 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
Graph Attention Multi-Layer Perceptron
Jun 09, 2022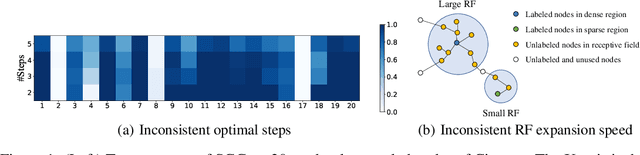

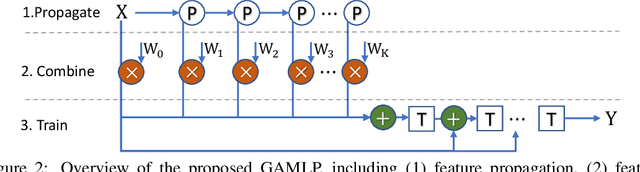
Graph neural networks (GNNs) have achieved great success in many graph-based applications. However, the enormous size and high sparsity level of graphs hinder their applications under industrial scenarios. Although some scalable GNNs are proposed for large-scale graphs, they adopt a fixed $K$-hop neighborhood for each node, thus facing the over-smoothing issue when adopting large propagation depths for nodes within sparse regions. To tackle the above issue, we propose a new GNN architecture -- Graph Attention Multi-Layer Perceptron (GAMLP), which can capture the underlying correlations between different scales of graph knowledge. We have deployed GAMLP in Tencent with the Angel platform, and we further evaluate GAMLP on both real-world datasets and large-scale industrial datasets. Extensive experiments on these 14 graph datasets demonstrate that GAMLP achieves state-of-the-art performance while enjoying high scalability and efficiency. Specifically, it outperforms GAT by 1.3\% regarding predictive accuracy on our large-scale Tencent Video dataset while achieving up to $50\times$ training speedup. Besides, it ranks top-1 on both the leaderboards of the largest homogeneous and heterogeneous graph (i.e., ogbn-papers100M and ogbn-mag) of Open Graph Benchmark.
* 11 pages, 7 figures. arXiv admin note: text overlap with arXiv:2108.10097
PaSca: a Graph Neural Architecture Search System under the Scalable Paradigm
Mar 01, 2022
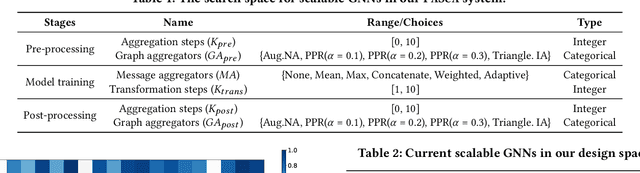
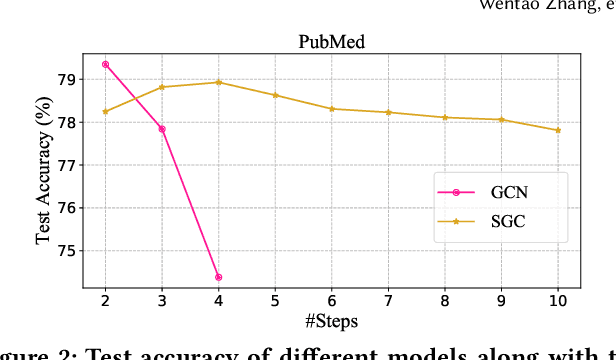

Graph neural networks (GNNs) have achieved state-of-the-art performance in various graph-based tasks. However, as mainstream GNNs are designed based on the neural message passing mechanism, they do not scale well to data size and message passing steps. Although there has been an emerging interest in the design of scalable GNNs, current researches focus on specific GNN design, rather than the general design space, limiting the discovery of potential scalable GNN models. This paper proposes PasCa, a new paradigm and system that offers a principled approach to systemically construct and explore the design space for scalable GNNs, rather than studying individual designs. Through deconstructing the message passing mechanism, PasCa presents a novel Scalable Graph Neural Architecture Paradigm (SGAP), together with a general architecture design space consisting of 150k different designs. Following the paradigm, we implement an auto-search engine that can automatically search well-performing and scalable GNN architectures to balance the trade-off between multiple criteria (e.g., accuracy and efficiency) via multi-objective optimization. Empirical studies on ten benchmark datasets demonstrate that the representative instances (i.e., PasCa-V1, V2, and V3) discovered by our system achieve consistent performance among competitive baselines. Concretely, PasCa-V3 outperforms the state-of-the-art GNN method JK-Net by 0.4\% in terms of predictive accuracy on our large industry dataset while achieving up to $28.3\times$ training speedups.
* 13 pages, 8 figures. arXiv admin note: text overlap with arXiv:2104.09880
K-Core Decomposition on Super Large Graphs with Limited Resources
Dec 26, 2021
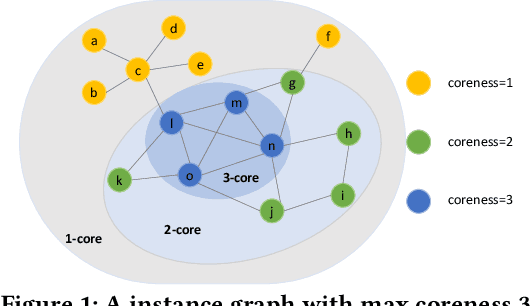
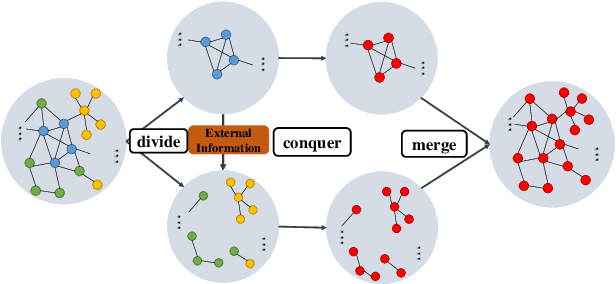

K-core decomposition is a commonly used metric to analyze graph structure or study the relative importance of nodes in complex graphs. Recent years have seen rapid growth in the scale of the graph, especially in industrial settings. For example, our industrial partner runs popular social applications with billions of users and is able to gather a rich set of user data. As a result, applying K-core decomposition on large graphs has attracted more and more attention from academics and the industry. A simple but effective method to deal with large graphs is to train them in the distributed settings, and some distributed K-core decomposition algorithms are also proposed. Despite their effectiveness, we experimentally and theoretically observe that these algorithms consume too many resources and become unstable on super-large-scale graphs, especially when the given resources are limited. In this paper, we deal with those super-large-scale graphs and propose a divide-and-conquer strategy on top of the distributed K-core decomposition algorithm. We evaluate our approach on three large graphs. The experimental results show that the consumption of resources can be significantly reduced, and the calculation on large-scale graphs becomes more stable than the existing methods. For example, the distributed K-core decomposition algorithm can scale to a large graph with 136 billion edges without losing correctness with our divide-and-conquer technique.
Node Dependent Local Smoothing for Scalable Graph Learning
Oct 27, 2021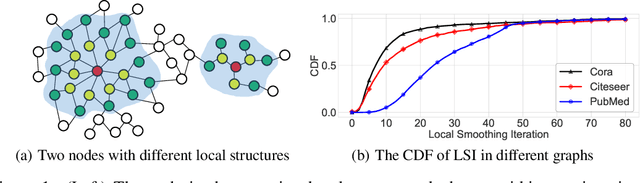

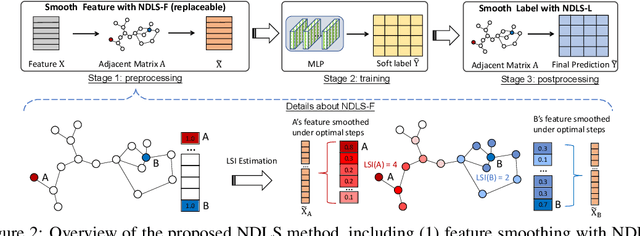
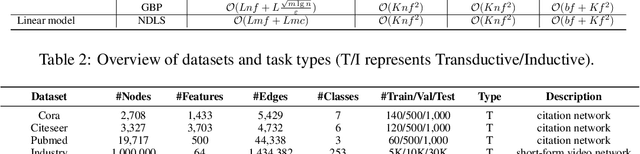
Recent works reveal that feature or label smoothing lies at the core of Graph Neural Networks (GNNs). Concretely, they show feature smoothing combined with simple linear regression achieves comparable performance with the carefully designed GNNs, and a simple MLP model with label smoothing of its prediction can outperform the vanilla GCN. Though an interesting finding, smoothing has not been well understood, especially regarding how to control the extent of smoothness. Intuitively, too small or too large smoothing iterations may cause under-smoothing or over-smoothing and can lead to sub-optimal performance. Moreover, the extent of smoothness is node-specific, depending on its degree and local structure. To this end, we propose a novel algorithm called node-dependent local smoothing (NDLS), which aims to control the smoothness of every node by setting a node-specific smoothing iteration. Specifically, NDLS computes influence scores based on the adjacency matrix and selects the iteration number by setting a threshold on the scores. Once selected, the iteration number can be applied to both feature smoothing and label smoothing. Experimental results demonstrate that NDLS enjoys high accuracy -- state-of-the-art performance on node classifications tasks, flexibility -- can be incorporated with any models, scalability and efficiency -- can support large scale graphs with fast training.
* 19 pages, 5 figures
GMLP: Building Scalable and Flexible Graph Neural Networks with Feature-Message Passing
Apr 20, 2021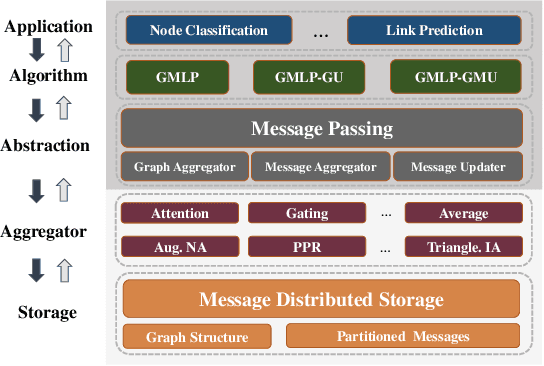
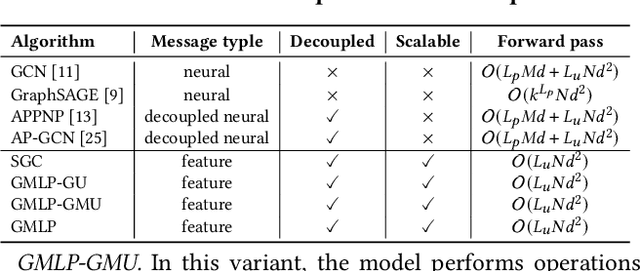
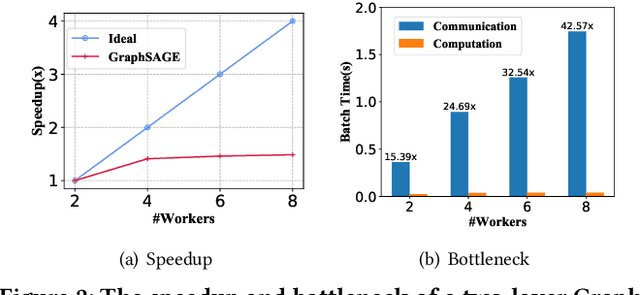
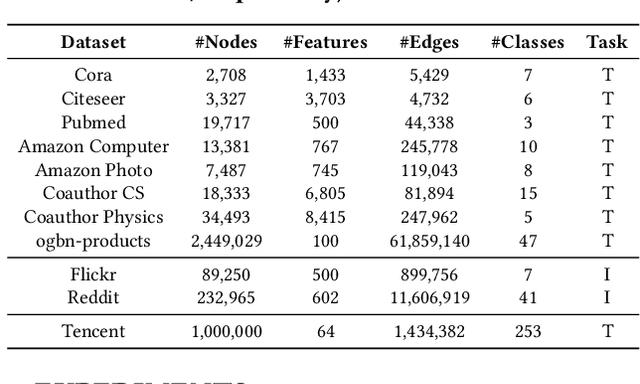
In recent studies, neural message passing has proved to be an effective way to design graph neural networks (GNNs), which have achieved state-of-the-art performance in many graph-based tasks. However, current neural-message passing architectures typically need to perform an expensive recursive neighborhood expansion in multiple rounds and consequently suffer from a scalability issue. Moreover, most existing neural-message passing schemes are inflexible since they are restricted to fixed-hop neighborhoods and insensitive to the actual demands of different nodes. We circumvent these limitations by a novel feature-message passing framework, called Graph Multi-layer Perceptron (GMLP), which separates the neural update from the message passing. With such separation, GMLP significantly improves the scalability and efficiency by performing the message passing procedure in a pre-compute manner, and is flexible and adaptive in leveraging node feature messages over various levels of localities. We further derive novel variants of scalable GNNs under this framework to achieve the best of both worlds in terms of performance and efficiency. We conduct extensive evaluations on 11 benchmark datasets, including large-scale datasets like ogbn-products and an industrial dataset, demonstrating that GMLP achieves not only the state-of-art performance, but also high training scalability and efficiency.