 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIVA-GRPO: Enhancing Multimodal Reasoning through Difficulty-Adaptive Variant Advantage
Mar 01, 2026Reinforcement learning (RL) with group relative policy optimization (GRPO) has become a widely adopted approach for enhancing the reasoning capabilities of multimodal large language models (MLLMs). While GRPO enables long-chain reasoning without a critic, it often suffers from sparse rewards on difficult problems and advantage vanishing when group-level rewards are too consistent for overly easy or hard problems. Existing solutions (sample expansion, selective utilization, and indirect reward design) often fail to maintain enough variance in within-group reward distributions to yield clear optimization signals. To address this, we propose DIVA-GRPO, a difficulty-adaptive variant advantage method that adjusts variant difficulty distributions from a global perspective. DIVA-GRPO dynamically assesses problem difficulty, samples variants with appropriate difficulty levels, and calculates advantages across local and global groups using difficulty-weighted and normalized scaling. This alleviates reward sparsity and advantage vanishing while improving training stability. Extensive experiments on six reasoning benchmarks demonstrate that DIVA-GRPO outperforms existing approaches in training efficiency and reasoning performance. Code: https://github.com/Siaaaaaa1/DIVA-GRPO
A Survey of Vibe Coding with Large Language Models
Oct 14, 2025The advancement of large language models (LLMs) has catalyzed a paradigm shift from code generation assistance to autonomous coding agents, enabling a novel development methodology termed "Vibe Coding" where developers validate AI-generated implementations through outcome observation rather than line-by-line code comprehension. Despite its transformative potential, the effectiveness of this emergent paradigm remains under-explored, with empirical evidence revealing unexpected productivity losses and fundamental challenges in human-AI collaboration. To address this gap, this survey provides the first comprehensive and systematic review of Vibe Coding with large language models, establishing both theoretical foundations and practical frameworks for this transformative development approach. Drawing from systematic analysis of over 1000 research papers, we survey the entire vibe coding ecosystem, examining critical infrastructure components including LLMs for coding, LLM-based coding agent, development environment of coding agent, and feedback mechanisms. We first introduce Vibe Coding as a formal discipline by formalizing it through a Constrained Markov Decision Process that captures the dynamic triadic relationship among human developers, software projects, and coding agents. Building upon this theoretical foundation, we then synthesize existing practices into five distinct development models: Unconstrained Automation, Iterative Conversational Collaboration, Planning-Driven, Test-Driven, and Context-Enhanced Models, thus providing the first comprehensive taxonomy in this domain. Critically, our analysis reveals that successful Vibe Coding depends not merely on agent capabilities but on systematic context engineering, well-established development environments, and human-agent collaborative development models.
Learning Evolving Tools for Large Language Models
Oct 09, 2024



Tool learning enables large language models (LLMs) to interact with external tools and APIs, greatly expanding the application scope of LLMs. However, due to the dynamic nature of external environments, these tools and APIs may become outdated over time, preventing LLMs from correctly invoking tools. Existing research primarily focuses on static environments and overlooks this issue, limiting the adaptability of LLMs in real-world applications. In this paper, we propose ToolEVO, a novel framework designed to enhance the adaptive and reflective capabilities of LLMs against tool variability. By leveraging Monte Carlo Tree Search, ToolEVO facilitates active exploration and interaction of LLMs within dynamic environments, allowing for autonomous self-reflection and self-updating of tool usage based on environmental feedback. Additionally, we introduce ToolQA-D, a benchmark specifically designed to evaluate the impact of tool variability. Extensive experiments demonstrate the effectiveness and stability of our approach, highlighting the importance of adaptability to tool variability for effective tool learning.
M3GIA: A Cognition Inspired Multilingual and Multimodal General Intelligence Ability Benchmark
Jun 08, 2024

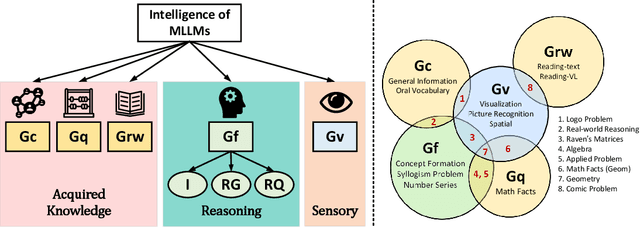

As recent multi-modality large language models (MLLMs) have shown formidable proficiency on various complex tasks, there has been increasing attention on debating whether these models could eventually mirror human intelligence. However, existing benchmarks mainly focus on evaluating solely on task performance, such as the accuracy of identifying the attribute of an object. Combining well-developed cognitive science to understand the intelligence of MLLMs beyond superficial achievements remains largely unexplored. To this end, we introduce the first cognitive-driven multi-lingual and multi-modal benchmark to evaluate the general intelligence ability of MLLMs, dubbed M3GIA. Specifically, we identify five key cognitive factors based on the well-recognized Cattell-Horn-Carrol (CHC) model of intelligence and propose a novel evaluation metric. In addition, since most MLLMs are trained to perform in different languages, a natural question arises: is language a key factor influencing the cognitive ability of MLLMs? As such, we go beyond English to encompass other languages based on their popularity, including Chinese, French, Spanish, Portuguese and Korean, to construct our M3GIA. We make sure all the data relevant to the cultural backgrounds are collected from their native context to avoid English-centric bias. We collected a significant corpus of data from human participants, revealing that the most advanced MLLM reaches the lower boundary of human intelligence in English. Yet, there remains a pronounced disparity in the other five languages assessed. We also reveals an interesting winner takes all phenomenon that are aligned with the discovery in cognitive studies. Our benchmark will be open-sourced, with the aspiration of facilitating the enhancement of cognitive capabilities in MLLMs.
Graph Domain Adaptation: Challenges, Progress and Prospects
Feb 01, 2024As graph representation learning often suffers from label scarcity problems in real-world applications, researchers have proposed graph domain adaptation (GDA) as an effective knowledge-transfer paradigm across graphs. In particular, to enhance model performance on target graphs with specific tasks, GDA introduces a bunch of task-related graphs as source graphs and adapts the knowledge learnt from source graphs to the target graphs. Since GDA combines the advantages of graph representation learning and domain adaptation, it has become a promising direction of transfer learning on graphs and has attracted an increasing amount of research interest in recent years. In this paper, we comprehensively overview the studies of GDA and present a detailed survey of recent advances. Specifically, we outline the research status and challenges, propose a taxonomy, introduce the details of representative works, and discuss the prospects. To the best of our knowledge, this paper is the first survey for graph domain adaptation. A detailed paper list is available at https://github.com/Skyorca/Awesome-Graph-Domain-Adaptation-Papers.
Causality and Independence Enhancement for Biased Node Classification
Oct 14, 2023



Most existing methods that address out-of-distribution (OOD) generalization for node classification on graphs primarily focus on a specific type of data biases, such as label selection bias or structural bias. However, anticipating the type of bias in advance is extremely challenging, and designing models solely for one specific type may not necessarily improve overall generalization performance. Moreover, limited research has focused on the impact of mixed biases, which are more prevalent and demanding in real-world scenarios. To address these limitations, we propose a novel Causality and Independence Enhancement (CIE) framework, applicable to various graph neural networks (GNNs). Our approach estimates causal and spurious features at the node representation level and mitigates the influence of spurious correlations through the backdoor adjustment. Meanwhile, independence constraint is introduced to improve the discriminability and stability of causal and spurious features in complex biased environments. Essentially, CIE eliminates different types of data biases from a unified perspective, without the need to design separate methods for each bias as before. To evaluate the performance under specific types of data biases, mixed biases, and low-resource scenarios, we conducted comprehensive experiments on five publicly available datasets. Experimental results demonstrate that our approach CIE not only significantly enhances the performance of GNNs but outperforms state-of-the-art debiased node classification methods.
OpenGDA: Graph Domain Adaptation Benchmark for Cross-network Learning
Jul 21, 2023



Graph domain adaptation models are widely adopted in cross-network learning tasks, with the aim of transferring labeling or structural knowledge. Currently, there mainly exist two limitations in evaluating graph domain adaptation models. On one side, they are primarily tested for the specific cross-network node classification task, leaving tasks at edge-level and graph-level largely under-explored. Moreover, they are primarily tested in limited scenarios, such as social networks or citation networks, lacking validation of model's capability in richer scenarios. As comprehensively assessing models could enhance model practicality in real-world applications, we propose a benchmark, known as OpenGDA. It provides abundant pre-processed and unified datasets for different types of tasks (node, edge, graph). They originate from diverse scenarios, covering web information systems, urban systems and natural systems. Furthermore, it integrates state-of-the-art models with standardized and end-to-end pipelines. Overall, OpenGDA provides a user-friendly, scalable and reproducible benchmark for evaluating graph domain adaptation models. The benchmark experiments highlight the challenges of applying GDA models to real-world applications with consistent good performance, and potentially provide insights to future research. As an emerging project, OpenGDA will be regularly updated with new datasets and models. It could be accessed from https://github.com/Skyorca/OpenGDA.