 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobiVital: Self-supervised Time-series Quality Estimation for Contactless Respiration Monitoring Using UWB Radar
Mar 14, 2025Respiration waveforms are increasingly recognized as important biomarkers, offering insights beyond simple respiration rates, such as detecting breathing irregularities for disease diagnosis or monitoring breath patterns to guide rehabilitation training. Previous works in wireless respiration monitoring have primarily focused on estimating respiration rate, where the breath waveforms are often generated as a by-product. As a result, issues such as waveform deformation and inversion have largely been overlooked, reducing the signal's utility for applications requiring breathing waveforms. To address this problem, we present a novel approach, MobiVital, that improves the quality of respiration waveforms obtained from ultra-wideband (UWB) radar data. MobiVital combines a self-supervised autoregressive model for breathing waveform extraction with a biology-informed algorithm to detect and correct waveform inversions. To encourage reproducible research efforts for developing wireless vital signal monitoring systems, we also release a 12-person, 24-hour UWB radar vital signal dataset, with time-synchronized ground truth obtained from wearable sensors. Our results show that the respiration waveforms produced by our system exhibit a 7-34% increase in fidelity to the ground truth compared to the baselines and can benefit downstream tasks such as respiration rate estimation.
Learning-based Block-wise Planar Channel Estimation for Time-Varying MIMO OFDM
May 18, 2024



In this paper, we propose a learning-based block-wise planar channel estimator (LBPCE) with high accuracy and low complexity to estimate the time-varying frequency-selective channel of a multiple-input multiple-output (MIMO) orthogonal frequency-division multiplexing (OFDM) system. First, we establish a block-wise planar channel model (BPCM) to characterize the correlation of the channel across subcarriers and OFDM symbols. Specifically, adjacent subcarriers and OFDM symbols are divided into several sub-blocks, and an affine function (i.e., a plane) with only three variables (namely, mean, time-domain slope, and frequency-domain slope) is used to approximate the channel in each sub-block, which significantly reduces the number of variables to be determined in channel estimation. Second, we design a 3D dilated residual convolutional network (3D-DRCN) that leverages the time-frequency-space-domain correlations of the channel to further improve the channel estimates of each user. Numerical results demonstrate that the proposed significantly outperforms the state-of-the-art estimators and maintains a relatively low computational complexity.
A Fast Maximum Clique Algorithm Based on Network Decomposition for Large Sparse Networks
Apr 19, 2024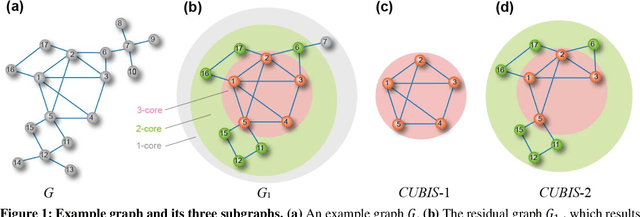
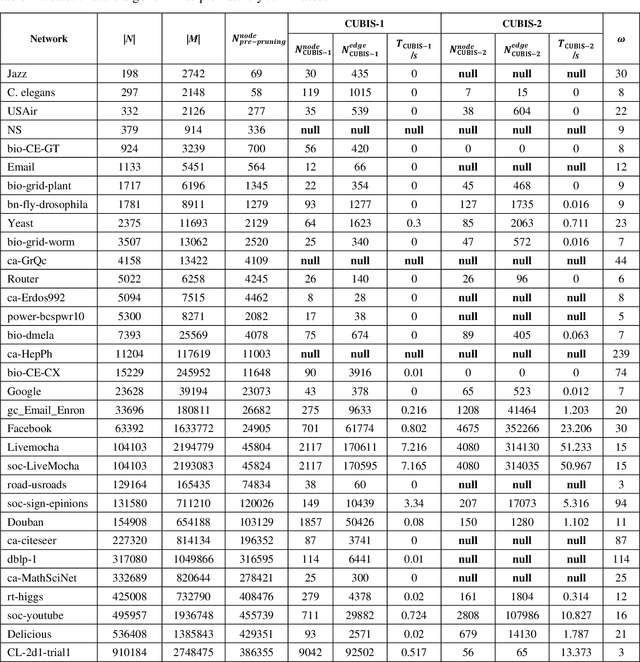
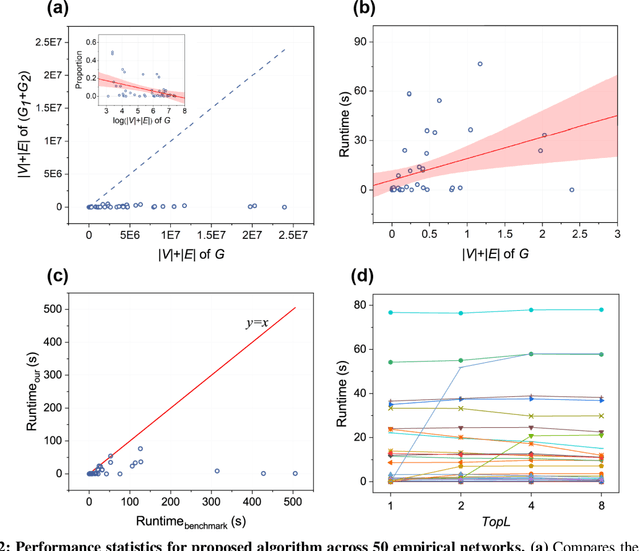
Finding maximum cliques in large networks is a challenging combinatorial problem with many real-world applications. We present a fast algorithm to achieve the exact solution for the maximum clique problem in large sparse networks based on efficient graph decomposition. A bunch of effective techniques is being used to greatly prune the graph and a novel concept called Complete-Upper-Bound-Induced Subgraph (CUBIS) is proposed to ensure that the structures with the potential to form the maximum clique are retained in the process of graph decomposition. Our algorithm first pre-prunes peripheral nodes, subsequently, one or two small-scale CUBISs are constructed guided by the core number and current maximum clique size. Bron-Kerbosch search is performed on each CUBIS to find the maximum clique. Experiments on 50 empirical networks with a scale of up to 20 million show the CUBIS scales are largely independent of the original network scale. This enables an approximately linear runtime, making our algorithm amenable for large networks. Our work provides a new framework for effectively solving maximum clique problems on massive sparse graphs, which not only makes the graph scale no longer the bottleneck but also shows some light on solving other clique-related problems.
A Quick Framework for Evaluating Worst Robustness of Complex Networks
Feb 28, 2024



Robustness is pivotal for comprehending, designing, optimizing, and rehabilitating networks, with simulation attacks being the prevailing evaluation method. Simulation attacks are often time-consuming or even impractical, however, a more crucial yet persistently overlooked drawback is that any attack strategy merely provides a potential paradigm of disintegration. The key concern is: in the worst-case scenario or facing the most severe attacks, what is the limit of robustness, referred to as ``Worst Robustness'', for a given system? Understanding a system's worst robustness is imperative for grasping its reliability limits, accurately evaluating protective capabilities, and determining associated design and security maintenance costs. To address these challenges, we introduce the concept of Most Destruction Attack (MDA) based on the idea of knowledge stacking. MDA is employed to assess the worst robustness of networks, followed by the application of an adapted CNN algorithm for rapid worst robustness prediction. We establish the logical validity of MDA and highlight the exceptional performance of the adapted CNN algorithm in predicting the worst robustness across diverse network topologies, encompassing both model and empirical networks.
Comprehensive Analysis of Network Robustness Evaluation Based on Convolutional Neural Networks with Spatial Pyramid Pooling
Aug 10, 2023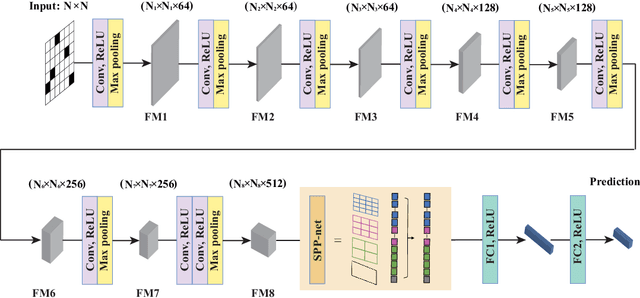

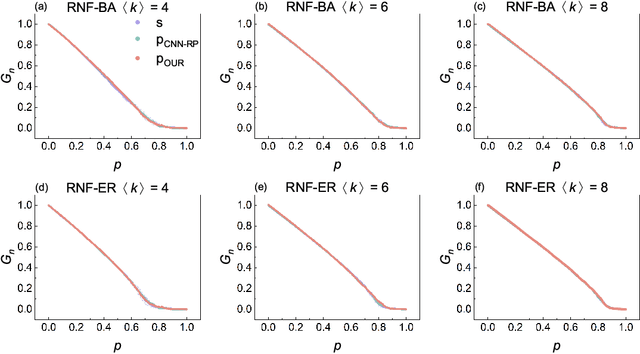

Connectivity robustness, a crucial aspect for understanding, optimizing, and repairing complex networks, has traditionally been evaluated through time-consuming and often impractical simulations. Fortunately, machine learning provides a new avenue for addressing this challenge. However, several key issues remain unresolved, including the performance in more general edge removal scenarios, capturing robustness through attack curves instead of directly training for robustness, scalability of predictive tasks, and transferability of predictive capabilities. In this paper, we address these challenges by designing a convolutional neural networks (CNN) model with spatial pyramid pooling networks (SPP-net), adapting existing evaluation metrics, redesigning the attack modes, introducing appropriate filtering rules, and incorporating the value of robustness as training data. The results demonstrate the thoroughness of the proposed CNN framework in addressing the challenges of high computational time across various network types, failure component types and failure scenarios. However, the performance of the proposed CNN model varies: for evaluation tasks that are consistent with the trained network type, the proposed CNN model consistently achieves accurate evaluations of both attack curves and robustness values across all removal scenarios. When the predicted network type differs from the trained network, the CNN model still demonstrates favorable performance in the scenario of random node failure, showcasing its scalability and performance transferability. Nevertheless, the performance falls short of expectations in other removal scenarios. This observed scenario-sensitivity in the evaluation of network features has been overlooked in previous studies and necessitates further attention and optimization. Lastly, we discuss important unresolved questions and further investigation.
Towards Efficient and Comprehensive Urban Spatial-Temporal Prediction: A Unified Library and Performance Benchmark
Apr 29, 2023



As deep learning technology advances and more urban spatial-temporal data accumulates, an increasing number of deep learning models are being proposed to solve urban spatial-temporal prediction problems. However, there are limitations in the existing field, including open-source data being in various formats and difficult to use, few papers making their code and data openly available, and open-source models often using different frameworks and platforms, making comparisons challenging. A standardized framework is urgently needed to implement and evaluate these methods. To address these issues, we provide a comprehensive review of urban spatial-temporal prediction and propose a unified storage format for spatial-temporal data called atomic files. We also propose LibCity, an open-source library that offers researchers a credible experimental tool and a convenient development framework. In this library, we have reproduced 65 spatial-temporal prediction models and collected 55 spatial-temporal datasets, allowing researchers to conduct comprehensive experiments conveniently. Using LibCity, we conducted a series of experiments to validate the effectiveness of different models and components, and we summarized promising future technology developments and research directions for spatial-temporal prediction. By enabling fair model comparisons, designing a unified data storage format, and simplifying the process of developing new models, LibCity is poised to make significant contributions to the spatial-temporal prediction field.
Continuous Trajectory Generation Based on Two-Stage GAN
Jan 16, 2023



Simulating the human mobility and generating large-scale trajectories are of great use in many real-world applications, such as urban planning, epidemic spreading analysis, and geographic privacy protect. Although many previous works have studied the problem of trajectory generation, the continuity of the generated trajectories has been neglected, which makes these methods useless for practical urban simulation scenarios. To solve this problem, we propose a novel two-stage generative adversarial framework to generate the continuous trajectory on the road network, namely TS-TrajGen, which efficiently integrates prior domain knowledge of human mobility with model-free learning paradigm. Specifically, we build the generator under the human mobility hypothesis of the A* algorithm to learn the human mobility behavior. For the discriminator, we combine the sequential reward with the mobility yaw reward to enhance the effectiveness of the generator. Finally, we propose a novel two-stage generation process to overcome the weak point of the existing stochastic generation process. Extensive experiments on two real-world datasets and two case studies demonstrate that our framework yields significant improvements over the state-of-the-art methods.
Efficient Sampling Algorithms for Approximate Temporal Motif Counting (Extended Version)
Jul 28, 2020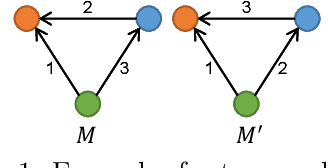

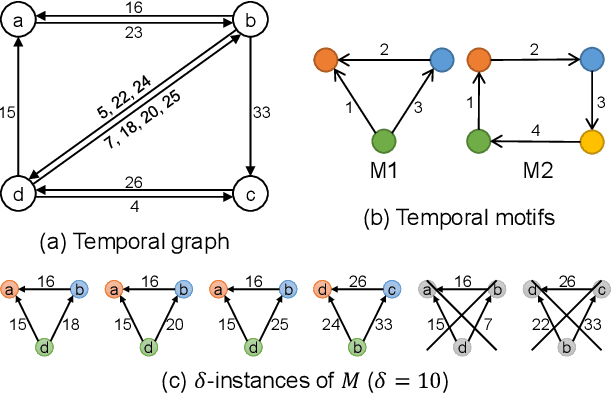
A great variety of complex systems ranging from user interactions in communication networks to transactions in financial markets can be modeled as temporal graphs, which consist of a set of vertices and a series of timestamped and directed edges. Temporal motifs in temporal graphs are generalized from subgraph patterns in static graphs which take into account edge orderings and durations in addition to structures. Counting the number of occurrences of temporal motifs is a fundamental problem for temporal network analysis. However, existing methods either cannot support temporal motifs or suffer from performance issues. In this paper, we focus on approximate temporal motif counting via random sampling. We first propose a generic edge sampling (ES) algorithm for estimating the number of instances of any temporal motif. Furthermore, we devise an improved EWS algorithm that hybridizes edge sampling with wedge sampling for counting temporal motifs with 3 vertices and 3 edges. We provide comprehensive analyses of the theoretical bounds and complexities of our proposed algorithms. Finally, we conduct extensive experiments on several real-world datasets, and the results show that our ES and EWS algorithms have higher efficiency, better accuracy, and greater scalability than the state-of-the-art sampling method for temporal motif counting.
STFNets: Learning Sensing Signals from the Time-Frequency Perspective with Short-Time Fourier Neural Networks
Feb 21, 2019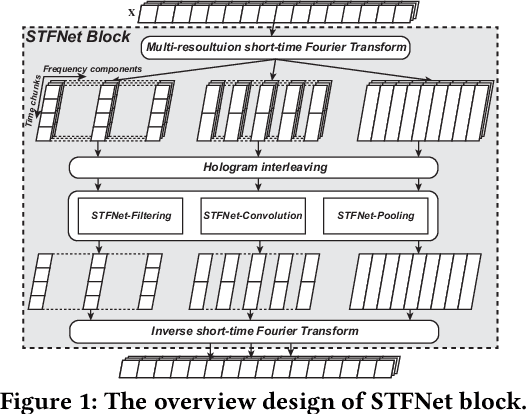
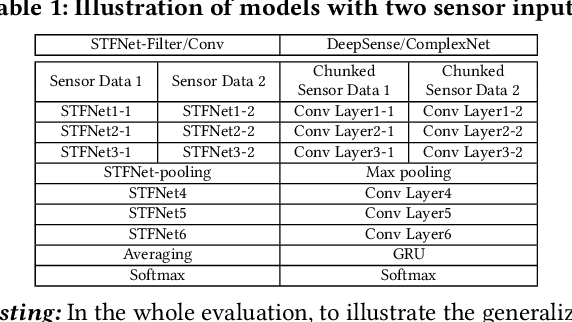
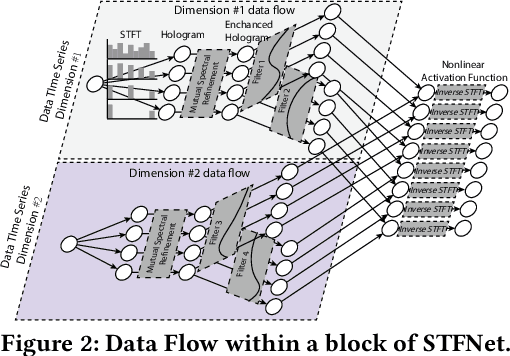
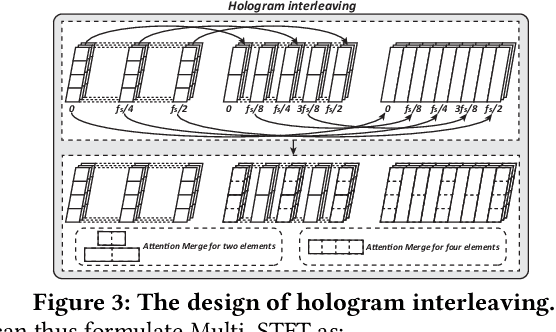
Recent advances in deep learning motivate the use of deep neural networks in Internet-of-Things (IoT) applications. These networks are modelled after signal processing in the human brain, thereby leading to significant advantages at perceptual tasks such as vision and speech recognition. IoT applications, however, often measure physical phenomena, where the underlying physics (such as inertia, wireless signal propagation, or the natural frequency of oscillation) are fundamentally a function of signal frequencies, offering better features in the frequency domain. This observation leads to a fundamental question: For IoT applications, can one develop a new brand of neural network structures that synthesize features inspired not only by the biology of human perception but also by the fundamental nature of physics? Hence, in this paper, instead of using conventional building blocks (e.g., convolutional and recurrent layers), we propose a new foundational neural network building block, the Short-Time Fourier Neural Network (STFNet). It integrates a widely-used time-frequency analysis method, the Short-Time Fourier Transform, into data processing to learn features directly in the frequency domain, where the physics of underlying phenomena leave better foot-prints. STFNets bring additional flexibility to time-frequency analysis by offering novel nonlinear learnable operations that are spectral-compatible. Moreover, STFNets show that transforming signals to a domain that is more connected to the underlying physics greatly simplifies the learning process. We demonstrate the effectiveness of STFNets with extensive experiments. STFNets significantly outperform the state-of-the-art deep learning models in all experiments. A STFNet, therefore, demonstrates superior capability as the fundamental building block of deep neural networks for IoT applications for various sensor inputs.