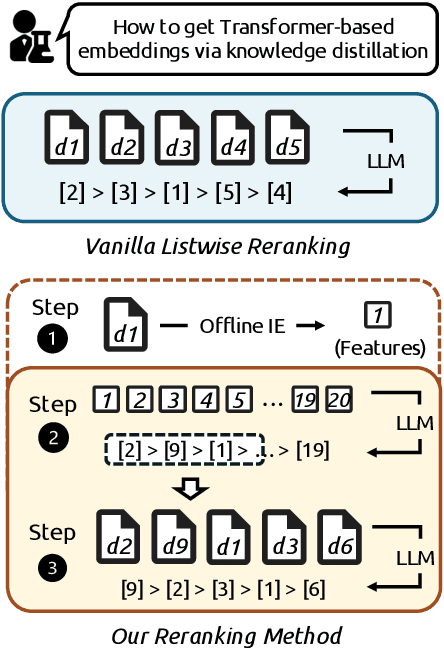
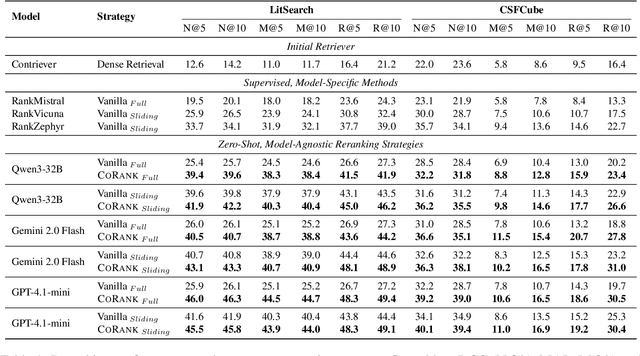

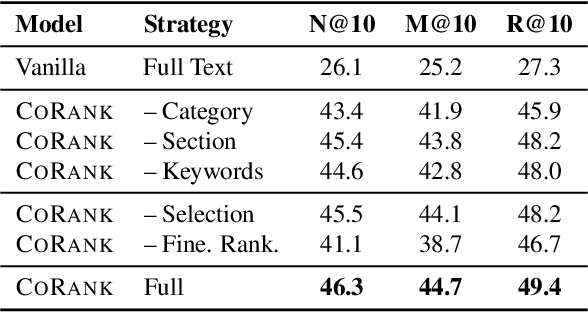
Scientific retrieval is essential for advancing academic discovery. Within this process, document reranking plays a critical role by refining first-stage retrieval results. However, large language model (LLM) listwise reranking faces unique challenges in the scientific domain. First-stage retrieval is often suboptimal in the scientific domain, so relevant documents are ranked lower. Moreover, conventional listwise reranking uses the full text of candidate documents in the context window, limiting the number of candidates that can be considered. As a result, many relevant documents are excluded before reranking, which constrains overall retrieval performance. To address these challenges, we explore compact document representations based on semantic features such as categories, sections, and keywords, and propose a training-free, model-agnostic reranking framework for scientific retrieval called CoRank. The framework involves three stages: (i) offline extraction of document-level features, (ii) coarse reranking using these compact representations, and (iii) fine-grained reranking on full texts of the top candidates from stage (ii). This hybrid design provides a high-level abstraction of document semantics, expands candidate coverage, and retains critical details required for precise ranking. Experiments on LitSearch and CSFCube show that CoRank significantly improves reranking performance across different LLM backbones, increasing nDCG@10 from 32.0 to 39.7. Overall, these results highlight the value of information extraction for reranking in scientific retrieval.
Distance between Relevant Information Pieces Causes Bias in Long-Context LLMs
Oct 18, 2024



Positional bias in large language models (LLMs) hinders their ability to effectively process long inputs. A prominent example is the "lost in the middle" phenomenon, where LLMs struggle to utilize relevant information situated in the middle of the input. While prior research primarily focuses on single pieces of relevant information, real-world applications often involve multiple relevant information pieces. To bridge this gap, we present LongPiBench, a benchmark designed to assess positional bias involving multiple pieces of relevant information. Thorough experiments are conducted with five commercial and six open-source models. These experiments reveal that while most current models are robust against the "lost in the middle" issue, there exist significant biases related to the spacing of relevant information pieces. These findings highlight the importance of evaluating and reducing positional biases to advance LLM's capabilities.
DebugBench: Evaluating Debugging Capability of Large Language Models
Jan 11, 2024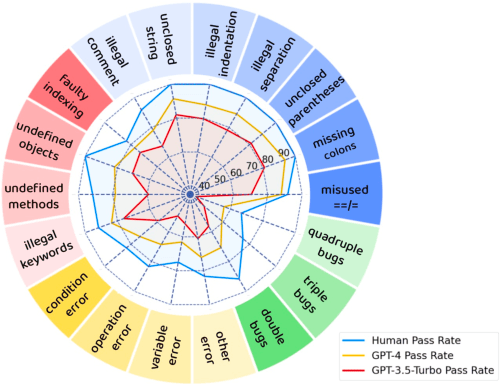

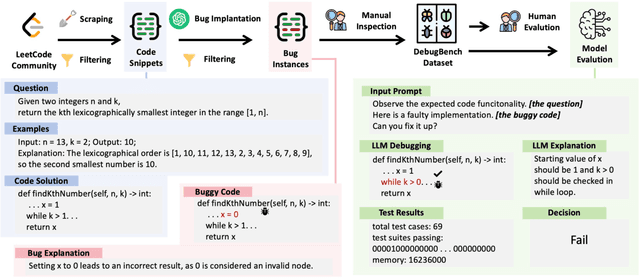

Large Language Models (LLMs) have demonstrated exceptional coding capability. However, as another critical component of programming proficiency, the debugging capability of LLMs remains relatively unexplored. Previous evaluations of LLMs' debugging ability are significantly limited by the risk of data leakage, the scale of the dataset, and the variety of tested bugs. To overcome these deficiencies, we introduce `DebugBench', an LLM debugging benchmark consisting of 4,253 instances. It covers four major bug categories and 18 minor types in C++, Java, and Python. To construct DebugBench, we collect code snippets from the LeetCode community, implant bugs into source data with GPT-4, and assure rigorous quality checks. We evaluate two commercial and three open-source models in a zero-shot scenario. We find that (1) while closed-source models like GPT-4 exhibit inferior debugging performance compared to humans, open-source models such as Code Llama fail to attain any pass rate scores; (2) the complexity of debugging notably fluctuates depending on the bug category; (3) incorporating runtime feedback has a clear impact on debugging performance which is not always helpful. As an extension, we also compare LLM debugging and code generation, revealing a strong correlation between them for closed-source models. These findings will benefit the development of LLMs in debugging.
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Jul 31, 2023Despite the advancements of open-source large language models (LLMs) and their variants, e.g., LLaMA and Vicuna, they remain significantly limited in performing higher-level tasks, such as following human instructions to use external tools (APIs). This is because current instruction tuning largely focuses on basic language tasks instead of the tool-use domain. This is in contrast to state-of-the-art (SOTA) LLMs, e.g., ChatGPT, which have demonstrated excellent tool-use capabilities but are unfortunately closed source. To facilitate tool-use capabilities within open-source LLMs, we introduce ToolLLM, a general tool-use framework of data construction, model training and evaluation. We first present ToolBench, an instruction-tuning dataset for tool use, which is created automatically using ChatGPT. Specifically, we collect 16,464 real-world RESTful APIs spanning 49 categories from RapidAPI Hub, then prompt ChatGPT to generate diverse human instructions involving these APIs, covering both single-tool and multi-tool scenarios. Finally, we use ChatGPT to search for a valid solution path (chain of API calls) for each instruction. To make the searching process more efficient, we develop a novel depth-first search-based decision tree (DFSDT), enabling LLMs to evaluate multiple reasoning traces and expand the search space. We show that DFSDT significantly enhances the planning and reasoning capabilities of LLMs. For efficient tool-use assessment, we develop an automatic evaluator: ToolEval. We fine-tune LLaMA on ToolBench and obtain ToolLLaMA. Our ToolEval reveals that ToolLLaMA demonstrates a remarkable ability to execute complex instructions and generalize to unseen APIs, and exhibits comparable performance to ChatGPT. To make the pipeline more practical, we devise a neural API retriever to recommend appropriate APIs for each instruction, negating the need for manual API selection.