 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Relational Inference with LLM-Guided Symbolic Dynamics Modeling
Apr 14, 2026Inferring latent interaction structures from observed dynamics is a fundamental inverse problem in many-body interacting systems. Most neural approaches rely on black-box surrogates over trainable graphs, achieving accuracy at the expense of mechanistic interpretability. Symbolic regression offers explicit dynamical equations and stronger inductive biases, but typically assumes known topology and a fixed function library. We propose \textbf{COSINE} (\textbf{C}o-\textbf{O}ptimization of \textbf{S}ymbolic \textbf{I}nteractions and \textbf{N}etwork \textbf{E}dges), a differentiable framework that jointly discovers interaction graphs and sparse symbolic dynamics. To overcome the limitations of fixed symbolic libraries, COSINE further incorporates an outer-loop large language model that adaptively prunes and expands the hypothesis space using feedback from the inner optimization loop. Experiments on synthetic systems and large-scale real-world epidemic data demonstrate robust structural recovery and compact, mechanism-aligned dynamical expressions. Code: https://anonymous.4open.science/r/COSINE-6D43.
Advancing Opinion Dynamics Modeling with Neural Diffusion-Convection-Reaction Equation
Feb 05, 2026Advanced opinion dynamics modeling is vital for deciphering social behavior, emphasizing its role in mitigating polarization and securing cyberspace. To synergize mechanistic interpretability with data-driven flexibility, recent studies have explored the integration of Physics-Informed Neural Networks (PINNs) for opinion modeling. Despite this promise, existing methods are tailored to incomplete priors, lacking a comprehensive physical system to integrate dynamics from local, global, and endogenous levels. Moreover, penalty-based constraints adopted in existing methods struggle to deeply encode physical priors, leading to optimization pathologies and discrepancy between latent representations and physical transparency. To this end, we offer a physical view to interpret opinion dynamics via Diffusion-Convection-Reaction (DCR) system inspired by interacting particle theory. Building upon the Neural ODEs, we define the neural opinion dynamics to coordinate neural networks with physical priors, and further present the OPINN, a physics-informed neural framework for opinion dynamics modeling. Evaluated on real-world and synthetic datasets, OPINN achieves state-of-the-art performance in opinion evolution forecasting, offering a promising paradigm for the nexus of cyber, physical, and social systems.
TopoDIM: One-shot Topology Generation of Diverse Interaction Modes for Multi-Agent Systems
Jan 15, 2026Optimizing communication topology in LLM-based multi-agent system is critical for enabling collective intelligence. Existing methods mainly rely on spatio-temporal interaction paradigms, where the sequential execution of multi-round dialogues incurs high latency and computation. Motivated by the recent insights that evaluation and debate mechanisms can improve problem-solving in multi-agent systems, we propose TopoDIM, a framework for one-shot Topology generation with Diverse Interaction Modes. Designed for decentralized execution to enhance adaptability and privacy, TopoDIM enables agents to autonomously construct heterogeneous communication without iterative coordination, achieving token efficiency and improved task performance. Experiments demonstrate that TopoDIM reduces total token consumption by 46.41% while improving average performance by 1.50% over state-of-the-art methods. Moreover, the framework exhibits strong adaptability in organizing communication among heterogeneous agents. Code is available at: https://anonymous.4open.science/r/TopoDIM-8D35/
Tracking large chemical reaction networks and rare events by neural networks
Dec 13, 2025Chemical reaction networks are widely used to model stochastic dynamics in chemical kinetics, systems biology and epidemiology. Solving the chemical master equation that governs these systems poses a significant challenge due to the large state space exponentially growing with system sizes. The development of autoregressive neural networks offers a flexible framework for this problem; however, its efficiency is limited especially for high-dimensional systems and in scenarios with rare events. Here, we push the frontier of neural-network approach by exploiting faster optimizations such as natural gradient descent and time-dependent variational principle, achieving a 5- to 22-fold speedup, and by leveraging enhanced-sampling strategies to capture rare events. We demonstrate reduced computational cost and higher accuracy over the previous neural-network method in challenging reaction networks, including the mitogen-activated protein kinase (MAPK) cascade network, the hitherto largest biological network handled by the previous approaches of solving the chemical master equation. We further apply the approach to spatially extended reaction-diffusion systems, the Schlögl model with rare events, on two-dimensional lattices, beyond the recent tensor-network approach that handles one-dimensional lattices. The present approach thus enables efficient modeling of chemical reaction networks in general.
A Fast Maximum Clique Algorithm Based on Network Decomposition for Large Sparse Networks
Apr 19, 2024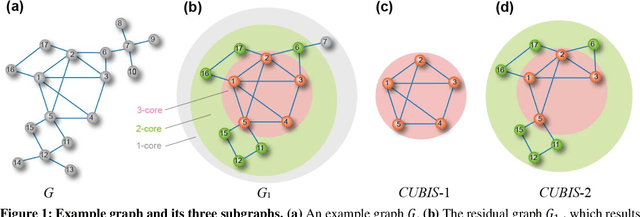
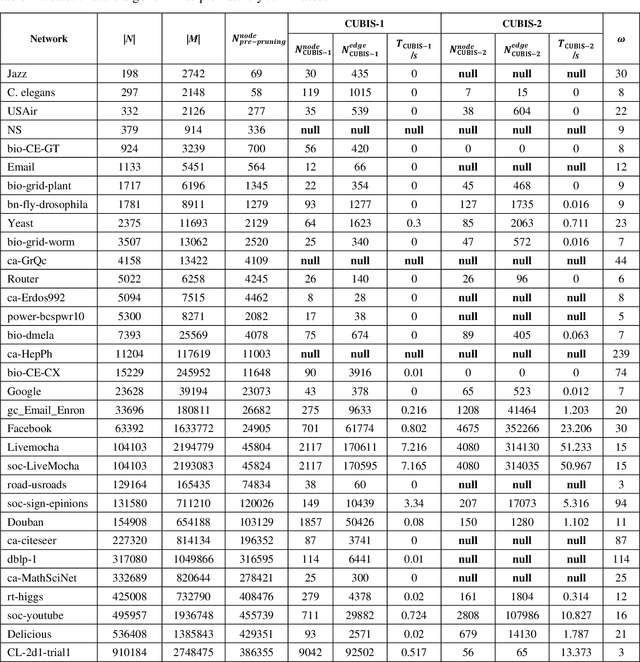
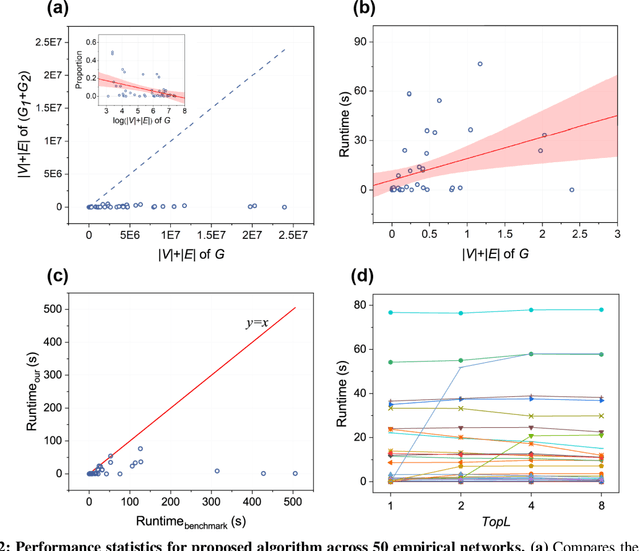
Finding maximum cliques in large networks is a challenging combinatorial problem with many real-world applications. We present a fast algorithm to achieve the exact solution for the maximum clique problem in large sparse networks based on efficient graph decomposition. A bunch of effective techniques is being used to greatly prune the graph and a novel concept called Complete-Upper-Bound-Induced Subgraph (CUBIS) is proposed to ensure that the structures with the potential to form the maximum clique are retained in the process of graph decomposition. Our algorithm first pre-prunes peripheral nodes, subsequently, one or two small-scale CUBISs are constructed guided by the core number and current maximum clique size. Bron-Kerbosch search is performed on each CUBIS to find the maximum clique. Experiments on 50 empirical networks with a scale of up to 20 million show the CUBIS scales are largely independent of the original network scale. This enables an approximately linear runtime, making our algorithm amenable for large networks. Our work provides a new framework for effectively solving maximum clique problems on massive sparse graphs, which not only makes the graph scale no longer the bottleneck but also shows some light on solving other clique-related problems.
Cooperative Network Learning for Large-Scale and Decentralized Graphs
Nov 07, 2023


Graph research, the systematic study of interconnected data points represented as graphs, plays a vital role in capturing intricate relationships within networked systems. However, in the real world, as graphs scale up, concerns about data security among different data-owning agencies arise, hindering information sharing and, ultimately, the utilization of graph data. Therefore, establishing a mutual trust mechanism among graph agencies is crucial for unlocking the full potential of graphs. Here, we introduce a Cooperative Network Learning (CNL) framework to ensure secure graph computing for various graph tasks. Essentially, this CNL framework unifies the local and global perspectives of GNN computing with distributed data for an agency by virtually connecting all participating agencies as a global graph without a fixed central coordinator. Inter-agency computing is protected by various technologies inherent in our framework, including homomorphic encryption and secure transmission. Moreover, each agency has a fair right to design or employ various graph learning models from its local or global perspective. Thus, CNL can collaboratively train GNN models based on decentralized graphs inferred from local and global graphs. Experiments on contagion dynamics prediction and traditional graph tasks (i.e., node classification and link prediction) demonstrate that our CNL architecture outperforms state-of-the-art GNNs developed at individual sites, revealing that CNL can provide a reliable, fair, secure, privacy-preserving, and global perspective to build effective and personalized models for network applications. We hope this framework will address privacy concerns in graph-related research and integrate decentralized graph data structures to benefit the network research community in cooperation and innovation.
Higher-order Graph Convolutional Network with Flower-Petals Laplacians on Simplicial Complexes
Sep 22, 2023


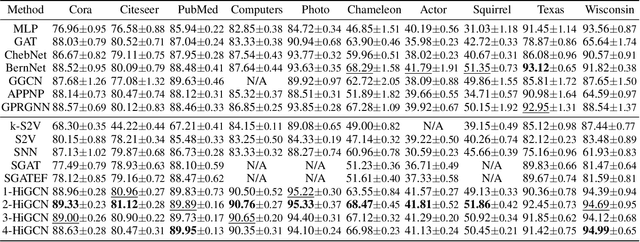
Despite the recent successes of vanilla Graph Neural Networks (GNNs) on many tasks, their foundation on pairwise interaction networks inherently limits their capacity to discern latent higher-order interactions in complex systems. To bridge this capability gap, we propose a novel approach exploiting the rich mathematical theory of simplicial complexes (SCs) - a robust tool for modeling higher-order interactions. Current SC-based GNNs are burdened by high complexity and rigidity, and quantifying higher-order interaction strengths remains challenging. Innovatively, we present a higher-order Flower-Petals (FP) model, incorporating FP Laplacians into SCs. Further, we introduce a Higher-order Graph Convolutional Network (HiGCN) grounded in FP Laplacians, capable of discerning intrinsic features across varying topological scales. By employing learnable graph filters, a parameter group within each FP Laplacian domain, we can identify diverse patterns where the filters' weights serve as a quantifiable measure of higher-order interaction strengths. The theoretical underpinnings of HiGCN's advanced expressiveness are rigorously demonstrated. Additionally, our empirical investigations reveal that the proposed model accomplishes state-of-the-art (SOTA) performance on a range of graph tasks and provides a scalable and flexible solution to explore higher-order interactions in graphs.
Influential Simplices Mining via Simplicial Convolutional Network
Jul 11, 2023



Simplicial complexes have recently been in the limelight of higher-order network analysis, where a minority of simplices play crucial roles in structures and functions due to network heterogeneity. We find a significant inconsistency between identifying influential nodes and simplices. Therefore, it remains elusive how to characterize simplices' influence and identify influential simplices, despite the relative maturity of research on influential nodes (0-simplices) identification. Meanwhile, graph neural networks (GNNs) are potent tools that can exploit network topology and node features simultaneously, but they struggle to tackle higher-order tasks. In this paper, we propose a higher-order graph learning model, named influential simplices mining neural network (ISMnet), to identify vital h-simplices in simplicial complexes. It can tackle higher-order tasks by leveraging novel higher-order presentations: hierarchical bipartite graphs and higher-order hierarchical (HoH) Laplacians, where targeted simplices are grouped into a hub set and can interact with other simplices. Furthermore, ISMnet employs learnable graph convolutional operators in each HoH Laplacian domain to capture interactions among simplices, and it can identify influential simplices of arbitrary order by changing the hub set. Empirical results demonstrate that ISMnet significantly outperforms existing methods in ranking 0-simplices (nodes) and 2-simplices. In general, this novel framework excels in identifying influential simplices and promises to serve as a potent tool in higher-order network analysis.
DynamicLight: Dynamically Tuning Traffic Signal Duration with DRL
Nov 02, 2022



Deep reinforcement learning (DRL) is becoming increasingly popular in implementing traffic signal control (TSC). However, most existing DRL methods employ fixed control strategies, making traffic signal phase duration less flexible. Additionally, the trend of using more complex DRL models makes real-life deployment more challenging. To address these two challenges, we firstly propose a two-stage DRL framework, named DynamicLight, which uses Max Queue-Length to select the proper phase and employs a deep Q-learning network to determine the duration of the corresponding phase. Based on the design of DynamicLight, we also introduce two variants: (1) DynamicLight-Lite, which addresses the first challenge by using only 19 parameters to achieve dynamic phase duration settings; and (2) DynamicLight-Cycle, which tackles the second challenge by actuating a set of phases in a fixed cyclical order to implement flexible phase duration in the respective cyclical phase structure. Numerical experiments are conducted using both real-world and synthetic datasets, covering four most commonly adopted traffic signal intersections in real life. Experimental results show that: (1) DynamicLight can learn satisfactorily on determining the phase duration and achieve a new state-of-the-art, with improvement up to 6% compared to the baselines in terms of adjusted average travel time; (2) DynamicLight-Lite matches or outperforms most baseline methods with only 19 parameters; and (3) DynamicLight-Cycle demonstrates high performance for current TSC systems without remarkable modification in an actual deployment. Our code is released at Github.
Expression is enough: Improving traffic signal control with advanced traffic state representation
Dec 19, 2021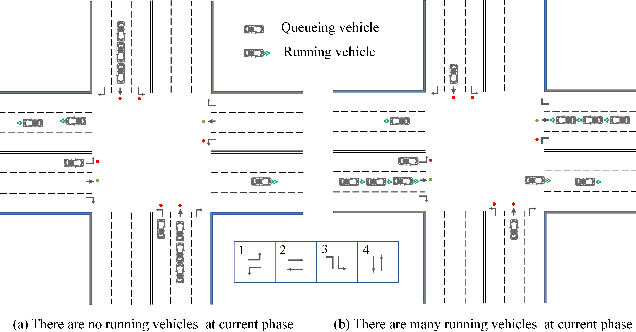

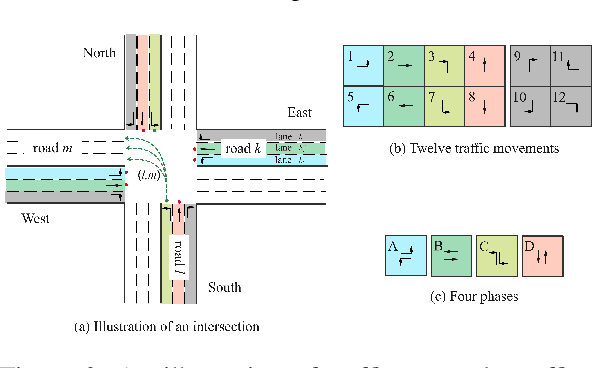

Recently, finding fundamental properties for traffic state representation is more critical than complex algorithms for traffic signal control (TSC).In this paper, we (1) present a novel, flexible and straightforward method advanced max pressure (Advanced-MP), taking both running and queueing vehicles into consideration to decide whether to change current phase; (2) novelty design the traffic movement representation with the efficient pressure and effective running vehicles from Advanced-MP, namely advanced traffic state (ATS); (3) develop an RL-based algorithm template Advanced-XLight, by combining ATS with current RL approaches and generate two RL algorithms, "Advanced-MPLight" and "Advanced-CoLight". Comprehensive experiments on multiple real-world datasets show that: (1) the Advanced-MP outperforms baseline methods, which is efficient and reliable for deployment; (2) Advanced-MPLight and Advanced-CoLight could achieve new state-of-the-art. Our code is released on Github.