 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Attacks on Large Vision-Language Models: Resources, Advances, and Future Trends
Paper and Code
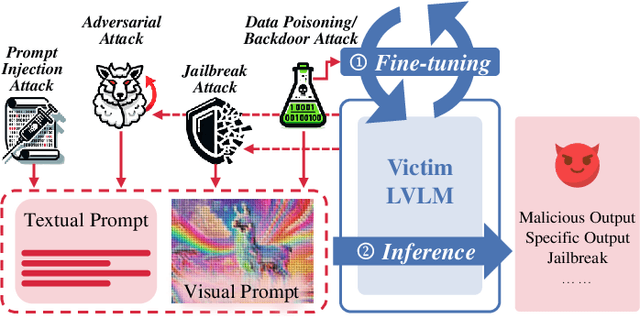
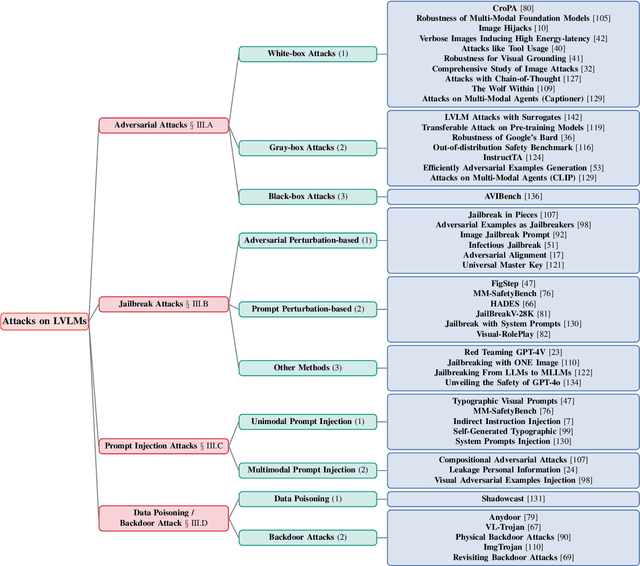
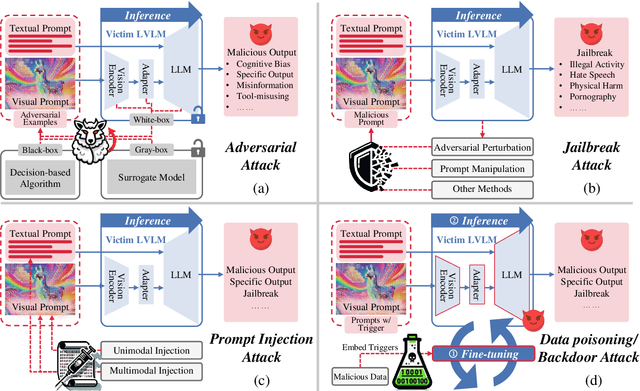

With the significant development of large models in recent years, Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities across a wide range of multimodal understanding and reasoning tasks. Compared to traditional Large Language Models (LLMs), LVLMs present great potential and challenges due to its closer proximity to the multi-resource real-world applications and the complexity of multi-modal processing. However, the vulnerability of LVLMs is relatively underexplored, posing potential security risks in daily usage. In this paper, we provide a comprehensive review of the various forms of existing LVLM attacks. Specifically, we first introduce the background of attacks targeting LVLMs, including the attack preliminary, attack challenges, and attack resources. Then, we systematically review the development of LVLM attack methods, such as adversarial attacks that manipulate model outputs, jailbreak attacks that exploit model vulnerabilities for unauthorized actions, prompt injection attacks that engineer the prompt type and pattern, and data poisoning that affects model training. Finally, we discuss promising research directions in the future. We believe that our survey provides insights into the current landscape of LVLM vulnerabilities, inspiring more researchers to explore and mitigate potential safety issues in LVLM developments. The latest papers on LVLM attacks are continuously collected in https://github.com/liudaizong/Awesome-LVLM-Attack.