 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Context Aware Upcycling: A New Frontier for Hybrid LLM Scaling
Apr 27, 2026Hybrid sequence models that combine efficient Transformer components with linear sequence modeling blocks are a promising alternative to pure Transformers, but most are still pretrained from scratch and therefore fail to reuse existing Transformer checkpoints. We study upcycling as a practical path to convert pretrained Transformer LLMs into hybrid architectures while preserving short-context quality and improving long-context capability. We call our solution \emph{HyLo} (HYbrid LOng-context): a long-context upcycling recipe that combines architectural adaptation with efficient Transformer blocks, Multi-Head Latent Attention (MLA), and linear blocks (Mamba2 or Gated DeltaNet), together with staged long-context training and teacher-guided distillation for stable optimization. HyLo extends usable context length by up to $32\times$ through efficient post-training and reduces KV-cache memory by more than $90\%$, enabling up to 2M-token prefill and decoding in our \texttt{vLLM} inference stack, while comparable Llama baselines run out of memory beyond 64K context. Across 1B- and 3B-scale settings (Llama- and Qwen-based variants), HyLo delivers consistently strong short- and long-context performance and significantly outperforms state-of-the-art upcycled hybrid baselines on long-context evaluations such as RULER. Notably, at similar scale, HyLo-Qwen-1.7B trained on only 10B tokens significantly outperforms JetNemotron (trained on 400B tokens) on GSM8K, Lm-Harness common sense reasoning and RULER-64K.
FarSkip-Collective: Unhobbling Blocking Communication in Mixture of Experts Models
Nov 14, 2025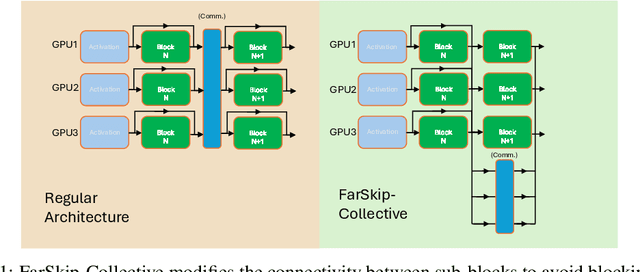
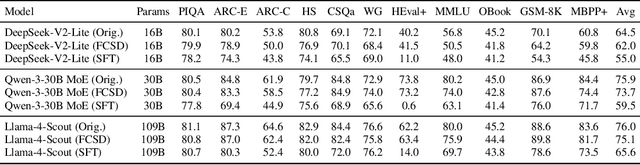
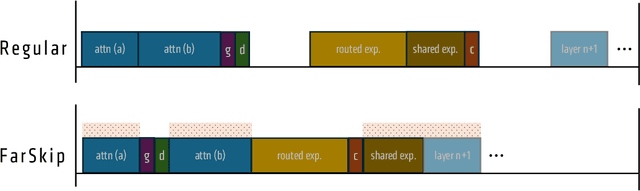
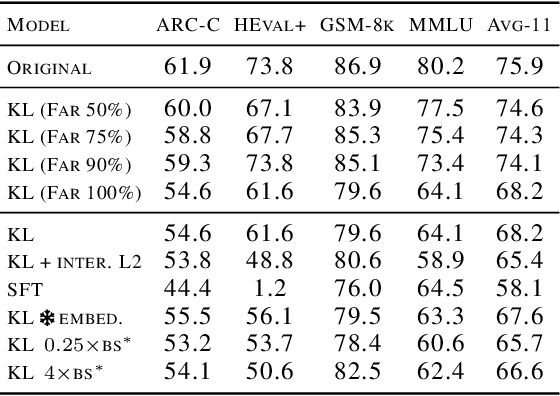
Blocking communication presents a major hurdle in running MoEs efficiently in distributed settings. To address this, we present FarSkip-Collective which modifies the architecture of modern models to enable overlapping of their computation with communication. Our approach modifies the architecture to skip connections in the model and it is unclear a priori whether the modified model architecture can remain as capable, especially for large state-of-the-art models and while modifying all of the model layers. We answer this question in the affirmative and fully convert a series of state-of-the-art models varying from 16B to 109B parameters to enable overlapping of their communication while achieving accuracy on par with their original open-source releases. For example, we convert Llama 4 Scout (109B) via self-distillation and achieve average accuracy within 1% of its instruction tuned release averaged across a wide range of downstream evaluations. In addition to demonstrating retained accuracy of the large modified models, we realize the benefits of FarSkip-Collective through optimized implementations that explicitly overlap communication with computation, accelerating both training and inference in existing frameworks.
Zebra-Llama: Towards Extremely Efficient Hybrid Models
May 22, 2025With the growing demand for deploying large language models (LLMs) across diverse applications, improving their inference efficiency is crucial for sustainable and democratized access. However, retraining LLMs to meet new user-specific requirements is prohibitively expensive and environmentally unsustainable. In this work, we propose a practical and scalable alternative: composing efficient hybrid language models from existing pre-trained models. Our approach, Zebra-Llama, introduces a family of 1B, 3B, and 8B hybrid models by combining State Space Models (SSMs) and Multi-head Latent Attention (MLA) layers, using a refined initialization and post-training pipeline to efficiently transfer knowledge from pre-trained Transformers. Zebra-Llama achieves Transformer-level accuracy with near-SSM efficiency using only 7-11B training tokens (compared to trillions of tokens required for pre-training) and an 8B teacher. Moreover, Zebra-Llama dramatically reduces KV cache size -down to 3.9%, 2%, and 2.73% of the original for the 1B, 3B, and 8B variants, respectively-while preserving 100%, 100%, and >97% of average zero-shot performance on LM Harness tasks. Compared to models like MambaInLLaMA, X-EcoMLA, Minitron, and Llamba, Zebra-Llama consistently delivers competitive or superior accuracy while using significantly fewer tokens, smaller teachers, and vastly reduced KV cache memory. Notably, Zebra-Llama-8B surpasses Minitron-8B in few-shot accuracy by 7% while using 8x fewer training tokens, over 12x smaller KV cache, and a smaller teacher (8B vs. 15B). It also achieves 2.6x-3.8x higher throughput (tokens/s) than MambaInLlama up to a 32k context length. We will release code and model checkpoints upon acceptance.
X-EcoMLA: Upcycling Pre-Trained Attention into MLA for Efficient and Extreme KV Compression
Mar 14, 2025



Multi-head latent attention (MLA) is designed to optimize KV cache memory through low-rank key-value joint compression. Rather than caching keys and values separately, MLA stores their compressed latent representations, reducing memory overhead while maintaining the performance. While MLA improves memory efficiency without compromising language model accuracy, its major limitation lies in its integration during the pre-training phase, requiring models to be trained from scratch. This raises a key question: can we use MLA's benefits fully or partially in models that have already been pre-trained with different attention mechanisms? In this paper, we propose X-EcoMLA to deploy post training distillation to enable the upcycling of Transformer-based attention into an efficient hybrid (i.e., combination of regular attention and MLA layers) or full MLA variant through lightweight post-training adaptation, bypassing the need for extensive pre-training. We demonstrate that leveraging the dark knowledge of a well-trained model can enhance training accuracy and enable extreme KV cache compression in MLA without compromising model performance. Our results show that using an 8B teacher model allows us to compress the KV cache size of the Llama3.2-1B-Inst baseline by 6.4x while preserving 100% of its average score across multiple tasks on the LM Harness Evaluation benchmark. This is achieved with only 3.6B training tokens and about 70 GPU hours on AMD MI300 GPUs, compared to the 370K GPU hours required for pre-training the Llama3.2-1B model.
Online-LoRA: Task-free Online Continual Learning via Low Rank Adaptation
Nov 08, 2024Catastrophic forgetting is a significant challenge in online continual learning (OCL), especially for non-stationary data streams that do not have well-defined task boundaries. This challenge is exacerbated by the memory constraints and privacy concerns inherent in rehearsal buffers. To tackle catastrophic forgetting, in this paper, we introduce Online-LoRA, a novel framework for task-free OCL. Online-LoRA allows to finetune pre-trained Vision Transformer (ViT) models in real-time to address the limitations of rehearsal buffers and leverage pre-trained models' performance benefits. As the main contribution, our approach features a novel online weight regularization strategy to identify and consolidate important model parameters. Moreover, Online-LoRA leverages the training dynamics of loss values to enable the automatic recognition of the data distribution shifts. Extensive experiments across many task-free OCL scenarios and benchmark datasets (including CIFAR-100, ImageNet-R, ImageNet-S, CUB-200 and CORe50) demonstrate that Online-LoRA can be robustly adapted to various ViT architectures, while achieving better performance compared to SOTA methods. Our code will be publicly available at: https://github.com/Christina200/Online-LoRA-official.git.
Machine Unlearning for Image-to-Image Generative Models
Feb 02, 2024
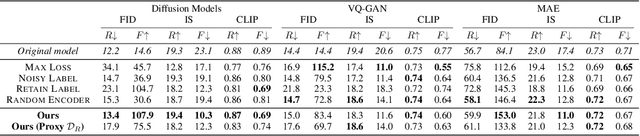
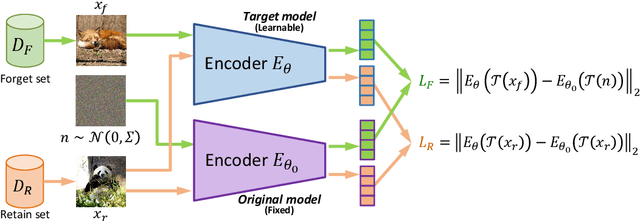
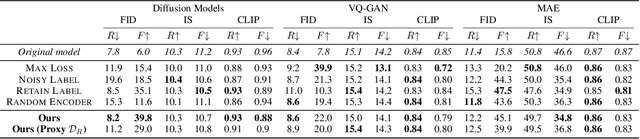
Machine unlearning has emerged as a new paradigm to deliberately forget data samples from a given model in order to adhere to stringent regulations. However, existing machine unlearning methods have been primarily focused on classification models, leaving the landscape of unlearning for generative models relatively unexplored. This paper serves as a bridge, addressing the gap by providing a unifying framework of machine unlearning for image-to-image generative models. Within this framework, we propose a computationally-efficient algorithm, underpinned by rigorous theoretical analysis, that demonstrates negligible performance degradation on the retain samples, while effectively removing the information from the forget samples. Empirical studies on two large-scale datasets, ImageNet-1K and Places-365, further show that our algorithm does not rely on the availability of the retain samples, which further complies with data retention policy. To our best knowledge, this work is the first that represents systemic, theoretical, empirical explorations of machine unlearning specifically tailored for image-to-image generative models. Our code is available at https://github.com/jpmorganchase/l2l-generator-unlearning.
Dropout-Based Rashomon Set Exploration for Efficient Predictive Multiplicity Estimation
Feb 01, 2024



Predictive multiplicity refers to the phenomenon in which classification tasks may admit multiple competing models that achieve almost-equally-optimal performance, yet generate conflicting outputs for individual samples. This presents significant concerns, as it can potentially result in systemic exclusion, inexplicable discrimination, and unfairness in practical applications. Measuring and mitigating predictive multiplicity, however, is computationally challenging due to the need to explore all such almost-equally-optimal models, known as the Rashomon set, in potentially huge hypothesis spaces. To address this challenge, we propose a novel framework that utilizes dropout techniques for exploring models in the Rashomon set. We provide rigorous theoretical derivations to connect the dropout parameters to properties of the Rashomon set, and empirically evaluate our framework through extensive experimentation. Numerical results show that our technique consistently outperforms baselines in terms of the effectiveness of predictive multiplicity metric estimation, with runtime speedup up to $20\times \sim 5000\times$. With efficient Rashomon set exploration and metric estimation, mitigation of predictive multiplicity is then achieved through dropout ensemble and model selection.
Fast-NTK: Parameter-Efficient Unlearning for Large-Scale Models
Dec 22, 2023The rapid growth of machine learning has spurred legislative initiatives such as ``the Right to be Forgotten,'' allowing users to request data removal. In response, ``machine unlearning'' proposes the selective removal of unwanted data without the need for retraining from scratch. While the Neural-Tangent-Kernel-based (NTK-based) unlearning method excels in performance, it suffers from significant computational complexity, especially for large-scale models and datasets. Our work introduces ``Fast-NTK,'' a novel NTK-based unlearning algorithm that significantly reduces the computational complexity by incorporating parameter-efficient fine-tuning methods, such as fine-tuning batch normalization layers in a CNN or visual prompts in a vision transformer. Our experimental results demonstrate scalability to much larger neural networks and datasets (e.g., 88M parameters; 5k images), surpassing the limitations of previous full-model NTK-based approaches designed for smaller cases (e.g., 8M parameters; 500 images). Notably, our approach maintains a performance comparable to the traditional method of retraining on the retain set alone. Fast-NTK can thus enable for practical and scalable NTK-based unlearning in deep neural networks.
Efficient Low-rank Backpropagation for Vision Transformer Adaptation
Sep 26, 2023
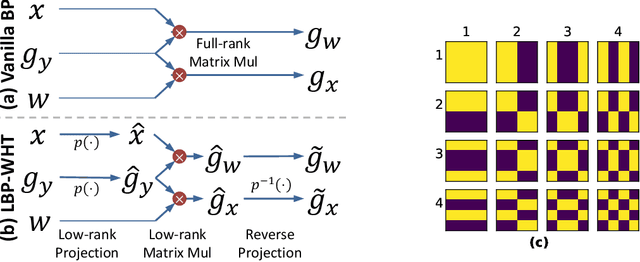


The increasing scale of vision transformers (ViT) has made the efficient fine-tuning of these large models for specific needs a significant challenge in various applications. This issue originates from the computationally demanding matrix multiplications required during the backpropagation process through linear layers in ViT. In this paper, we tackle this problem by proposing a new Low-rank BackPropagation via Walsh-Hadamard Transformation (LBP-WHT) method. Intuitively, LBP-WHT projects the gradient into a low-rank space and carries out backpropagation. This approach substantially reduces the computation needed for adapting ViT, as matrix multiplication in the low-rank space is far less resource-intensive. We conduct extensive experiments with different models (ViT, hybrid convolution-ViT model) on multiple datasets to demonstrate the effectiveness of our method. For instance, when adapting an EfficientFormer-L1 model on CIFAR100, our LBP-WHT achieves 10.4% higher accuracy than the state-of-the-art baseline, while requiring 9 MFLOPs less computation. As the first work to accelerate ViT adaptation with low-rank backpropagation, our LBP-WHT method is complementary to many prior efforts and can be combined with them for better performance.
Zero-Shot Neural Architecture Search: Challenges, Solutions, and Opportunities
Jul 05, 2023Recently, zero-shot (or training-free) Neural Architecture Search (NAS) approaches have been proposed to liberate the NAS from training requirements. The key idea behind zero-shot NAS approaches is to design proxies that predict the accuracies of the given networks without training network parameters. The proxies proposed so far are usually inspired by recent progress in theoretical deep learning and have shown great potential on several NAS benchmark datasets. This paper aims to comprehensively review and compare the state-of-the-art (SOTA) zero-shot NAS approaches, with an emphasis on their hardware awareness. To this end, we first review the mainstream zero-shot proxies and discuss their theoretical underpinnings. We then compare these zero-shot proxies through large-scale experiments and demonstrate their effectiveness in both hardware-aware and hardware-oblivious NAS scenarios. Finally, we point out several promising ideas to design better proxies. Our source code and the related paper list are available on https://github.com/SLDGroup/survey-zero-shot-nas.