 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePASS: Private Attributes Protection with Stochastic Data Substitution
Jun 08, 2025The growing Machine Learning (ML) services require extensive collections of user data, which may inadvertently include people's private information irrelevant to the services. Various studies have been proposed to protect private attributes by removing them from the data while maintaining the utilities of the data for downstream tasks. Nevertheless, as we theoretically and empirically show in the paper, these methods reveal severe vulnerability because of a common weakness rooted in their adversarial training based strategies. To overcome this limitation, we propose a novel approach, PASS, designed to stochastically substitute the original sample with another one according to certain probabilities, which is trained with a novel loss function soundly derived from information-theoretic objective defined for utility-preserving private attributes protection. The comprehensive evaluation of PASS on various datasets of different modalities, including facial images, human activity sensory signals, and voice recording datasets, substantiates PASS's effectiveness and generalizability.
Hybrid Memory Replay: Blending Real and Distilled Data for Class Incremental Learning
Oct 20, 2024



Incremental learning (IL) aims to acquire new knowledge from current tasks while retaining knowledge learned from previous tasks. Replay-based IL methods store a set of exemplars from previous tasks in a buffer and replay them when learning new tasks. However, there is usually a size-limited buffer that cannot store adequate real exemplars to retain the knowledge of previous tasks. In contrast, data distillation (DD) can reduce the exemplar buffer's size, by condensing a large real dataset into a much smaller set of more information-compact synthetic exemplars. Nevertheless, DD's performance gain on IL quickly vanishes as the number of synthetic exemplars grows. To overcome the weaknesses of real-data and synthetic-data buffers, we instead optimize a hybrid memory including both types of data. Specifically, we propose an innovative modification to DD that distills synthetic data from a sliding window of checkpoints in history (rather than checkpoints on multiple training trajectories). Conditioned on the synthetic data, we then optimize the selection of real exemplars to provide complementary improvement to the DD objective. The optimized hybrid memory combines the strengths of synthetic and real exemplars, effectively mitigating catastrophic forgetting in Class IL (CIL) when the buffer size for exemplars is limited. Notably, our method can be seamlessly integrated into most existing replay-based CIL models. Extensive experiments across multiple benchmarks demonstrate that our method significantly outperforms existing replay-based baselines.
Model-Agnostic Utility-Preserving Biometric Information Anonymization
May 23, 2024The recent rapid advancements in both sensing and machine learning technologies have given rise to the universal collection and utilization of people's biometrics, such as fingerprints, voices, retina/facial scans, or gait/motion/gestures data, enabling a wide range of applications including authentication, health monitoring, or much more sophisticated analytics. While providing better user experiences and deeper business insights, the use of biometrics has raised serious privacy concerns due to their intrinsic sensitive nature and the accompanying high risk of leaking sensitive information such as identity or medical conditions. In this paper, we propose a novel modality-agnostic data transformation framework that is capable of anonymizing biometric data by suppressing its sensitive attributes and retaining features relevant to downstream machine learning-based analyses that are of research and business values. We carried out a thorough experimental evaluation using publicly available facial, voice, and motion datasets. Results show that our proposed framework can achieve a \highlight{high suppression level for sensitive information}, while at the same time retain underlying data utility such that subsequent analyses on the anonymized biometric data could still be carried out to yield satisfactory accuracy.
Dropout-Based Rashomon Set Exploration for Efficient Predictive Multiplicity Estimation
Feb 01, 2024



Predictive multiplicity refers to the phenomenon in which classification tasks may admit multiple competing models that achieve almost-equally-optimal performance, yet generate conflicting outputs for individual samples. This presents significant concerns, as it can potentially result in systemic exclusion, inexplicable discrimination, and unfairness in practical applications. Measuring and mitigating predictive multiplicity, however, is computationally challenging due to the need to explore all such almost-equally-optimal models, known as the Rashomon set, in potentially huge hypothesis spaces. To address this challenge, we propose a novel framework that utilizes dropout techniques for exploring models in the Rashomon set. We provide rigorous theoretical derivations to connect the dropout parameters to properties of the Rashomon set, and empirically evaluate our framework through extensive experimentation. Numerical results show that our technique consistently outperforms baselines in terms of the effectiveness of predictive multiplicity metric estimation, with runtime speedup up to $20\times \sim 5000\times$. With efficient Rashomon set exploration and metric estimation, mitigation of predictive multiplicity is then achieved through dropout ensemble and model selection.
Quantum Deep Hedging
Mar 29, 2023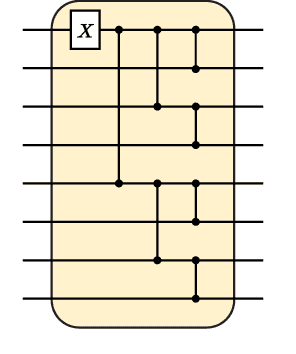
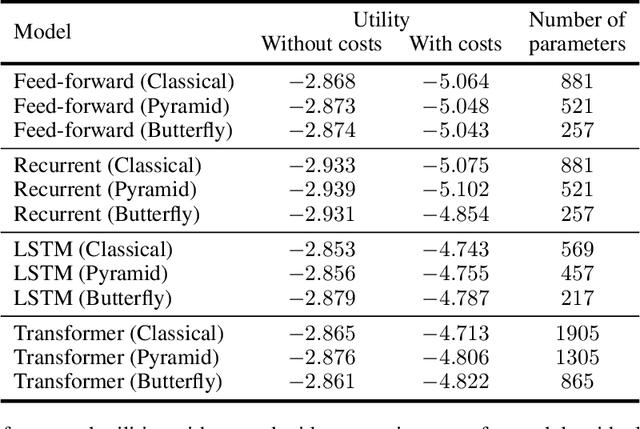
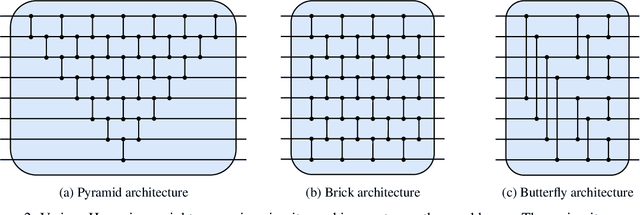
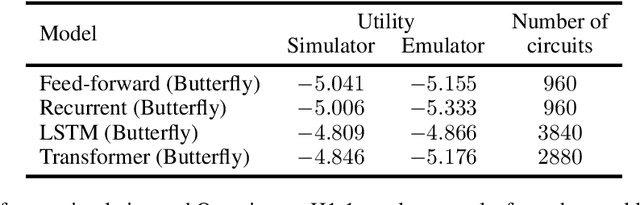
Quantum machine learning has the potential for a transformative impact across industry sectors and in particular in finance. In our work we look at the problem of hedging where deep reinforcement learning offers a powerful framework for real markets. We develop quantum reinforcement learning methods based on policy-search and distributional actor-critic algorithms that use quantum neural network architectures with orthogonal and compound layers for the policy and value functions. We prove that the quantum neural networks we use are trainable, and we perform extensive simulations that show that quantum models can reduce the number of trainable parameters while achieving comparable performance and that the distributional approach obtains better performance than other standard approaches, both classical and quantum. We successfully implement the proposed models on a trapped-ion quantum processor, utilizing circuits with up to $16$ qubits, and observe performance that agrees well with noiseless simulation. Our quantum techniques are general and can be applied to other reinforcement learning problems beyond hedging.
MaSS: Multi-attribute Selective Suppression
Oct 18, 2022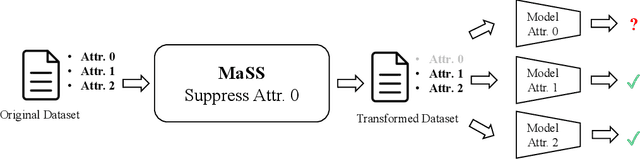

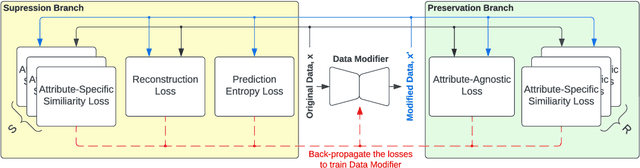
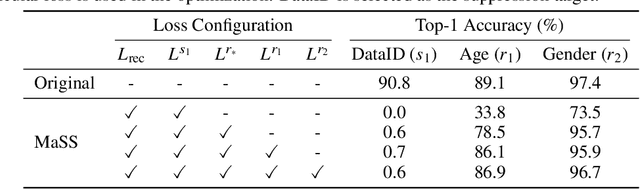
The recent rapid advances in machine learning technologies largely depend on the vast richness of data available today, in terms of both the quantity and the rich content contained within. For example, biometric data such as images and voices could reveal people's attributes like age, gender, sentiment, and origin, whereas location/motion data could be used to infer people's activity levels, transportation modes, and life habits. Along with the new services and applications enabled by such technological advances, various governmental policies are put in place to regulate such data usage and protect people's privacy and rights. As a result, data owners often opt for simple data obfuscation (e.g., blur people's faces in images) or withholding data altogether, which leads to severe data quality degradation and greatly limits the data's potential utility. Aiming for a sophisticated mechanism which gives data owners fine-grained control while retaining the maximal degree of data utility, we propose Multi-attribute Selective Suppression, or MaSS, a general framework for performing precisely targeted data surgery to simultaneously suppress any selected set of attributes while preserving the rest for downstream machine learning tasks. MaSS learns a data modifier through adversarial games between two sets of networks, where one is aimed at suppressing selected attributes, and the other ensures the retention of the rest of the attributes via general contrastive loss as well as explicit classification metrics. We carried out an extensive evaluation of our proposed method using multiple datasets from different domains including facial images, voice audio, and video clips, and obtained promising results in MaSS' generalizability and capability of suppressing targeted attributes without negatively affecting the data's usability in other downstream ML tasks.
Quantum Machine Learning for Finance
Sep 09, 2021Quantum computers are expected to surpass the computational capabilities of classical computers during this decade, and achieve disruptive impact on numerous industry sectors, particularly finance. In fact, finance is estimated to be the first industry sector to benefit from Quantum Computing not only in the medium and long terms, but even in the short term. This review paper presents the state of the art of quantum algorithms for financial applications, with particular focus to those use cases that can be solved via Machine Learning.
A Domain-agnostic, Noise-resistant, Hardware-efficient Evolutionary Variational Quantum Eigensolver
Nov 18, 2019
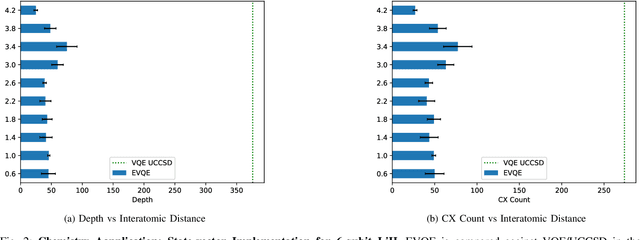
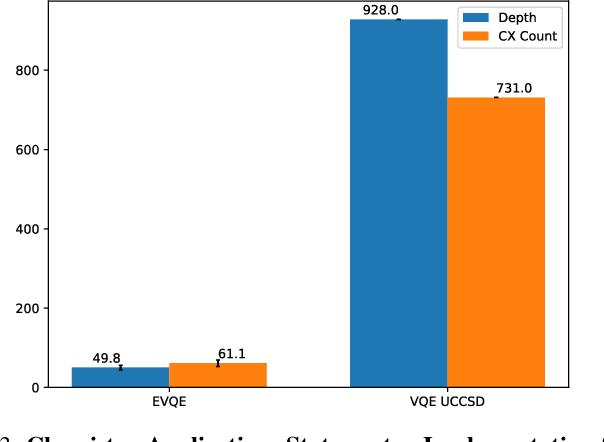
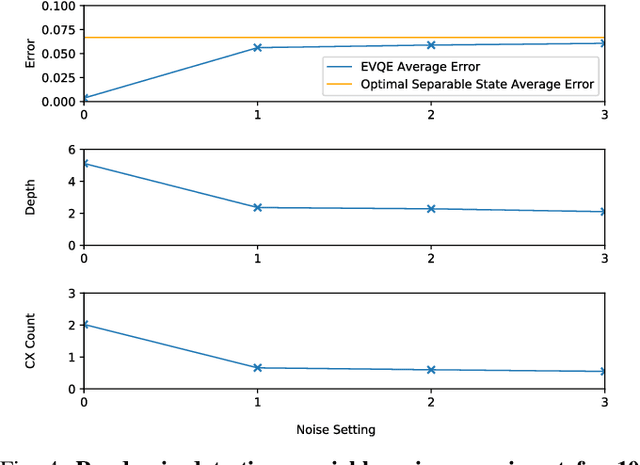
Variational quantum algorithms have shown promise in numerous fields due to their versatility in solving problems of scientific and commercial interest. However, leading algorithms for Hamiltonian simulation, such as the Variational Quantum Eigensolver (VQE), use fixed preconstructed ansatzes, limiting their general applicability and accuracy. Thus, variational forms---the quantum circuits that implement ansatzes ---are either crafted heuristically or by encoding domain-specific knowledge. In this paper, we present an Evolutionary Variational Quantum Eigensolver (EVQE), a novel variational algorithm that uses evolutionary programming techniques to minimize the expectation value of a given Hamiltonian by dynamically generating and optimizing an ansatz. The algorithm is equally applicable to optimization problems in all domains, obtaining accurate energy evaluations with hardware-efficient ansatzes. In molecular simulations, the variational forms generated by EVQE are up to $18.6\times$ shallower and use up to $12\times$ fewer CX gates than those obtained by VQE with a unitary coupled cluster ansatz. EVQE demonstrates significant noise-resistance properties, obtaining results in noisy simulation with at least $3.6\times$ less error than VQE using any tested ansatz configuration. We successfully evaluated EVQE on a real 5-qubit IBMQ quantum computer. The experimental results, which we obtained both via simulation and on real quantum hardware, demonstrate the effectiveness of EVQE for general-purpose optimization on the quantum computers of the present and near future.
STFNets: Learning Sensing Signals from the Time-Frequency Perspective with Short-Time Fourier Neural Networks
Feb 21, 2019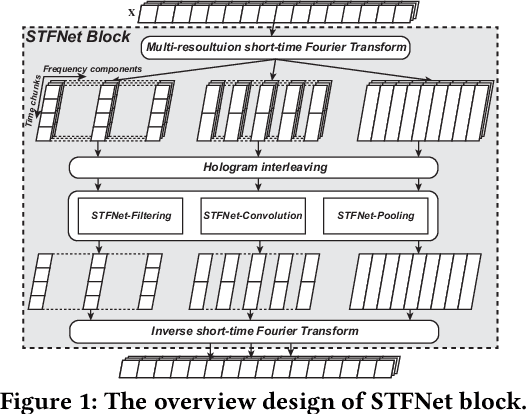
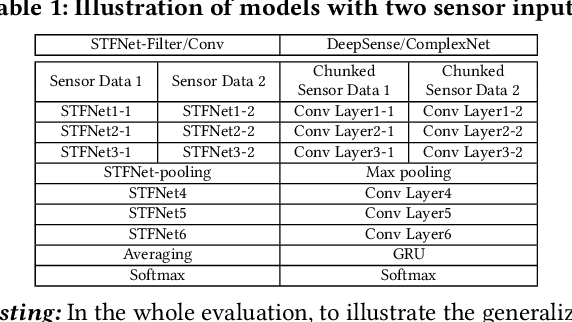
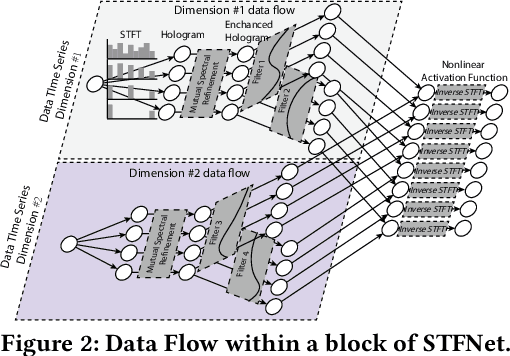
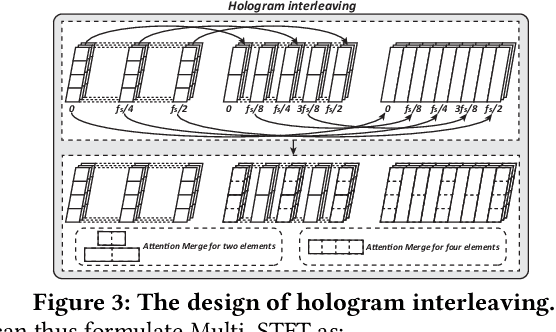
Recent advances in deep learning motivate the use of deep neural networks in Internet-of-Things (IoT) applications. These networks are modelled after signal processing in the human brain, thereby leading to significant advantages at perceptual tasks such as vision and speech recognition. IoT applications, however, often measure physical phenomena, where the underlying physics (such as inertia, wireless signal propagation, or the natural frequency of oscillation) are fundamentally a function of signal frequencies, offering better features in the frequency domain. This observation leads to a fundamental question: For IoT applications, can one develop a new brand of neural network structures that synthesize features inspired not only by the biology of human perception but also by the fundamental nature of physics? Hence, in this paper, instead of using conventional building blocks (e.g., convolutional and recurrent layers), we propose a new foundational neural network building block, the Short-Time Fourier Neural Network (STFNet). It integrates a widely-used time-frequency analysis method, the Short-Time Fourier Transform, into data processing to learn features directly in the frequency domain, where the physics of underlying phenomena leave better foot-prints. STFNets bring additional flexibility to time-frequency analysis by offering novel nonlinear learnable operations that are spectral-compatible. Moreover, STFNets show that transforming signals to a domain that is more connected to the underlying physics greatly simplifies the learning process. We demonstrate the effectiveness of STFNets with extensive experiments. STFNets significantly outperform the state-of-the-art deep learning models in all experiments. A STFNet, therefore, demonstrates superior capability as the fundamental building block of deep neural networks for IoT applications for various sensor inputs.
Multi-scale Neural Networks for Retinal Blood Vessels Segmentation
Apr 11, 2018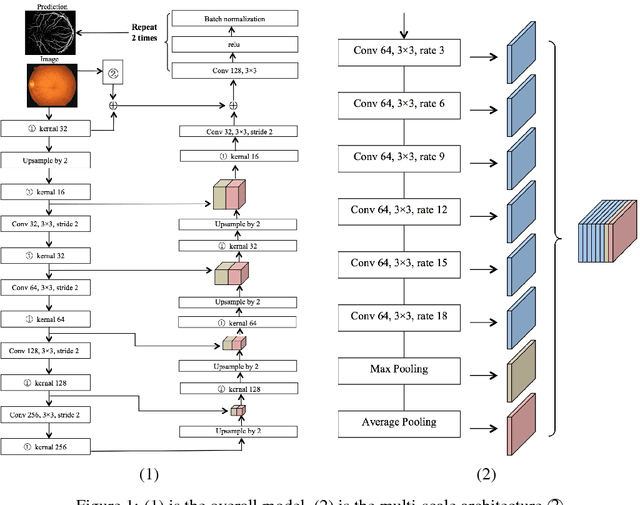
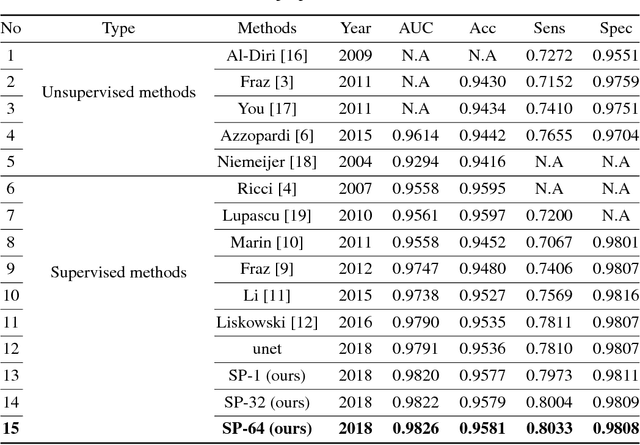

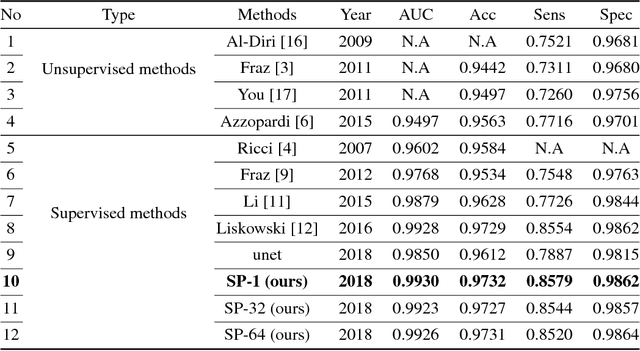
Existing supervised approaches didn't make use of the low-level features which are actually effective to this task. And another deficiency is that they didn't consider the relation between pixels, which means effective features are not extracted. In this paper, we proposed a novel convolutional neural network which make sufficient use of low-level features together with high-level features and involves atrous convolution to get multi-scale features which should be considered as effective features. Our model is tested on three standard benchmarks - DRIVE, STARE, and CHASE databases. The results presents that our model significantly outperforms existing approaches in terms of accuracy, sensitivity, specificity, the area under the ROC curve and the highest prediction speed. Our work provides evidence of the power of wide and deep neural networks in retinal blood vessels segmentation task which could be applied on other medical images tasks.