 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOCAL: Contrastive Learning for Multimodal Time-Series Sensing Signals in Factorized Orthogonal Latent Space
Oct 30, 2023



This paper proposes a novel contrastive learning framework, called FOCAL, for extracting comprehensive features from multimodal time-series sensing signals through self-supervised training. Existing multimodal contrastive frameworks mostly rely on the shared information between sensory modalities, but do not explicitly consider the exclusive modality information that could be critical to understanding the underlying sensing physics. Besides, contrastive frameworks for time series have not handled the temporal information locality appropriately. FOCAL solves these challenges by making the following contributions: First, given multimodal time series, it encodes each modality into a factorized latent space consisting of shared features and private features that are orthogonal to each other. The shared space emphasizes feature patterns consistent across sensory modalities through a modal-matching objective. In contrast, the private space extracts modality-exclusive information through a transformation-invariant objective. Second, we propose a temporal structural constraint for modality features, such that the average distance between temporally neighboring samples is no larger than that of temporally distant samples. Extensive evaluations are performed on four multimodal sensing datasets with two backbone encoders and two classifiers to demonstrate the superiority of FOCAL. It consistently outperforms the state-of-the-art baselines in downstream tasks with a clear margin, under different ratios of available labels. The code and self-collected dataset are available at https://github.com/tomoyoshki/focal.
Self-Contrastive Learning based Semi-Supervised Radio Modulation Classification
Mar 29, 2022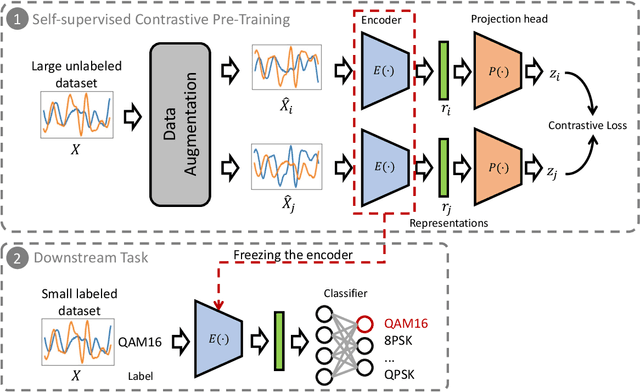
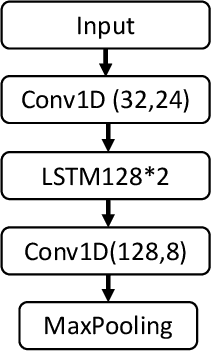
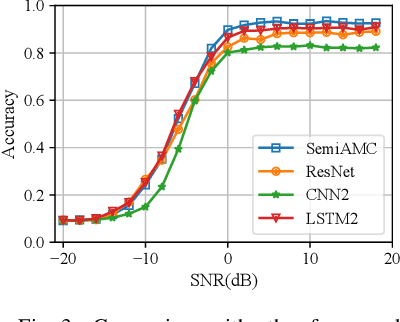
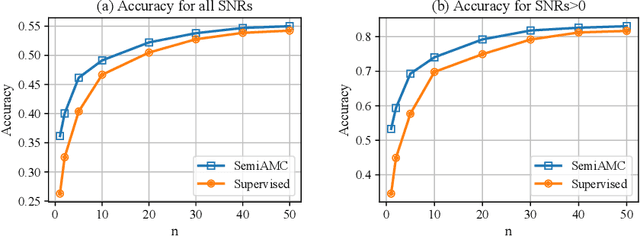
This paper presents a semi-supervised learning framework that is new in being designed for automatic modulation classification (AMC). By carefully utilizing unlabeled signal data with a self-supervised contrastive-learning pre-training step, our framework achieves higher performance given smaller amounts of labeled data, thereby largely reducing the labeling burden of deep learning. We evaluate the performance of our semi-supervised framework on a public dataset. The evaluation results demonstrate that our semi-supervised approach significantly outperforms supervised frameworks thereby substantially enhancing our ability to train deep neural networks for automatic modulation classification in a manner that leverages unlabeled data.
Scheduling Real-time Deep Learning Services as Imprecise Computations
Nov 02, 2020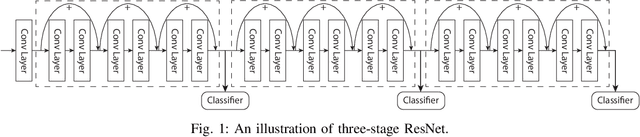
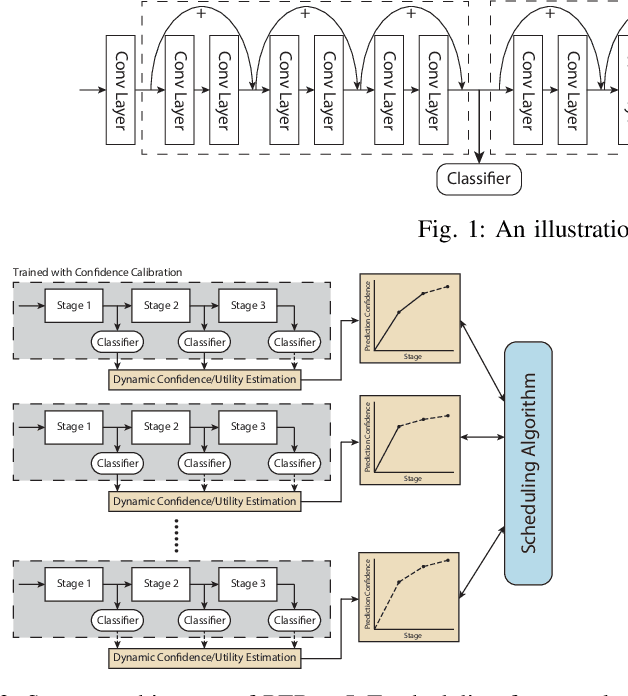
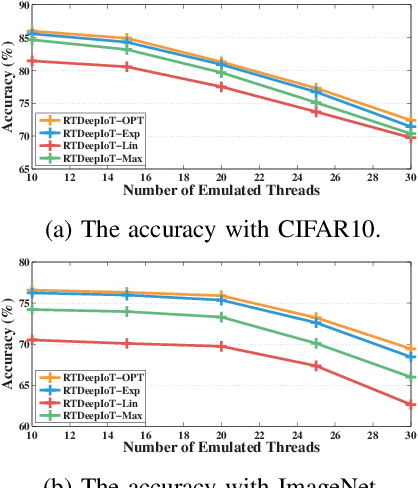
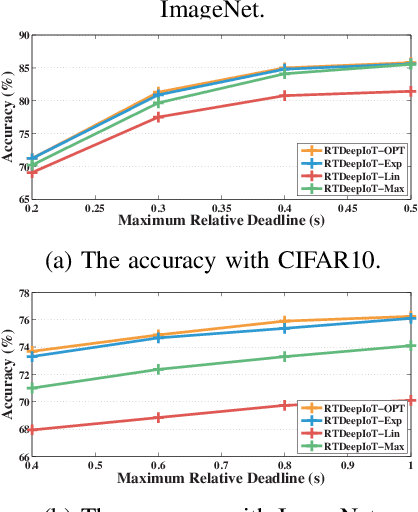
The paper presents an efficient real-time scheduling algorithm for intelligent real-time edge services, defined as those that perform machine intelligence tasks, such as voice recognition, LIDAR processing, or machine vision, on behalf of local embedded devices that are themselves unable to support extensive computations. The work contributes to a recent direction in real-time computing that develops scheduling algorithms for machine intelligence tasks with anytime prediction. We show that deep neural network workflows can be cast as imprecise computations, each with a mandatory part and (several) optional parts whose execution utility depends on input data. The goal of the real-time scheduler is to maximize the average accuracy of deep neural network outputs while meeting task deadlines, thanks to opportunistic shedding of the least necessary optional parts. The work is motivated by the proliferation of increasingly ubiquitous but resource-constrained embedded devices (for applications ranging from autonomous cars to the Internet of Things) and the desire to develop services that endow them with intelligence. Experiments on recent GPU hardware and a state of the art deep neural network for machine vision illustrate that our scheme can increase the overall accuracy by 10%-20% while incurring (nearly) no deadline misses.
Controllable Variational Autoencoder
Apr 13, 2020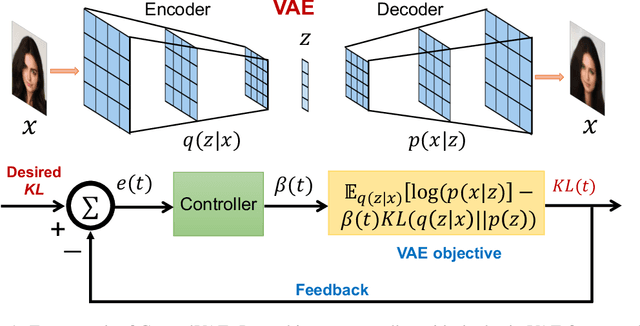

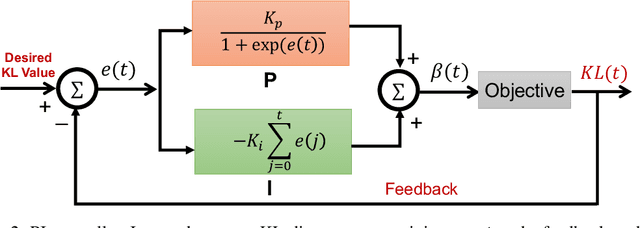

Variational Autoencoders (VAE) and their variants have been widely used in a variety of applications, such as dialog generation, image generation and disentangled representation learning. However, the existing VAE models have some limitations in different applications. For example, a VAE easily suffers from KL vanishing in language modeling and low reconstruction quality for disentangling. To address these issues, we propose a novel controllable variational autoencoder framework, ControlVAE, that combines a controller, inspired by automatic control theory, with the basic VAE to improve the performance of resulting generative models. Specifically, we design a new non-linear PI controller, a variant of the proportional-integral-derivative (PID) control, to automatically tune the hyperparameter (weight) added in the VAE objective using the output KL-divergence as feedback during model training. The framework is evaluated using three applications; namely, language modeling, disentangled representation learning, and image generation. The results show that ControlVAE can achieve better disentangling and reconstruction quality than the existing methods. For language modelling, it not only averts the KL-vanishing, but also improves the diversity of generated text. Finally, we also demonstrate that ControlVAE improves the reconstruction quality of generated images compared to the original VAE.
Disentangling Overlapping Beliefs by Structured Matrix Factorization
Feb 13, 2020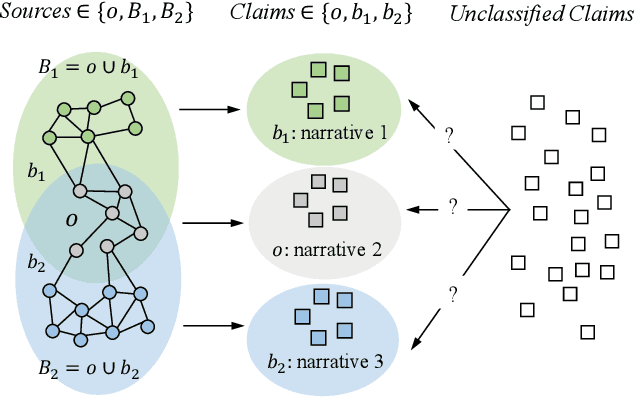


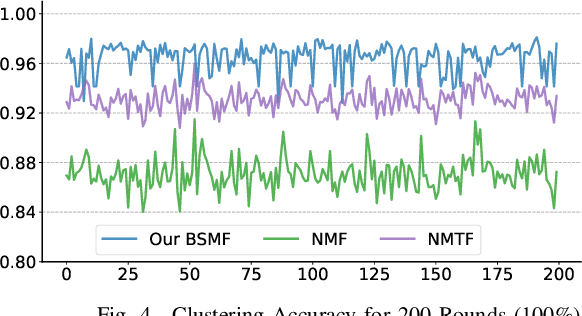
Much work on social media opinion polarization focuses on identifying separate or orthogonal beliefs from media traces, thereby missing points of agreement among different communities. This paper develops a new class of Non-negative Matrix Factorization (NMF) algorithms that allow identification of both agreement and disagreement points when beliefs of different communities partially overlap. Specifically, we propose a novel Belief Structured Matrix Factorization algorithm (BSMF) to identify partially overlapping beliefs in polarized public social media. BSMF is totally unsupervised and considers three types of information: (i) who posted which opinion, (ii) keyword-level message similarity, and (iii) empirically observed social dependency graphs (e.g., retweet graphs), to improve belief separation. In the space of unsupervised belief separation algorithms, the emphasis was mostly given to the problem of identifying disjoint (e.g., conflicting) beliefs. The case when individuals with different beliefs agree on some subset of points was less explored. We observe that social beliefs overlap even in polarized scenarios. Our proposed unsupervised algorithm captures both the latent belief intersections and dissimilarities. We discuss the properties of the algorithm and conduct extensive experiments on both synthetic data and real-world datasets. The results show that our model outperforms all compared baselines by a great margin.
STFNets: Learning Sensing Signals from the Time-Frequency Perspective with Short-Time Fourier Neural Networks
Feb 21, 2019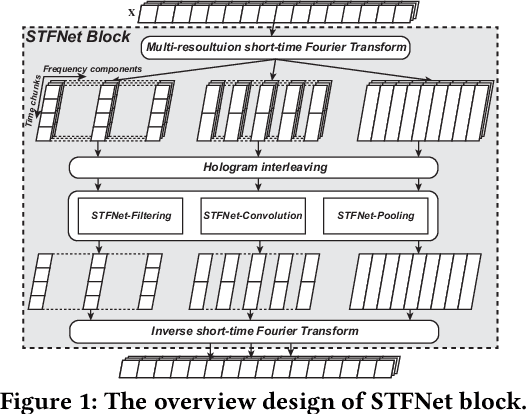
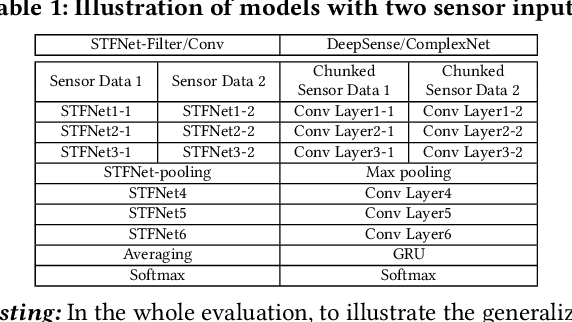
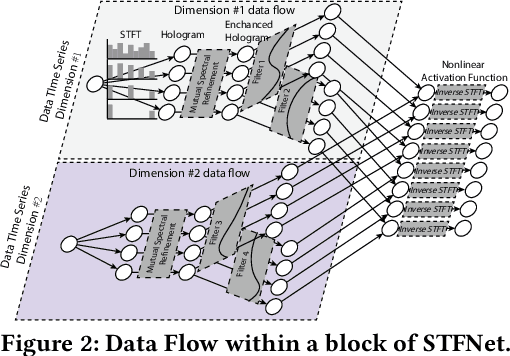
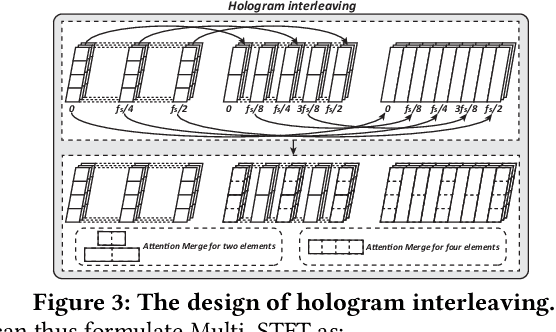
Recent advances in deep learning motivate the use of deep neural networks in Internet-of-Things (IoT) applications. These networks are modelled after signal processing in the human brain, thereby leading to significant advantages at perceptual tasks such as vision and speech recognition. IoT applications, however, often measure physical phenomena, where the underlying physics (such as inertia, wireless signal propagation, or the natural frequency of oscillation) are fundamentally a function of signal frequencies, offering better features in the frequency domain. This observation leads to a fundamental question: For IoT applications, can one develop a new brand of neural network structures that synthesize features inspired not only by the biology of human perception but also by the fundamental nature of physics? Hence, in this paper, instead of using conventional building blocks (e.g., convolutional and recurrent layers), we propose a new foundational neural network building block, the Short-Time Fourier Neural Network (STFNet). It integrates a widely-used time-frequency analysis method, the Short-Time Fourier Transform, into data processing to learn features directly in the frequency domain, where the physics of underlying phenomena leave better foot-prints. STFNets bring additional flexibility to time-frequency analysis by offering novel nonlinear learnable operations that are spectral-compatible. Moreover, STFNets show that transforming signals to a domain that is more connected to the underlying physics greatly simplifies the learning process. We demonstrate the effectiveness of STFNets with extensive experiments. STFNets significantly outperform the state-of-the-art deep learning models in all experiments. A STFNet, therefore, demonstrates superior capability as the fundamental building block of deep neural networks for IoT applications for various sensor inputs.
FastDeepIoT: Towards Understanding and Optimizing Neural Network Execution Time on Mobile and Embedded Devices
Sep 19, 2018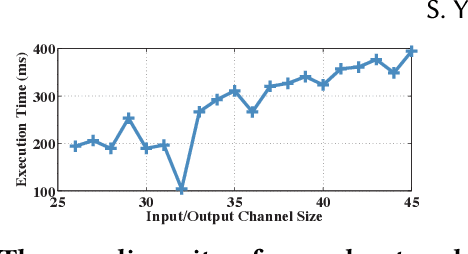



Deep neural networks show great potential as solutions to many sensing application problems, but their excessive resource demand slows down execution time, pausing a serious impediment to deployment on low-end devices. To address this challenge, recent literature focused on compressing neural network size to improve performance. We show that changing neural network size does not proportionally affect performance attributes of interest, such as execution time. Rather, extreme run-time nonlinearities exist over the network configuration space. Hence, we propose a novel framework, called FastDeepIoT, that uncovers the non-linear relation between neural network structure and execution time, then exploits that understanding to find network configurations that significantly improve the trade-off between execution time and accuracy on mobile and embedded devices. FastDeepIoT makes two key contributions. First, FastDeepIoT automatically learns an accurate and highly interpretable execution time model for deep neural networks on the target device. This is done without prior knowledge of either the hardware specifications or the detailed implementation of the used deep learning library. Second, FastDeepIoT informs a compression algorithm how to minimize execution time on the profiled device without impacting accuracy. We evaluate FastDeepIoT using three different sensing-related tasks on two mobile devices: Nexus 5 and Galaxy Nexus. FastDeepIoT further reduces the neural network execution time by $48\%$ to $78\%$ and energy consumption by $37\%$ to $69\%$ compared with the state-of-the-art compression algorithms.