 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Eval: An Agentic System for Automated and Traceable LLM Evaluation
Mar 10, 2026Reliable evaluation is essential for developing and deploying large language models, yet in practice it often requires substantial manual effort: practitioners must identify appropriate benchmarks, reproduce heterogeneous evaluation codebases, configure dataset schema mappings, and interpret aggregated metrics. To address these challenges, we present One-Eval, an agentic evaluation system that converts natural-language evaluation requests into executable, traceable, and customizable evaluation workflows. One-Eval integrates (i) NL2Bench for intent structuring and personalized benchmark planning, (ii) BenchResolve for benchmark resolution, automatic dataset acquisition, and schema normalization to ensure executability, and (iii) Metrics \& Reporting for task-aware metric selection and decision-oriented reporting beyond scalar scores. The system further incorporates human-in-the-loop checkpoints for review, editing, and rollback, while preserving sample evidence trails for debugging and auditability. Experiments show that One-Eval can execute end-to-end evaluations from diverse natural-language requests with minimal user effort, supporting more efficient and reproducible evaluation in industrial settings. Our framework is publicly available at https://github.com/OpenDCAI/One-Eval.
Generative Giants, Retrieval Weaklings: Why do Multimodal Large Language Models Fail at Multimodal Retrieval?
Dec 22, 2025Despite the remarkable success of multimodal large language models (MLLMs) in generative tasks, we observe that they exhibit a counterintuitive deficiency in the zero-shot multimodal retrieval task. In this work, we investigate the underlying mechanisms that hinder MLLMs from serving as effective retrievers. With the help of sparse autoencoders (SAEs), we decompose MLLM output representations into interpretable semantic concepts to probe their intrinsic behavior. Our analysis reveals that the representation space of MLLMs is overwhelmingly dominated by textual semantics; the visual information essential for multimodal retrieval only constitutes a small portion. This imbalance is compounded by the heavy focus of MLLMs on bridging image-text modalities, which facilitates generation but homogenizes embeddings and finally diminishes the discriminative power required for multimodal retrieval. We further discover that the specific feature components that contribute most to the similarity computations for MLLMs are in fact distractors that actively degrade retrieval performance. Overall, our work provides the first in-depth interpretability analysis of MLLM representations in the context of multimodal retrieval and offers possible directions for enhancing the multimodal retrieval capabilities of MLLMs.
Towards Scalable and Deep Graph Neural Networks via Noise Masking
Dec 19, 2024



In recent years, Graph Neural Networks (GNNs) have achieved remarkable success in many graph mining tasks. However, scaling them to large graphs is challenging due to the high computational and storage costs of repeated feature propagation and non-linear transformation during training. One commonly employed approach to address this challenge is model-simplification, which only executes the Propagation (P) once in the pre-processing, and Combine (C) these receptive fields in different ways and then feed them into a simple model for better performance. Despite their high predictive performance and scalability, these methods still face two limitations. First, existing approaches mainly focus on exploring different C methods from the model perspective, neglecting the crucial problem of performance degradation with increasing P depth from the data-centric perspective, known as the over-smoothing problem. Second, pre-processing overhead takes up most of the end-to-end processing time, especially for large-scale graphs. To address these limitations, we present random walk with noise masking (RMask), a plug-and-play module compatible with the existing model-simplification works. This module enables the exploration of deeper GNNs while preserving their scalability. Unlike the previous model-simplification works, we focus on continuous P and found that the noise existing inside each P is the cause of the over-smoothing issue, and use the efficient masking mechanism to eliminate them. Experimental results on six real-world datasets demonstrate that model-simplification works equipped with RMask yield superior performance compared to their original version and can make a good trade-off between accuracy and efficiency.
Acceleration Algorithms in GNNs: A Survey
May 07, 2024


Graph Neural Networks (GNNs) have demonstrated effectiveness in various graph-based tasks. However, their inefficiency in training and inference presents challenges for scaling up to real-world and large-scale graph applications. To address the critical challenges, a range of algorithms have been proposed to accelerate training and inference of GNNs, attracting increasing attention from the research community. In this paper, we present a systematic review of acceleration algorithms in GNNs, which can be categorized into three main topics based on their purpose: training acceleration, inference acceleration, and execution acceleration. Specifically, we summarize and categorize the existing approaches for each main topic, and provide detailed characterizations of the approaches within each category. Additionally, we review several libraries related to acceleration algorithms in GNNs and discuss our Scalable Graph Learning (SGL) library. Finally, we propose promising directions for future research. A complete summary is presented in our GitHub repository: https://github.com/PKU-DAIR/SGL/blob/main/Awsome-GNN-Acceleration.md.
NAFS: A Simple yet Tough-to-beat Baseline for Graph Representation Learning
Jun 17, 2022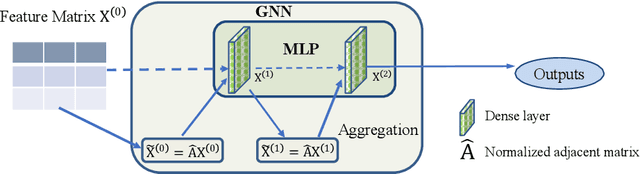
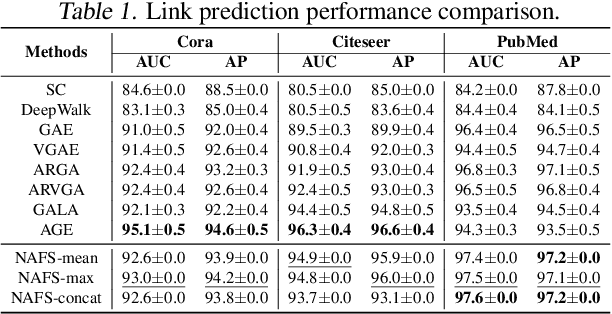
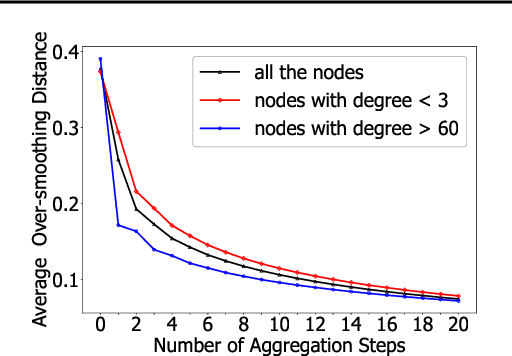
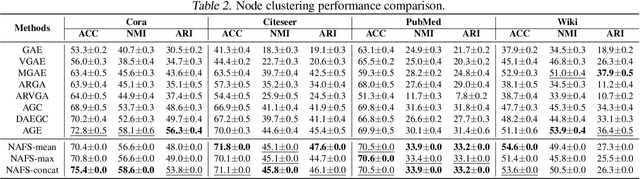
Recently, graph neural networks (GNNs) have shown prominent performance in graph representation learning by leveraging knowledge from both graph structure and node features. However, most of them have two major limitations. First, GNNs can learn higher-order structural information by stacking more layers but can not deal with large depth due to the over-smoothing issue. Second, it is not easy to apply these methods on large graphs due to the expensive computation cost and high memory usage. In this paper, we present node-adaptive feature smoothing (NAFS), a simple non-parametric method that constructs node representations without parameter learning. NAFS first extracts the features of each node with its neighbors of different hops by feature smoothing, and then adaptively combines the smoothed features. Besides, the constructed node representation can further be enhanced by the ensemble of smoothed features extracted via different smoothing strategies. We conduct experiments on four benchmark datasets on two different application scenarios: node clustering and link prediction. Remarkably, NAFS with feature ensemble outperforms the state-of-the-art GNNs on these tasks and mitigates the aforementioned two limitations of most learning-based GNN counterparts.
* 17 pages, 8 figures
Model Degradation Hinders Deep Graph Neural Networks
Jun 09, 2022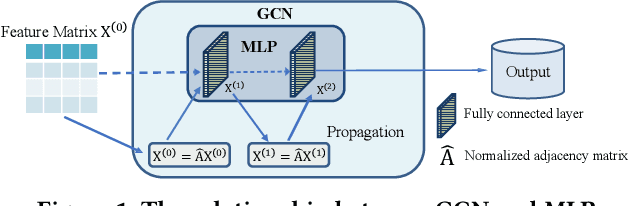
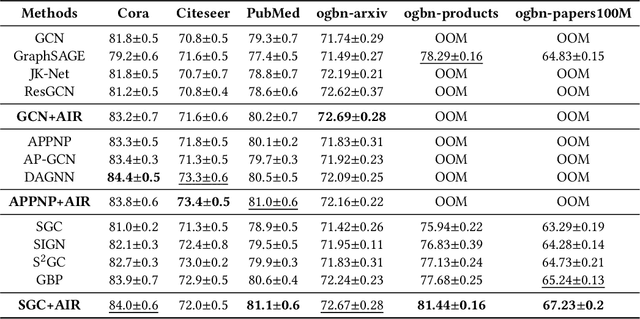
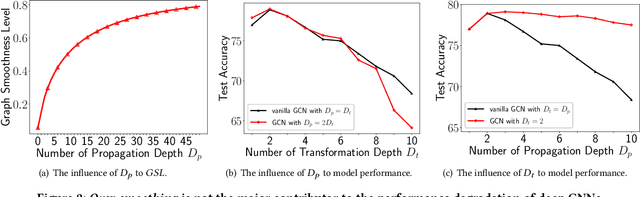
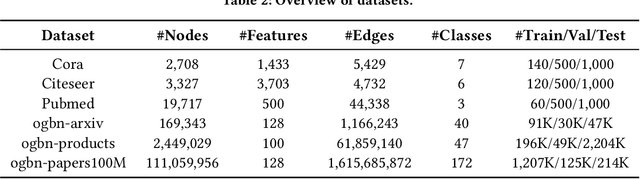
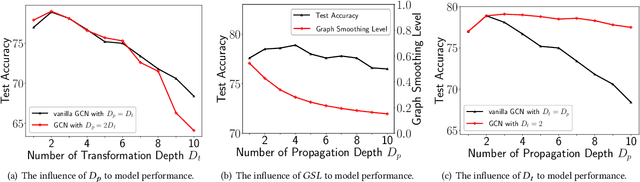
Graph Neural Networks (GNNs) have achieved great success in various graph mining tasks.However, drastic performance degradation is always observed when a GNN is stacked with many layers. As a result, most GNNs only have shallow architectures, which limits their expressive power and exploitation of deep neighborhoods.Most recent studies attribute the performance degradation of deep GNNs to the \textit{over-smoothing} issue. In this paper, we disentangle the conventional graph convolution operation into two independent operations: \textit{Propagation} (\textbf{P}) and \textit{Transformation} (\textbf{T}).Following this, the depth of a GNN can be split into the propagation depth ($D_p$) and the transformation depth ($D_t$). Through extensive experiments, we find that the major cause for the performance degradation of deep GNNs is the \textit{model degradation} issue caused by large $D_t$ rather than the \textit{over-smoothing} issue mainly caused by large $D_p$. Further, we present \textit{Adaptive Initial Residual} (AIR), a plug-and-play module compatible with all kinds of GNN architectures, to alleviate the \textit{model degradation} issue and the \textit{over-smoothing} issue simultaneously. Experimental results on six real-world datasets demonstrate that GNNs equipped with AIR outperform most GNNs with shallow architectures owing to the benefits of both large $D_p$ and $D_t$, while the time costs associated with AIR can be ignored.
* 11 pages, 10 figures
Graph Attention Multi-Layer Perceptron
Jun 09, 2022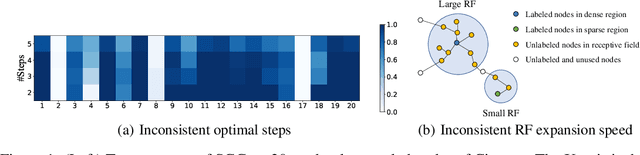

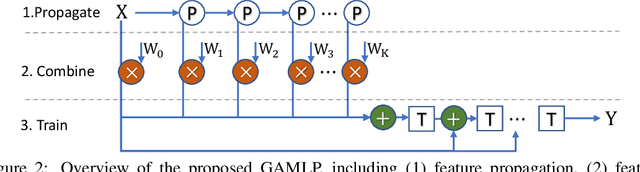
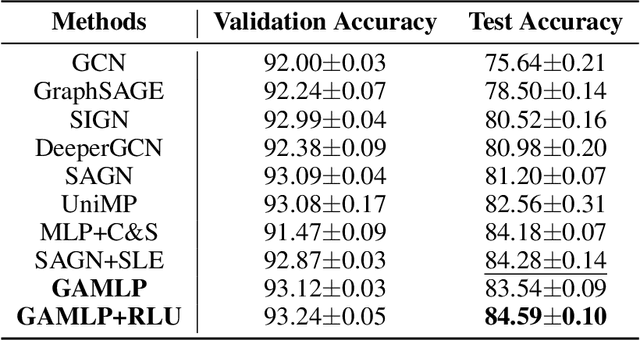
Graph neural networks (GNNs) have achieved great success in many graph-based applications. However, the enormous size and high sparsity level of graphs hinder their applications under industrial scenarios. Although some scalable GNNs are proposed for large-scale graphs, they adopt a fixed $K$-hop neighborhood for each node, thus facing the over-smoothing issue when adopting large propagation depths for nodes within sparse regions. To tackle the above issue, we propose a new GNN architecture -- Graph Attention Multi-Layer Perceptron (GAMLP), which can capture the underlying correlations between different scales of graph knowledge. We have deployed GAMLP in Tencent with the Angel platform, and we further evaluate GAMLP on both real-world datasets and large-scale industrial datasets. Extensive experiments on these 14 graph datasets demonstrate that GAMLP achieves state-of-the-art performance while enjoying high scalability and efficiency. Specifically, it outperforms GAT by 1.3\% regarding predictive accuracy on our large-scale Tencent Video dataset while achieving up to $50\times$ training speedup. Besides, it ranks top-1 on both the leaderboards of the largest homogeneous and heterogeneous graph (i.e., ogbn-papers100M and ogbn-mag) of Open Graph Benchmark.
* 11 pages, 7 figures. arXiv admin note: text overlap with arXiv:2108.10097
Node Dependent Local Smoothing for Scalable Graph Learning
Oct 27, 2021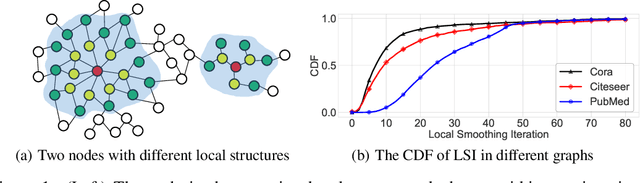

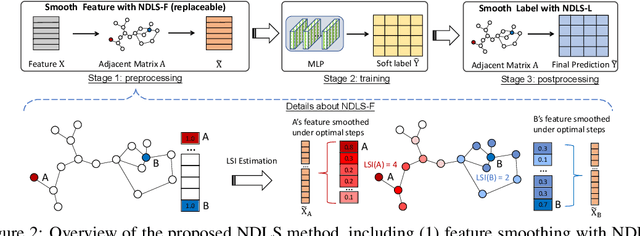
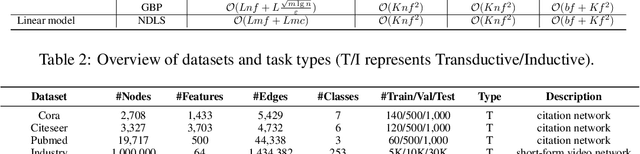
Recent works reveal that feature or label smoothing lies at the core of Graph Neural Networks (GNNs). Concretely, they show feature smoothing combined with simple linear regression achieves comparable performance with the carefully designed GNNs, and a simple MLP model with label smoothing of its prediction can outperform the vanilla GCN. Though an interesting finding, smoothing has not been well understood, especially regarding how to control the extent of smoothness. Intuitively, too small or too large smoothing iterations may cause under-smoothing or over-smoothing and can lead to sub-optimal performance. Moreover, the extent of smoothness is node-specific, depending on its degree and local structure. To this end, we propose a novel algorithm called node-dependent local smoothing (NDLS), which aims to control the smoothness of every node by setting a node-specific smoothing iteration. Specifically, NDLS computes influence scores based on the adjacency matrix and selects the iteration number by setting a threshold on the scores. Once selected, the iteration number can be applied to both feature smoothing and label smoothing. Experimental results demonstrate that NDLS enjoys high accuracy -- state-of-the-art performance on node classifications tasks, flexibility -- can be incorporated with any models, scalability and efficiency -- can support large scale graphs with fast training.
* 19 pages, 5 figures
Evaluating Deep Graph Neural Networks
Aug 02, 2021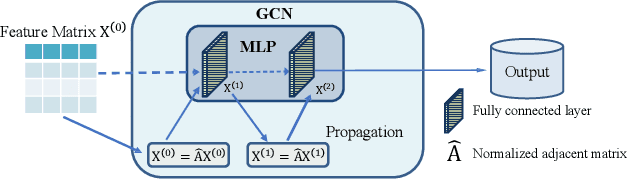

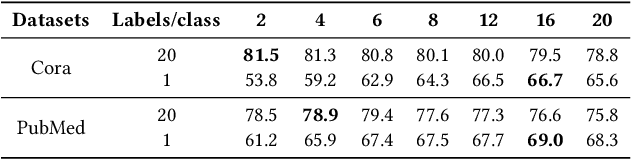
Graph Neural Networks (GNNs) have already been widely applied in various graph mining tasks. However, they suffer from the shallow architecture issue, which is the key impediment that hinders the model performance improvement. Although several relevant approaches have been proposed, none of the existing studies provides an in-depth understanding of the root causes of performance degradation in deep GNNs. In this paper, we conduct the first systematic experimental evaluation to present the fundamental limitations of shallow architectures. Based on the experimental results, we answer the following two essential questions: (1) what actually leads to the compromised performance of deep GNNs; (2) when we need and how to build deep GNNs. The answers to the above questions provide empirical insights and guidelines for researchers to design deep and well-performed GNNs. To show the effectiveness of our proposed guidelines, we present Deep Graph Multi-Layer Perceptron (DGMLP), a powerful approach (a paradigm in its own right) that helps guide deep GNN designs. Experimental results demonstrate three advantages of DGMLP: 1) high accuracy -- it achieves state-of-the-art node classification performance on various datasets; 2) high flexibility -- it can flexibly choose different propagation and transformation depths according to graph size and sparsity; 3) high scalability and efficiency -- it supports fast training on large-scale graphs. Our code is available in https://github.com/zwt233/DGMLP.