 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtomMem : Learnable Dynamic Agentic Memory with Atomic Memory Operation
Jan 13, 2026Equipping agents with memory is essential for solving real-world long-horizon problems. However, most existing agent memory mechanisms rely on static and hand-crafted workflows. This limits the performance and generalization ability of these memory designs, which highlights the need for a more flexible, learning-based memory framework. In this paper, we propose AtomMem, which reframes memory management as a dynamic decision-making problem. We deconstruct high-level memory processes into fundamental atomic CRUD (Create, Read, Update, Delete) operations, transforming the memory workflow into a learnable decision process. By combining supervised fine-tuning with reinforcement learning, AtomMem learns an autonomous, task-aligned policy to orchestrate memory behaviors tailored to specific task demands. Experimental results across 3 long-context benchmarks demonstrate that the trained AtomMem-8B consistently outperforms prior static-workflow memory methods. Further analysis of training dynamics shows that our learning-based formulation enables the agent to discover structured, task-aligned memory management strategies, highlighting a key advantage over predefined routines.
MSDformer: Multi-scale Discrete Transformer For Time Series Generation
May 20, 2025Discrete Token Modeling (DTM), which employs vector quantization techniques, has demonstrated remarkable success in modeling non-natural language modalities, particularly in time series generation. While our prior work SDformer established the first DTM-based framework to achieve state-of-the-art performance in this domain, two critical limitations persist in existing DTM approaches: 1) their inability to capture multi-scale temporal patterns inherent to complex time series data, and 2) the absence of theoretical foundations to guide model optimization. To address these challenges, we proposes a novel multi-scale DTM-based time series generation method, called Multi-Scale Discrete Transformer (MSDformer). MSDformer employs a multi-scale time series tokenizer to learn discrete token representations at multiple scales, which jointly characterize the complex nature of time series data. Subsequently, MSDformer applies a multi-scale autoregressive token modeling technique to capture the multi-scale patterns of time series within the discrete latent space. Theoretically, we validate the effectiveness of the DTM method and the rationality of MSDformer through the rate-distortion theorem. Comprehensive experiments demonstrate that MSDformer significantly outperforms state-of-the-art methods. Both theoretical analysis and experimental results demonstrate that incorporating multi-scale information and modeling multi-scale patterns can substantially enhance the quality of generated time series in DTM-based approaches. The code will be released upon acceptance.
ToLeaP: Rethinking Development of Tool Learning with Large Language Models
May 17, 2025
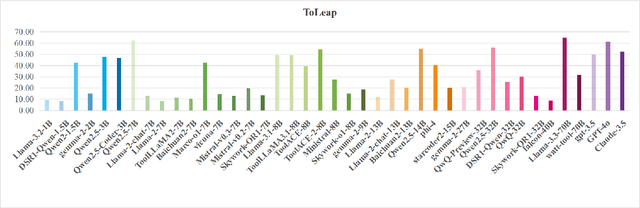
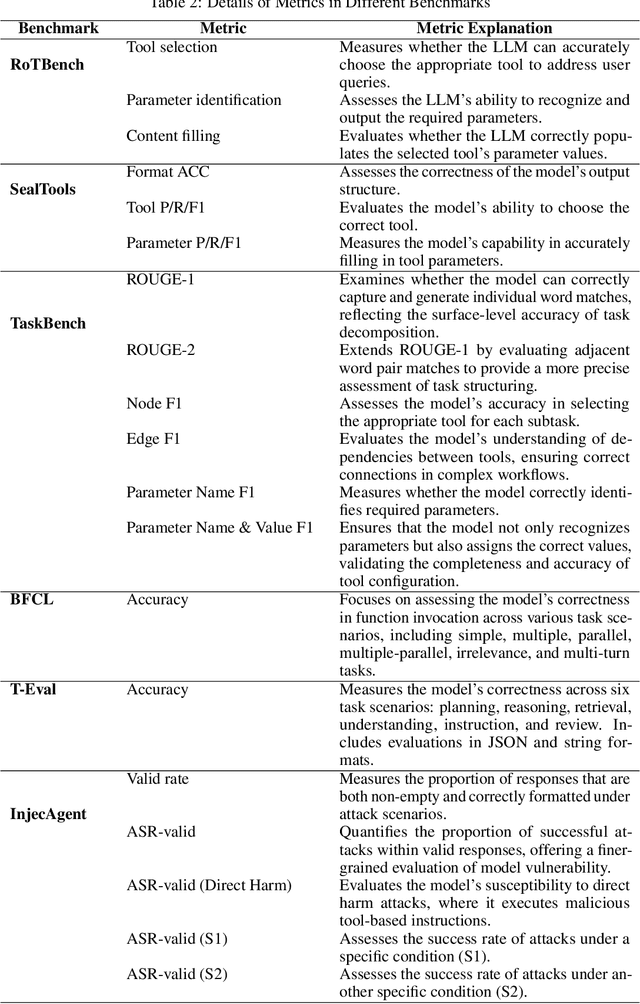
Tool learning, which enables large language models (LLMs) to utilize external tools effectively, has garnered increasing attention for its potential to revolutionize productivity across industries. Despite rapid development in tool learning, key challenges and opportunities remain understudied, limiting deeper insights and future advancements. In this paper, we investigate the tool learning ability of 41 prevalent LLMs by reproducing 33 benchmarks and enabling one-click evaluation for seven of them, forming a Tool Learning Platform named ToLeaP. We also collect 21 out of 33 potential training datasets to facilitate future exploration. After analyzing over 3,000 bad cases of 41 LLMs based on ToLeaP, we identify four main critical challenges: (1) benchmark limitations induce both the neglect and lack of (2) autonomous learning, (3) generalization, and (4) long-horizon task-solving capabilities of LLMs. To aid future advancements, we take a step further toward exploring potential directions, namely (1) real-world benchmark construction, (2) compatibility-aware autonomous learning, (3) rationale learning by thinking, and (4) identifying and recalling key clues. The preliminary experiments demonstrate their effectiveness, highlighting the need for further research and exploration.
AC-Reason: Towards Theory-Guided Actual Causality Reasoning with Large Language Models
May 13, 2025Actual causality (AC), a fundamental aspect of causal reasoning (CR), is responsible for attribution and responsibility assignment in real-world scenarios. However, existing LLM-based methods lack grounding in formal AC theory, resulting in limited interpretability. Therefore, we propose AC-Reason, a semi-formal reasoning framework that identifies causally relevant events within an AC scenario, infers the values of their formal causal factors (e.g., sufficiency, necessity, and normality), and answers AC queries via a theory-guided algorithm with explanations. While AC-Reason does not explicitly construct a causal graph, it operates over variables in the underlying causal structure to support principled reasoning. To enable comprehensive evaluation, we introduce AC-Bench, a new benchmark built upon and substantially extending Big-Bench Hard Causal Judgment (BBH-CJ). AC-Bench comprises ~1K carefully annotated samples, each with detailed reasoning steps and focuses solely on actual causation. The case study shows that synthesized samples in AC-Bench present greater challenges for LLMs. Extensive experiments on BBH-CJ and AC-Bench show that AC-Reason consistently improves LLM performance over baselines. On BBH-CJ, all tested LLMs surpass the average human rater accuracy of 69.60%, with GPT-4 + AC-Reason achieving 75.04%. On AC-Bench, GPT-4 + AC-Reason again achieves the highest accuracy of 71.82%. AC-Bench further enables fine-grained analysis of reasoning faithfulness, revealing that only Qwen-2.5-72B-Instruct, Claude-3.5-Sonnet, and GPT-4o exhibit faithful reasoning, whereas GPT-4 tends to exploit shortcuts. Finally, our ablation study proves that integrating AC theory into LLMs is highly effective, with the proposed algorithm contributing the most significant performance gains.
2D-Curri-DPO: Two-Dimensional Curriculum Learning for Direct Preference Optimization
Apr 10, 2025

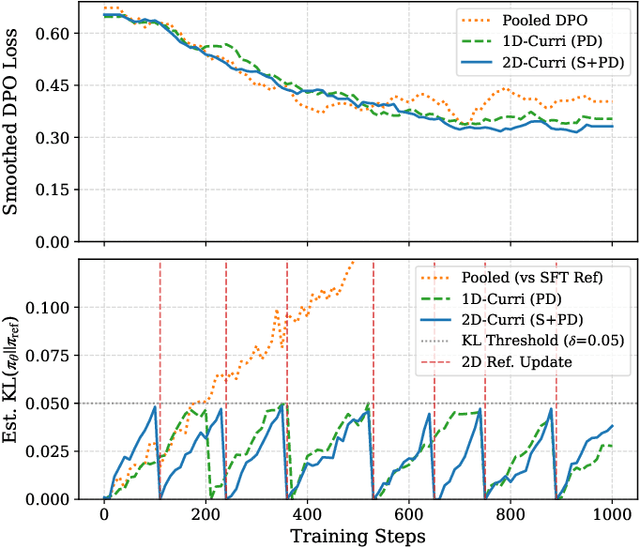
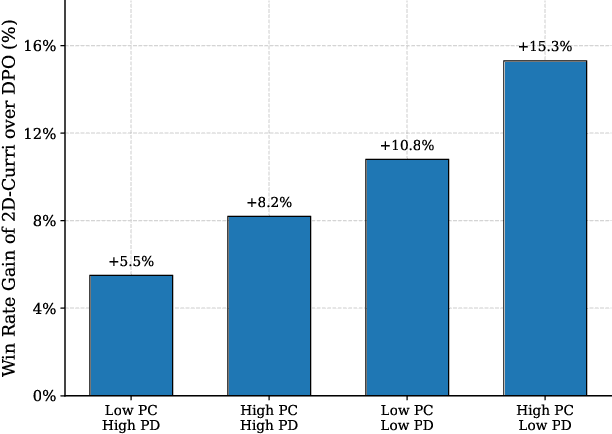
Aligning large language models with human preferences is crucial for their safe deployment. While Direct Preference Optimization (DPO) offers an efficient alternative to reinforcement learning from human feedback, traditional DPO methods are limited by their reliance on single preference pairs. Recent work like Curriculum-DPO integrates multiple pairs using a one-dimensional difficulty curriculum based on pairwise distinguishability (PD), but overlooks the complexity of the input prompt itself. To address this, we propose 2D-Curri-DPO, a novel framework employing a two-dimensional curriculum that jointly models Prompt Complexity (PC) and Pairwise Distinguishability. This framework introduces dual difficulty metrics to quantify prompt semantic complexity and response preference clarity, defines a curriculum strategy space encompassing multiple selectable strategies for task adaptation, and incorporates a KL-divergence-based adaptive mechanism for dynamic reference model updates to enhance training stability. Comprehensive experiments demonstrate that 2D-Curri-DPO significantly outperforms standard DPO and prior curriculum methods across multiple benchmarks, including MT-Bench, Vicuna Bench, and WizardLM. Our approach achieves state-of-the-art performance on challenging test sets like UltraFeedback. Ablation studies confirm the benefits of the 2D structure and adaptive mechanisms, while analysis provides guidance for strategy selection. These findings demonstrate that effective alignment requires modeling both prompt complexity and pairwise distinguishability, establishing adaptive, multi-dimensional curriculum learning as a powerful and interpretable new paradigm for preference-based language model optimization.
Learning to Generate Structured Output with Schema Reinforcement Learning
Feb 26, 2025This study investigates the structured generation capabilities of large language models (LLMs), focusing on producing valid JSON outputs against a given schema. Despite the widespread use of JSON in integrating language models with programs, there is a lack of comprehensive analysis and benchmarking of these capabilities. We explore various aspects of JSON generation, such as structure understanding, escaping, and natural language description, to determine how to assess and enable LLMs to generate valid responses. Building upon this, we propose SchemaBench features around 40K different JSON schemas to obtain and assess models' abilities in generating valid JSON. We find that the latest LLMs are still struggling to generate a valid JSON string. Moreover, we demonstrate that incorporating reinforcement learning with a Fine-grained Schema Validator can further enhance models' understanding of JSON schema, leading to improved performance. Our models demonstrate significant improvement in both generating JSON outputs and downstream tasks.
AgentRM: Enhancing Agent Generalization with Reward Modeling
Feb 25, 2025Existing LLM-based agents have achieved strong performance on held-in tasks, but their generalizability to unseen tasks remains poor. Hence, some recent work focus on fine-tuning the policy model with more diverse tasks to improve the generalizability. In this work, we find that finetuning a reward model to guide the policy model is more robust than directly finetuning the policy model. Based on this finding, we propose AgentRM, a generalizable reward model, to guide the policy model for effective test-time search. We comprehensively investigate three approaches to construct the reward model, including explicit reward modeling, implicit reward modeling and LLM-as-a-judge. We then use AgentRM to guide the answer generation with Best-of-N sampling and step-level beam search. On four types of nine agent tasks, AgentRM enhances the base policy model by $8.8$ points on average, surpassing the top general agent by $4.0$. Moreover, it demonstrates weak-to-strong generalization, yielding greater improvement of $12.6$ on LLaMA-3-70B policy model. As for the specializability, AgentRM can also boost a finetuned policy model and outperform the top specialized agent by $11.4$ on three held-in tasks. Further analysis verifies its effectiveness in test-time scaling. Codes will be released to facilitate the research in this area.
WorkflowLLM: Enhancing Workflow Orchestration Capability of Large Language Models
Nov 08, 2024Recent advancements in large language models (LLMs) have driven a revolutionary paradigm shift in process automation from Robotic Process Automation to Agentic Process Automation by automating the workflow orchestration procedure based on LLMs. However, existing LLMs (even the advanced OpenAI GPT-4o) are confined to achieving satisfactory capability in workflow orchestration. To address this limitation, we present WorkflowLLM, a data-centric framework elaborately designed to enhance the capability of LLMs in workflow orchestration. It first constructs a large-scale fine-tuning dataset WorkflowBench with 106,763 samples, covering 1,503 APIs from 83 applications across 28 categories. Specifically, the construction process can be divided into three phases: (1) Data Collection: we collect real-world workflow data from Apple Shortcuts and RoutineHub, transcribing them into Python-style code. We further equip them with generated hierarchical thought via ChatGPT. (2) Query Expansion: we prompt ChatGPT to generate more task queries to enrich the diversity and complexity of workflows. (3) Workflow Generation: we leverage an annotator model trained on collected data to generate workflows for synthesized queries. Finally, we merge the synthetic samples that pass quality confirmation with the collected samples to obtain the WorkflowBench. Based on WorkflowBench, we fine-tune Llama-3.1-8B to obtain WorkflowLlama. Our experiments show that WorkflowLlama demonstrates a strong capacity to orchestrate complex workflows, while also achieving notable generalization performance on previously unseen APIs. Additionally, WorkflowBench exhibits robust zero-shot generalization capabilities on an out-of-distribution task planning dataset, T-Eval. Our data and code are available at https://github.com/OpenBMB/WorkflowLLM.
Distance between Relevant Information Pieces Causes Bias in Long-Context LLMs
Oct 18, 2024



Positional bias in large language models (LLMs) hinders their ability to effectively process long inputs. A prominent example is the "lost in the middle" phenomenon, where LLMs struggle to utilize relevant information situated in the middle of the input. While prior research primarily focuses on single pieces of relevant information, real-world applications often involve multiple relevant information pieces. To bridge this gap, we present LongPiBench, a benchmark designed to assess positional bias involving multiple pieces of relevant information. Thorough experiments are conducted with five commercial and six open-source models. These experiments reveal that while most current models are robust against the "lost in the middle" issue, there exist significant biases related to the spacing of relevant information pieces. These findings highlight the importance of evaluating and reducing positional biases to advance LLM's capabilities.
Proactive Agent: Shifting LLM Agents from Reactive Responses to Active Assistance
Oct 16, 2024



Agents powered by large language models have shown remarkable abilities in solving complex tasks. However, most agent systems remain reactive, limiting their effectiveness in scenarios requiring foresight and autonomous decision-making. In this paper, we tackle the challenge of developing proactive agents capable of anticipating and initiating tasks without explicit human instructions. We propose a novel data-driven approach for this problem. Firstly, we collect real-world human activities to generate proactive task predictions. These predictions are then labeled by human annotators as either accepted or rejected. The labeled data is used to train a reward model that simulates human judgment and serves as an automatic evaluator of the proactiveness of LLM agents. Building on this, we develop a comprehensive data generation pipeline to create a diverse dataset, ProactiveBench, containing 6,790 events. Finally, we demonstrate that fine-tuning models with the proposed ProactiveBench can significantly elicit the proactiveness of LLM agents. Experimental results show that our fine-tuned model achieves an F1-Score of 66.47% in proactively offering assistance, outperforming all open-source and close-source models. These results highlight the potential of our method in creating more proactive and effective agent systems, paving the way for future advancements in human-agent collaboration.