 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Evolving Tools for Large Language Models
Oct 09, 2024



Tool learning enables large language models (LLMs) to interact with external tools and APIs, greatly expanding the application scope of LLMs. However, due to the dynamic nature of external environments, these tools and APIs may become outdated over time, preventing LLMs from correctly invoking tools. Existing research primarily focuses on static environments and overlooks this issue, limiting the adaptability of LLMs in real-world applications. In this paper, we propose ToolEVO, a novel framework designed to enhance the adaptive and reflective capabilities of LLMs against tool variability. By leveraging Monte Carlo Tree Search, ToolEVO facilitates active exploration and interaction of LLMs within dynamic environments, allowing for autonomous self-reflection and self-updating of tool usage based on environmental feedback. Additionally, we introduce ToolQA-D, a benchmark specifically designed to evaluate the impact of tool variability. Extensive experiments demonstrate the effectiveness and stability of our approach, highlighting the importance of adaptability to tool variability for effective tool learning.
Reinforced MOOCs Concept Recommendation in Heterogeneous Information Networks
Apr 13, 2022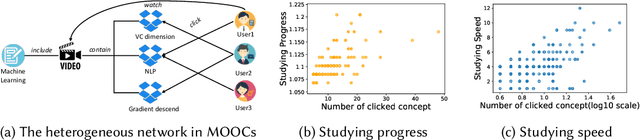


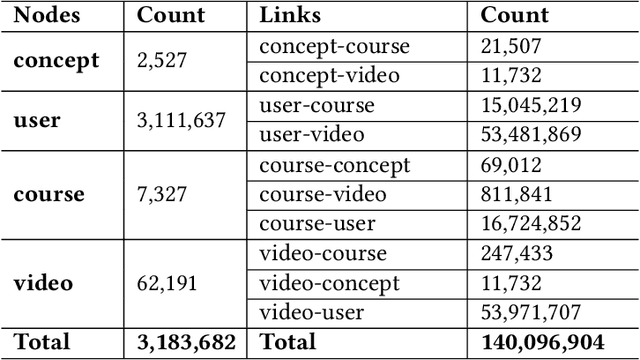
Massive open online courses (MOOCs), which provide a large-scale interactive participation and open access via the web, are becoming a modish way for online and distance education. To help users have a better study experience, many MOOC platforms have provided the services of recommending courses to users. However, we argue that directly recommending a course to users will ignore the expertise levels of different users. To fill this gap, this paper studies the problem of concept recommendation in a more fine-grained view. We propose a novel Heterogeneous Information Networks based Concept Recommender with Reinforcement Learning (HinCRec-RL) incorporated for concept recommendation in MOOCs. Specifically, we first formulate the concept recommendation in MOOCs as a reinforcement learning problem to better model the dynamic interaction among users and knowledge concepts. In addition, to mitigate the data sparsity issue which also exists in many other recommendation tasks, we consider a heterogeneous information network (HIN) among users, courses, videos and concepts, to better learn the semantic representation of users. In particular, we use the meta-paths on HIN to guide the propagation of users' preferences and propose a heterogeneous graph attention network to represent the meta-paths. To validate the effectiveness of our proposed approach, we conduct comprehensive experiments on a real-world dataset from XuetangX, a popular MOOC platform from China. The promising results show that our proposed approach can outperform other baselines.
GRAND+: Scalable Graph Random Neural Networks
Mar 12, 2022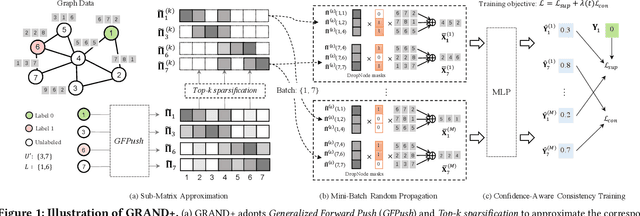
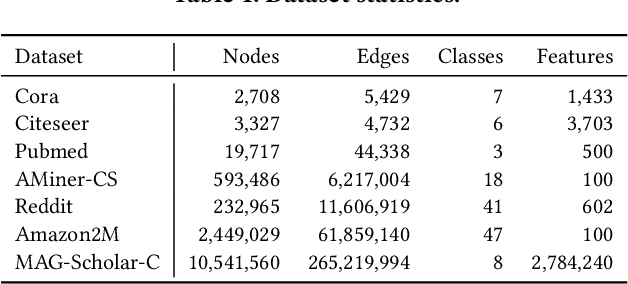
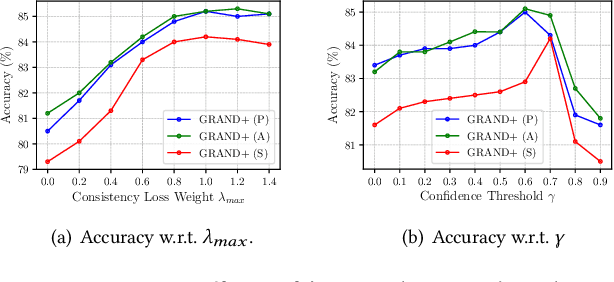

Graph neural networks (GNNs) have been widely adopted for semi-supervised learning on graphs. A recent study shows that the graph random neural network (GRAND) model can generate state-of-the-art performance for this problem. However, it is difficult for GRAND to handle large-scale graphs since its effectiveness relies on computationally expensive data augmentation procedures. In this work, we present a scalable and high-performance GNN framework GRAND+ for semi-supervised graph learning. To address the above issue, we develop a generalized forward push (GFPush) algorithm in GRAND+ to pre-compute a general propagation matrix and employ it to perform graph data augmentation in a mini-batch manner. We show that both the low time and space complexities of GFPush enable GRAND+ to efficiently scale to large graphs. Furthermore, we introduce a confidence-aware consistency loss into the model optimization of GRAND+, facilitating GRAND+'s generalization superiority. We conduct extensive experiments on seven public datasets of different sizes. The results demonstrate that GRAND+ 1) is able to scale to large graphs and costs less running time than existing scalable GNNs, and 2) can offer consistent accuracy improvements over both full-batch and scalable GNNs across all datasets.
Are we really making much progress? Revisiting, benchmarking, and refining heterogeneous graph neural networks
Dec 30, 2021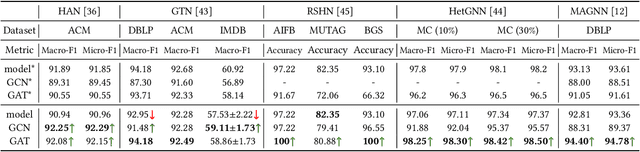
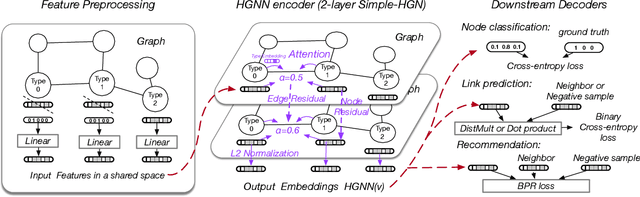
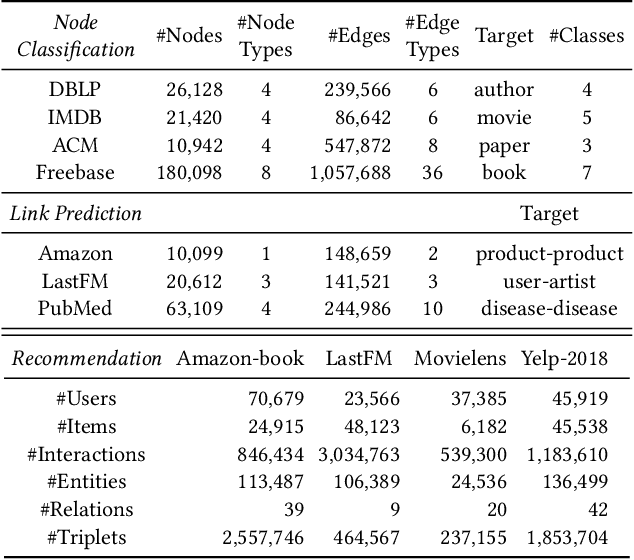
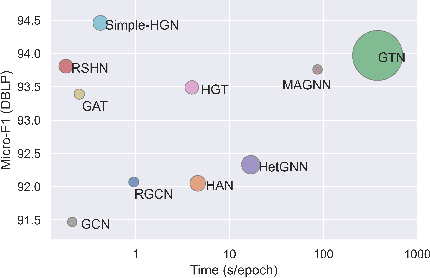
Heterogeneous graph neural networks (HGNNs) have been blossoming in recent years, but the unique data processing and evaluation setups used by each work obstruct a full understanding of their advancements. In this work, we present a systematical reproduction of 12 recent HGNNs by using their official codes, datasets, settings, and hyperparameters, revealing surprising findings about the progress of HGNNs. We find that the simple homogeneous GNNs, e.g., GCN and GAT, are largely underestimated due to improper settings. GAT with proper inputs can generally match or outperform all existing HGNNs across various scenarios. To facilitate robust and reproducible HGNN research, we construct the Heterogeneous Graph Benchmark (HGB), consisting of 11 diverse datasets with three tasks. HGB standardizes the process of heterogeneous graph data splits, feature processing, and performance evaluation. Finally, we introduce a simple but very strong baseline Simple-HGN--which significantly outperforms all previous models on HGB--to accelerate the advancement of HGNNs in the future.
Attentional Graph Convolutional Networks for Knowledge Concept Recommendation in MOOCs in a Heterogeneous View
Jun 23, 2020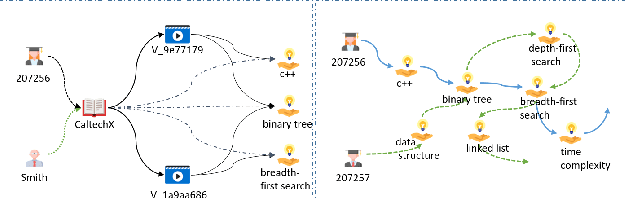
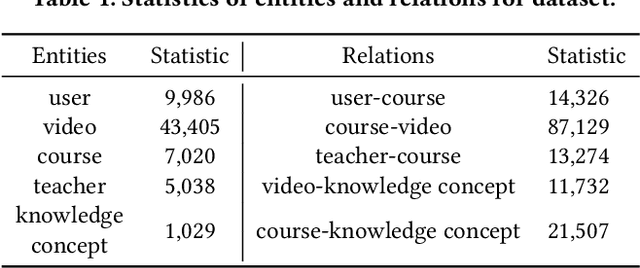
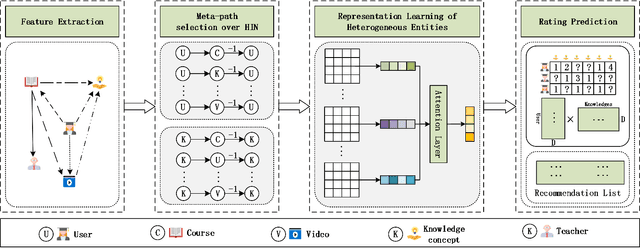
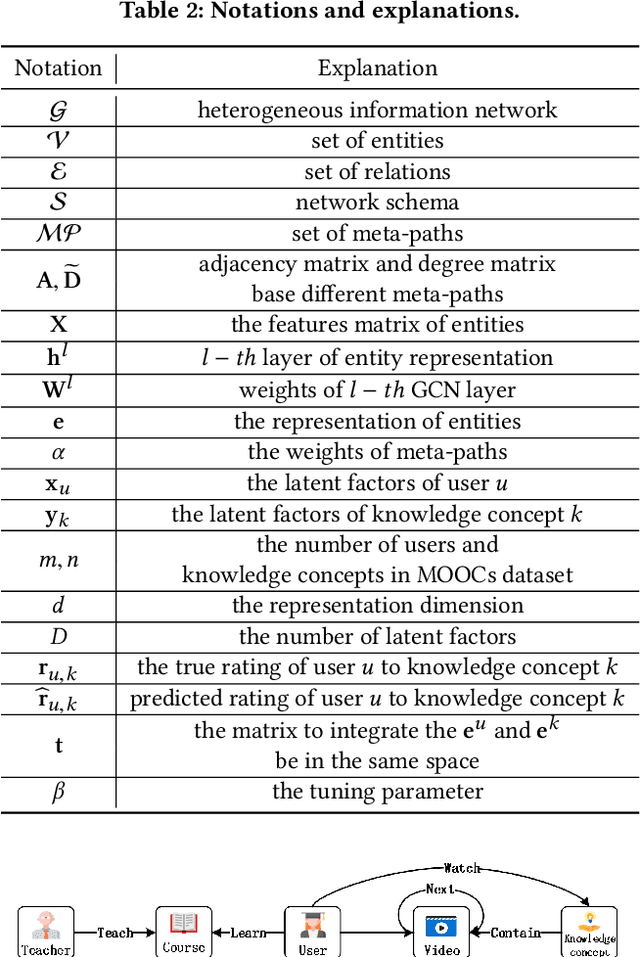
Massive open online courses are becoming a modish way for education, which provides a large-scale and open-access learning opportunity for students to grasp the knowledge. To attract students' interest, the recommendation system is applied by MOOCs providers to recommend courses to students. However, as a course usually consists of a number of video lectures, with each one covering some specific knowledge concepts, directly recommending courses overlook students'interest to some specific knowledge concepts. To fill this gap, in this paper, we study the problem of knowledge concept recommendation. We propose an end-to-end graph neural network-based approach calledAttentionalHeterogeneous Graph Convolutional Deep Knowledge Recommender(ACKRec) for knowledge concept recommendation in MOOCs. Like other recommendation problems, it suffers from sparsity issues. To address this issue, we leverage both content information and context information to learn the representation of entities via graph convolution network. In addition to students and knowledge concepts, we consider other types of entities (e.g., courses, videos, teachers) and construct a heterogeneous information network to capture the corresponding fruitful semantic relationships among different types of entities and incorporate them into the representation learning process. Specifically, we use meta-path on the HIN to guide the propagation of students' preferences. With the help of these meta-paths, the students' preference distribution with respect to a candidate knowledge concept can be captured. Furthermore, we propose an attention mechanism to adaptively fuse the context information from different meta-paths, in order to capture the different interests of different students. The promising experiment results show that the proposedACKRecis able to effectively recommend knowledge concepts to students pursuing online learning in MOOCs.
Graph Random Neural Network
May 22, 2020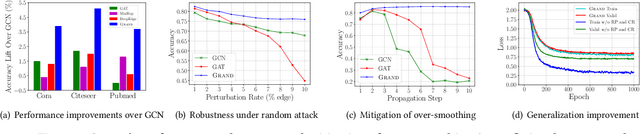
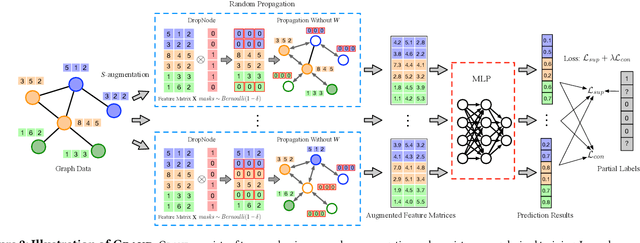
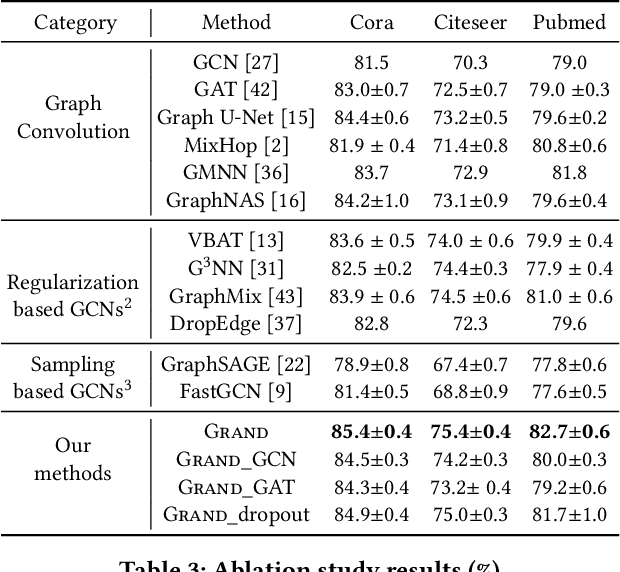
Graph neural networks (GNNs) have generalized deep learning methods into graph-structured data with promising performance on graph mining tasks. However, existing GNNs often meet complex graph structures with scarce labeled nodes and suffer from the limitations of non-robustness, over-smoothing, and overfitting. To address these issues, we propose a simple yet effective GNN framework---Graph Random Neural Network (Grand). Different from the deterministic propagation in existing GNNs, Grand adopts a random propagation strategy to enhance model robustness. This strategy also naturally enables Grand to decouple the propagation from feature transformation, reducing the risks of over-smoothing and overfitting. Moreover, random propagation acts as an efficient method for graph data augmentation. Based on this, we propose the consistency regularization for Grand by leveraging the distributional consistency of unlabeled nodes in multiple augmentations, improving the generalization capacity of the model. Extensive experiments on graph benchmark datasets suggest that Grand significantly outperforms state-of-the-art GNN baselines on semi-supervised graph learning tasks. Finally, we show that Grand mitigates the issues of over-smoothing and overfitting, and its performance is married with robustness.