 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIST: Learning to Index Spatio-Textual Data for Embedding based Spatial Keyword Queries
Mar 18, 2024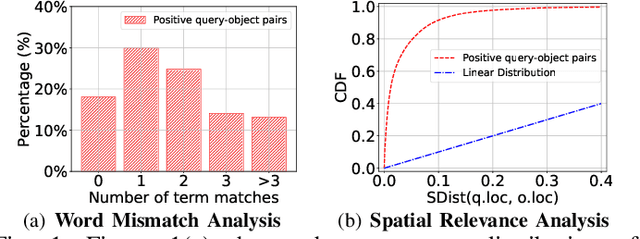
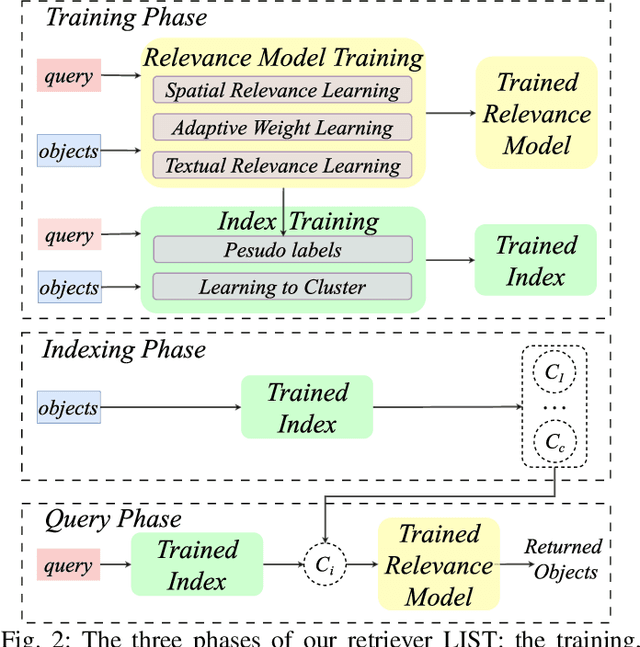
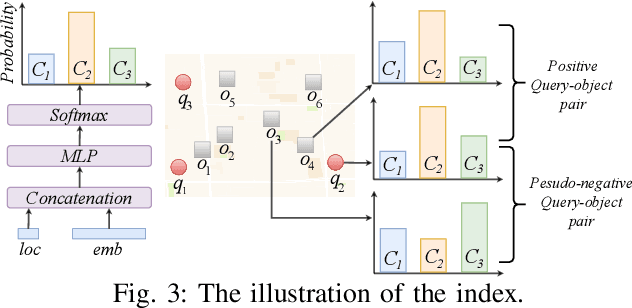
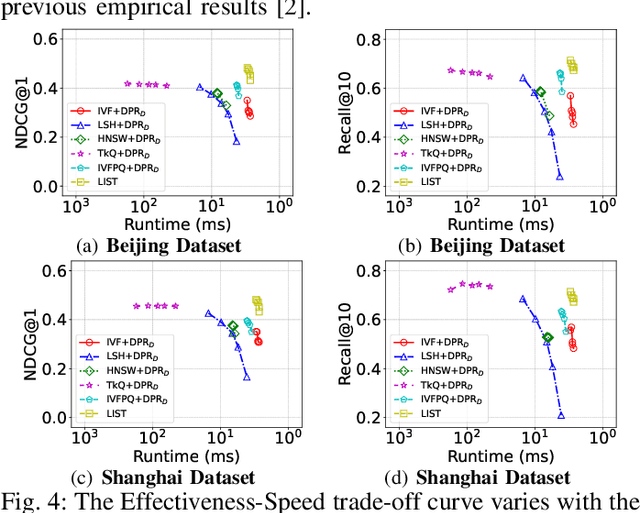
With the proliferation of spatio-textual data, Top-k KNN spatial keyword queries (TkQs), which return a list of objects based on a ranking function that evaluates both spatial and textual relevance, have found many real-life applications. Existing geo-textual indexes for TkQs use traditional retrieval models like BM25 to compute text relevance and usually exploit a simple linear function to compute spatial relevance, but its effectiveness is limited. To improve effectiveness, several deep learning models have recently been proposed, but they suffer severe efficiency issues. To the best of our knowledge, there are no efficient indexes specifically designed to accelerate the top-k search process for these deep learning models. To tackle these issues, we propose a novel technique, which Learns to Index the Spatio-Textual data for answering embedding based spatial keyword queries (called LIST). LIST is featured with two novel components. Firstly, we propose a lightweight and effective relevance model that is capable of learning both textual and spatial relevance. Secondly, we introduce a novel machine learning based Approximate Nearest Neighbor Search (ANNS) index, which utilizes a new learning-to-cluster technique to group relevant queries and objects together while separating irrelevant queries and objects. Two key challenges in building an effective and efficient index are the absence of high-quality labels and unbalanced clustering results. We develop a novel pseudo-label generation technique to address the two challenges. Experimental results show that LIST significantly outperforms state-of-the-art methods on effectiveness, with improvements up to 19.21% and 12.79% in terms of NDCG@1 and Recall@10, and is three orders of magnitude faster than the most effective baseline.
Should We Respect LLMs? A Cross-Lingual Study on the Influence of Prompt Politeness on LLM Performance
Feb 22, 2024



We investigate the impact of politeness levels in prompts on the performance of large language models (LLMs). Polite language in human communications often garners more compliance and effectiveness, while rudeness can cause aversion, impacting response quality. We consider that LLMs mirror human communication traits, suggesting they align with human cultural norms. We assess the impact of politeness in prompts on LLMs across English, Chinese, and Japanese tasks. We observed that impolite prompts often result in poor performance, but overly polite language does not guarantee better outcomes. The best politeness level is different according to the language. This phenomenon suggests that LLMs not only reflect human behavior but are also influenced by language, particularly in different cultural contexts. Our findings highlight the need to factor in politeness for cross-cultural natural language processing and LLM usage.
Model Degradation Hinders Deep Graph Neural Networks
Jun 09, 2022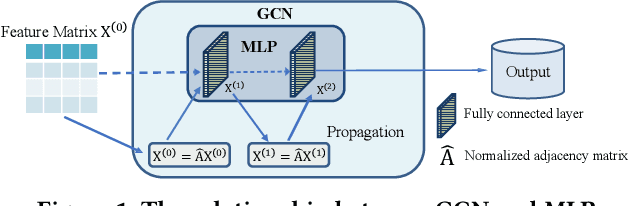
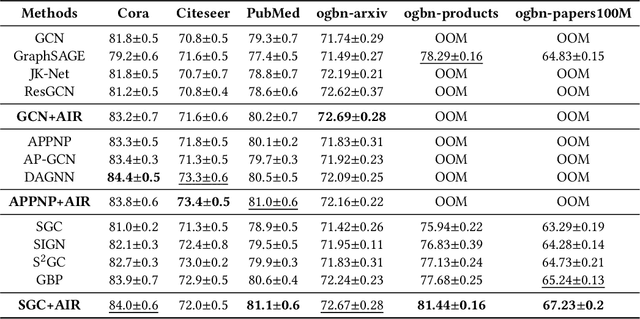
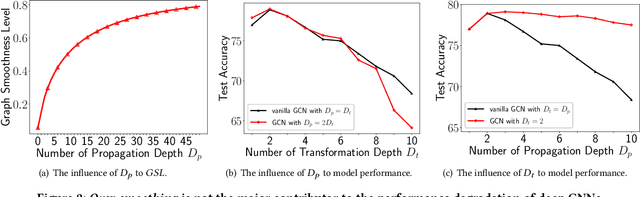
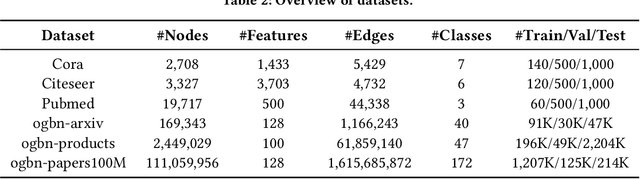
Graph Neural Networks (GNNs) have achieved great success in various graph mining tasks.However, drastic performance degradation is always observed when a GNN is stacked with many layers. As a result, most GNNs only have shallow architectures, which limits their expressive power and exploitation of deep neighborhoods.Most recent studies attribute the performance degradation of deep GNNs to the \textit{over-smoothing} issue. In this paper, we disentangle the conventional graph convolution operation into two independent operations: \textit{Propagation} (\textbf{P}) and \textit{Transformation} (\textbf{T}).Following this, the depth of a GNN can be split into the propagation depth ($D_p$) and the transformation depth ($D_t$). Through extensive experiments, we find that the major cause for the performance degradation of deep GNNs is the \textit{model degradation} issue caused by large $D_t$ rather than the \textit{over-smoothing} issue mainly caused by large $D_p$. Further, we present \textit{Adaptive Initial Residual} (AIR), a plug-and-play module compatible with all kinds of GNN architectures, to alleviate the \textit{model degradation} issue and the \textit{over-smoothing} issue simultaneously. Experimental results on six real-world datasets demonstrate that GNNs equipped with AIR outperform most GNNs with shallow architectures owing to the benefits of both large $D_p$ and $D_t$, while the time costs associated with AIR can be ignored.
* 11 pages, 10 figures
Graph Attention Multi-Layer Perceptron
Jun 09, 2022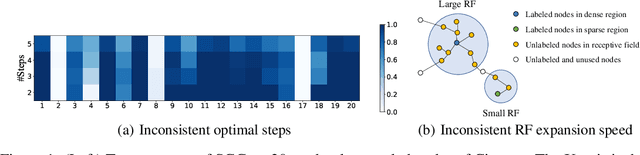

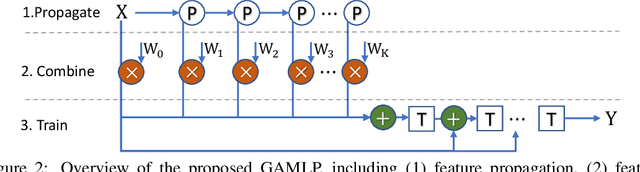
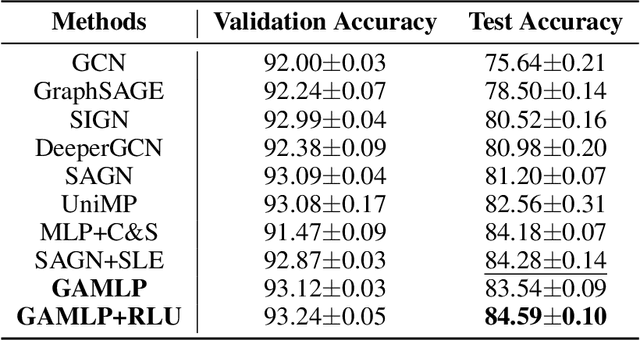
Graph neural networks (GNNs) have achieved great success in many graph-based applications. However, the enormous size and high sparsity level of graphs hinder their applications under industrial scenarios. Although some scalable GNNs are proposed for large-scale graphs, they adopt a fixed $K$-hop neighborhood for each node, thus facing the over-smoothing issue when adopting large propagation depths for nodes within sparse regions. To tackle the above issue, we propose a new GNN architecture -- Graph Attention Multi-Layer Perceptron (GAMLP), which can capture the underlying correlations between different scales of graph knowledge. We have deployed GAMLP in Tencent with the Angel platform, and we further evaluate GAMLP on both real-world datasets and large-scale industrial datasets. Extensive experiments on these 14 graph datasets demonstrate that GAMLP achieves state-of-the-art performance while enjoying high scalability and efficiency. Specifically, it outperforms GAT by 1.3\% regarding predictive accuracy on our large-scale Tencent Video dataset while achieving up to $50\times$ training speedup. Besides, it ranks top-1 on both the leaderboards of the largest homogeneous and heterogeneous graph (i.e., ogbn-papers100M and ogbn-mag) of Open Graph Benchmark.
* 11 pages, 7 figures. arXiv admin note: text overlap with arXiv:2108.10097
GRAND+: Scalable Graph Random Neural Networks
Mar 12, 2022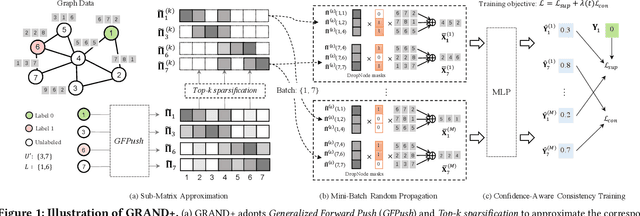
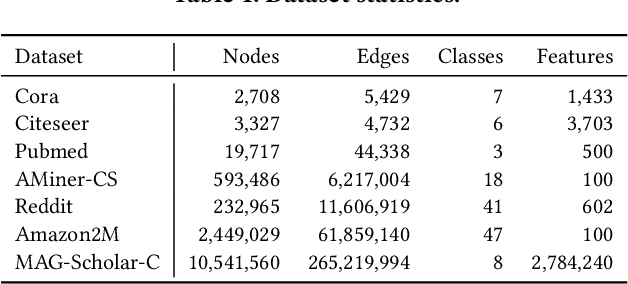
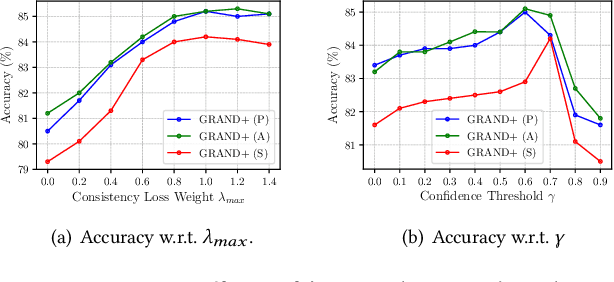

Graph neural networks (GNNs) have been widely adopted for semi-supervised learning on graphs. A recent study shows that the graph random neural network (GRAND) model can generate state-of-the-art performance for this problem. However, it is difficult for GRAND to handle large-scale graphs since its effectiveness relies on computationally expensive data augmentation procedures. In this work, we present a scalable and high-performance GNN framework GRAND+ for semi-supervised graph learning. To address the above issue, we develop a generalized forward push (GFPush) algorithm in GRAND+ to pre-compute a general propagation matrix and employ it to perform graph data augmentation in a mini-batch manner. We show that both the low time and space complexities of GFPush enable GRAND+ to efficiently scale to large graphs. Furthermore, we introduce a confidence-aware consistency loss into the model optimization of GRAND+, facilitating GRAND+'s generalization superiority. We conduct extensive experiments on seven public datasets of different sizes. The results demonstrate that GRAND+ 1) is able to scale to large graphs and costs less running time than existing scalable GNNs, and 2) can offer consistent accuracy improvements over both full-batch and scalable GNNs across all datasets.