 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Index Merge for Approximate Nearest Neighbor Search
Feb 19, 2026Approximate $k$ nearest neighbor (AKNN) search in high-dimensional space is a foundational problem in vector databases with widespread applications. Among the numerous AKNN indexes, Proximity Graph-based indexes achieve state-of-the-art search efficiency across various benchmarks. However, their extensive distance computations of high-dimensional vectors lead to slow construction and substantial memory overhead. The limited memory capacity often prevents building the entire index at once when handling large-scale datasets. A common practice is to build multiple sub-indexes separately. However, directly searching on these separated indexes severely compromises search efficiency, as queries cannot leverage cross-graph connections. Therefore, efficient graph index merging is crucial for multi-index searching. In this paper, we focus on efficient two-index merging and the merge order of multiple indexes for AKNN search. To achieve this, we propose a reverse neighbor sliding merge (RNSM) that exploits structural information to boost merging efficiency. We further investigate merge order selection (MOS) to reduce the merging cost by eliminating redundant merge operations. Experiments show that our approach yields up to a 5.48$\times$ speedup over existing index merge methods and 9.92$\times$ speedup over index reconstruction, while maintaining expected superior search performance. Moreover, our method scales efficiently to 100 million vectors with 50 partitions, maintaining consistent speedups.
TokenMixer-Large: Scaling Up Large Ranking Models in Industrial Recommenders
Feb 06, 2026In recent years, the study of scaling laws for large recommendation models has gradually gained attention. Works such as Wukong, HiFormer, and DHEN have attempted to increase the complexity of interaction structures in ranking models and validate scaling laws between performance and parameters/FLOPs by stacking multiple layers. However, their experimental scale remains relatively limited. Our previous work introduced the TokenMixer architecture, an efficient variant of the standard Transformer where the self-attention mechanism is replaced by a simple reshape operation, and the feed-forward network is adapted to a pertoken FFN. The effectiveness of this architecture was demonstrated in the ranking stage by the model presented in the RankMixer paper. However, this foundational TokenMixer architecture itself has several design limitations. In this paper, we propose TokenMixer-Large, which systematically addresses these core issues: sub-optimal residual design, insufficient gradient updates in deep models, incomplete MoE sparsification, and limited exploration of scalability. By leveraging a mixing-and-reverting operation, inter-layer residuals, the auxiliary loss and a novel Sparse-Pertoken MoE architecture, TokenMixer-Large successfully scales its parameters to 7-billion and 15-billion on online traffic and offline experiments, respectively. Currently deployed in multiple scenarios at ByteDance, TokenMixer -Large has achieved significant offline and online performance gains.
ProAct: Agentic Lookahead in Interactive Environments
Feb 05, 2026Existing Large Language Model (LLM) agents struggle in interactive environments requiring long-horizon planning, primarily due to compounding errors when simulating future states. To address this, we propose ProAct, a framework that enables agents to internalize accurate lookahead reasoning through a two-stage training paradigm. First, we introduce Grounded LookAhead Distillation (GLAD), where the agent undergoes supervised fine-tuning on trajectories derived from environment-based search. By compressing complex search trees into concise, causal reasoning chains, the agent learns the logic of foresight without the computational overhead of inference-time search. Second, to further refine decision accuracy, we propose the Monte-Carlo Critic (MC-Critic), a plug-and-play auxiliary value estimator designed to enhance policy-gradient algorithms like PPO and GRPO. By leveraging lightweight environment rollouts to calibrate value estimates, MC-Critic provides a low-variance signal that facilitates stable policy optimization without relying on expensive model-based value approximation. Experiments on both stochastic (e.g., 2048) and deterministic (e.g., Sokoban) environments demonstrate that ProAct significantly improves planning accuracy. Notably, a 4B parameter model trained with ProAct outperforms all open-source baselines and rivals state-of-the-art closed-source models, while demonstrating robust generalization to unseen environments. The codes and models are available at https://github.com/GreatX3/ProAct
Yan: Foundational Interactive Video Generation
Aug 13, 2025We present Yan, a foundational framework for interactive video generation, covering the entire pipeline from simulation and generation to editing. Specifically, Yan comprises three core modules. AAA-level Simulation: We design a highly-compressed, low-latency 3D-VAE coupled with a KV-cache-based shift-window denoising inference process, achieving real-time 1080P/60FPS interactive simulation. Multi-Modal Generation: We introduce a hierarchical autoregressive caption method that injects game-specific knowledge into open-domain multi-modal video diffusion models (VDMs), then transforming the VDM into a frame-wise, action-controllable, real-time infinite interactive video generator. Notably, when the textual and visual prompts are sourced from different domains, the model demonstrates strong generalization, allowing it to blend and compose the style and mechanics across domains flexibly according to user prompts. Multi-Granularity Editing: We propose a hybrid model that explicitly disentangles interactive mechanics simulation from visual rendering, enabling multi-granularity video content editing during interaction through text. Collectively, Yan offers an integration of these modules, pushing interactive video generation beyond isolated capabilities toward a comprehensive AI-driven interactive creation paradigm, paving the way for the next generation of creative tools, media, and entertainment. The project page is: https://greatx3.github.io/Yan/.
Zebra-Llama: Towards Extremely Efficient Hybrid Models
May 22, 2025With the growing demand for deploying large language models (LLMs) across diverse applications, improving their inference efficiency is crucial for sustainable and democratized access. However, retraining LLMs to meet new user-specific requirements is prohibitively expensive and environmentally unsustainable. In this work, we propose a practical and scalable alternative: composing efficient hybrid language models from existing pre-trained models. Our approach, Zebra-Llama, introduces a family of 1B, 3B, and 8B hybrid models by combining State Space Models (SSMs) and Multi-head Latent Attention (MLA) layers, using a refined initialization and post-training pipeline to efficiently transfer knowledge from pre-trained Transformers. Zebra-Llama achieves Transformer-level accuracy with near-SSM efficiency using only 7-11B training tokens (compared to trillions of tokens required for pre-training) and an 8B teacher. Moreover, Zebra-Llama dramatically reduces KV cache size -down to 3.9%, 2%, and 2.73% of the original for the 1B, 3B, and 8B variants, respectively-while preserving 100%, 100%, and >97% of average zero-shot performance on LM Harness tasks. Compared to models like MambaInLLaMA, X-EcoMLA, Minitron, and Llamba, Zebra-Llama consistently delivers competitive or superior accuracy while using significantly fewer tokens, smaller teachers, and vastly reduced KV cache memory. Notably, Zebra-Llama-8B surpasses Minitron-8B in few-shot accuracy by 7% while using 8x fewer training tokens, over 12x smaller KV cache, and a smaller teacher (8B vs. 15B). It also achieves 2.6x-3.8x higher throughput (tokens/s) than MambaInLlama up to a 32k context length. We will release code and model checkpoints upon acceptance.
ELIS: Efficient LLM Iterative Scheduling System with Response Length Predictor
May 14, 2025We propose ELIS, a serving system for Large Language Models (LLMs) featuring an Iterative Shortest Remaining Time First (ISRTF) scheduler designed to efficiently manage inference tasks with the shortest remaining tokens. Current LLM serving systems often employ a first-come-first-served scheduling strategy, which can lead to the "head-of-line blocking" problem. To overcome this limitation, it is necessary to predict LLM inference times and apply a shortest job first scheduling strategy. However, due to the auto-regressive nature of LLMs, predicting the inference latency is challenging. ELIS addresses this challenge by training a response length predictor for LLMs using the BGE model, an encoder-based state-of-the-art model. Additionally, we have devised the ISRTF scheduling strategy, an optimization of shortest remaining time first tailored to existing LLM iteration batching. To evaluate our work in an industrial setting, we simulate streams of requests based on our study of real-world user LLM serving trace records. Furthermore, we implemented ELIS as a cloud-native scheduler system on Kubernetes to evaluate its performance in production environments. Our experimental results demonstrate that ISRTF reduces the average job completion time by up to 19.6%.
X-EcoMLA: Upcycling Pre-Trained Attention into MLA for Efficient and Extreme KV Compression
Mar 14, 2025



Multi-head latent attention (MLA) is designed to optimize KV cache memory through low-rank key-value joint compression. Rather than caching keys and values separately, MLA stores their compressed latent representations, reducing memory overhead while maintaining the performance. While MLA improves memory efficiency without compromising language model accuracy, its major limitation lies in its integration during the pre-training phase, requiring models to be trained from scratch. This raises a key question: can we use MLA's benefits fully or partially in models that have already been pre-trained with different attention mechanisms? In this paper, we propose X-EcoMLA to deploy post training distillation to enable the upcycling of Transformer-based attention into an efficient hybrid (i.e., combination of regular attention and MLA layers) or full MLA variant through lightweight post-training adaptation, bypassing the need for extensive pre-training. We demonstrate that leveraging the dark knowledge of a well-trained model can enhance training accuracy and enable extreme KV cache compression in MLA without compromising model performance. Our results show that using an 8B teacher model allows us to compress the KV cache size of the Llama3.2-1B-Inst baseline by 6.4x while preserving 100% of its average score across multiple tasks on the LM Harness Evaluation benchmark. This is achieved with only 3.6B training tokens and about 70 GPU hours on AMD MI300 GPUs, compared to the 370K GPU hours required for pre-training the Llama3.2-1B model.
SAM-guided Pseudo Label Enhancement for Multi-modal 3D Semantic Segmentation
Feb 02, 2025



Multi-modal 3D semantic segmentation is vital for applications such as autonomous driving and virtual reality (VR). To effectively deploy these models in real-world scenarios, it is essential to employ cross-domain adaptation techniques that bridge the gap between training data and real-world data. Recently, self-training with pseudo-labels has emerged as a predominant method for cross-domain adaptation in multi-modal 3D semantic segmentation. However, generating reliable pseudo-labels necessitates stringent constraints, which often result in sparse pseudo-labels after pruning. This sparsity can potentially hinder performance improvement during the adaptation process. We propose an image-guided pseudo-label enhancement approach that leverages the complementary 2D prior knowledge from the Segment Anything Model (SAM) to introduce more reliable pseudo-labels, thereby boosting domain adaptation performance. Specifically, given a 3D point cloud and the SAM masks from its paired image data, we collect all 3D points covered by each SAM mask that potentially belong to the same object. Then our method refines the pseudo-labels within each SAM mask in two steps. First, we determine the class label for each mask using majority voting and employ various constraints to filter out unreliable mask labels. Next, we introduce Geometry-Aware Progressive Propagation (GAPP) which propagates the mask label to all 3D points within the SAM mask while avoiding outliers caused by 2D-3D misalignment. Experiments conducted across multiple datasets and domain adaptation scenarios demonstrate that our proposed method significantly increases the quantity of high-quality pseudo-labels and enhances the adaptation performance over baseline methods.
Playable Game Generation
Dec 01, 2024



In recent years, Artificial Intelligence Generated Content (AIGC) has advanced from text-to-image generation to text-to-video and multimodal video synthesis. However, generating playable games presents significant challenges due to the stringent requirements for real-time interaction, high visual quality, and accurate simulation of game mechanics. Existing approaches often fall short, either lacking real-time capabilities or failing to accurately simulate interactive mechanics. To tackle the playability issue, we propose a novel method called \emph{PlayGen}, which encompasses game data generation, an autoregressive DiT-based diffusion model, and a comprehensive playability-based evaluation framework. Validated on well-known 2D and 3D games, PlayGen achieves real-time interaction, ensures sufficient visual quality, and provides accurate interactive mechanics simulation. Notably, these results are sustained even after over 1000 frames of gameplay on an NVIDIA RTX 2060 GPU. Our code is publicly available: https://github.com/GreatX3/Playable-Game-Generation. Our playable demo generated by AI is: http://124.156.151.207.
A Survey of Attacks on Large Vision-Language Models: Resources, Advances, and Future Trends
Jul 10, 2024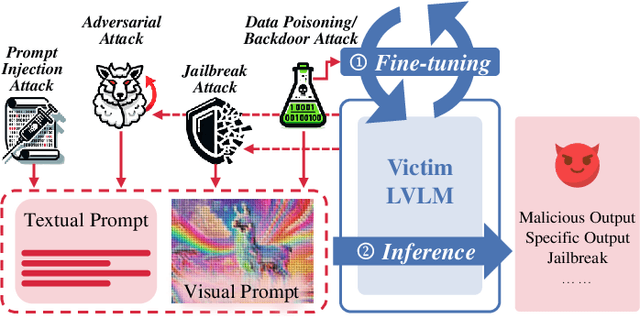
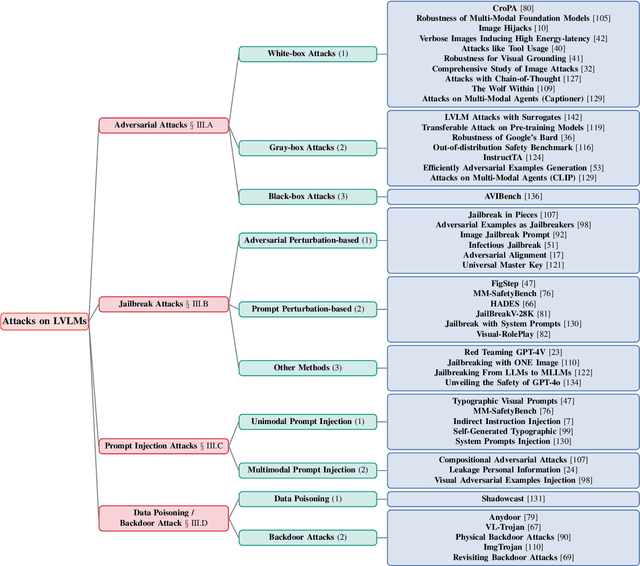
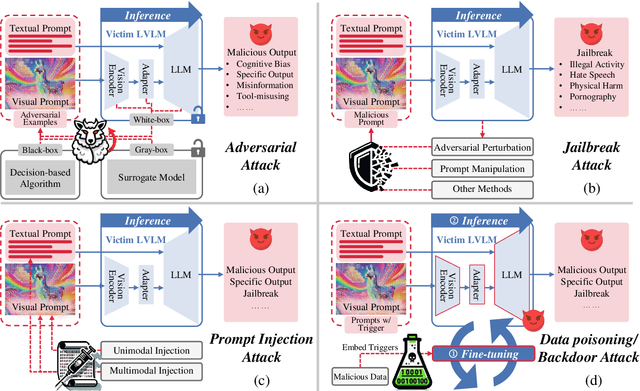

With the significant development of large models in recent years, Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities across a wide range of multimodal understanding and reasoning tasks. Compared to traditional Large Language Models (LLMs), LVLMs present great potential and challenges due to its closer proximity to the multi-resource real-world applications and the complexity of multi-modal processing. However, the vulnerability of LVLMs is relatively underexplored, posing potential security risks in daily usage. In this paper, we provide a comprehensive review of the various forms of existing LVLM attacks. Specifically, we first introduce the background of attacks targeting LVLMs, including the attack preliminary, attack challenges, and attack resources. Then, we systematically review the development of LVLM attack methods, such as adversarial attacks that manipulate model outputs, jailbreak attacks that exploit model vulnerabilities for unauthorized actions, prompt injection attacks that engineer the prompt type and pattern, and data poisoning that affects model training. Finally, we discuss promising research directions in the future. We believe that our survey provides insights into the current landscape of LVLM vulnerabilities, inspiring more researchers to explore and mitigate potential safety issues in LVLM developments. The latest papers on LVLM attacks are continuously collected in https://github.com/liudaizong/Awesome-LVLM-Attack.