 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCFLight: Enhancing Safety with Traffic Signal Control through Counterfactual Learning
Dec 16, 2025Traffic accidents result in millions of injuries and fatalities globally, with a significant number occurring at intersections each year. Traffic Signal Control (TSC) is an effective strategy for enhancing safety at these urban junctures. Despite the growing popularity of Reinforcement Learning (RL) methods in optimizing TSC, these methods often prioritize driving efficiency over safety, thus failing to address the critical balance between these two aspects. Additionally, these methods usually need more interpretability. CounterFactual (CF) learning is a promising approach for various causal analysis fields. In this study, we introduce a novel framework to improve RL for safety aspects in TSC. This framework introduces a novel method based on CF learning to address the question: ``What if, when an unsafe event occurs, we backtrack to perform alternative actions, and will this unsafe event still occur in the subsequent period?'' To answer this question, we propose a new structure causal model to predict the result after executing different actions, and we propose a new CF module that integrates with additional ``X'' modules to promote safe RL practices. Our new algorithm, CFLight, which is derived from this framework, effectively tackles challenging safety events and significantly improves safety at intersections through a near-zero collision control strategy. Through extensive numerical experiments on both real-world and synthetic datasets, we demonstrate that CFLight reduces collisions and improves overall traffic performance compared to conventional RL methods and the recent safe RL model. Moreover, our method represents a generalized and safe framework for RL methods, opening possibilities for applications in other domains. The data and code are available in the github https://github.com/AdvancedAI-ComplexSystem/SmartCity/tree/main/CFLight.
Unified Video Editing with Temporal Reasoner
Dec 08, 2025Existing video editing methods face a critical trade-off: expert models offer precision but rely on task-specific priors like masks, hindering unification; conversely, unified temporal in-context learning models are mask-free but lack explicit spatial cues, leading to weak instruction-to-region mapping and imprecise localization. To resolve this conflict, we propose VideoCoF, a novel Chain-of-Frames approach inspired by Chain-of-Thought reasoning. VideoCoF enforces a ``see, reason, then edit" procedure by compelling the video diffusion model to first predict reasoning tokens (edit-region latents) before generating the target video tokens. This explicit reasoning step removes the need for user-provided masks while achieving precise instruction-to-region alignment and fine-grained video editing. Furthermore, we introduce a RoPE alignment strategy that leverages these reasoning tokens to ensure motion alignment and enable length extrapolation beyond the training duration. We demonstrate that with a minimal data cost of only 50k video pairs, VideoCoF achieves state-of-the-art performance on VideoCoF-Bench, validating the efficiency and effectiveness of our approach. Our code, weight, data are available at https://github.com/knightyxp/VideoCoF.
OTARo: Once Tuning for All Precisions toward Robust On-Device LLMs
Nov 17, 2025Large Language Models (LLMs) fine-tuning techniques not only improve the adaptability to diverse downstream tasks, but also mitigate adverse effects of model quantization. Despite this, conventional quantization suffers from its structural limitation that hinders flexibility during the fine-tuning and deployment stages. Practical on-device tasks demand different quantization precisions (i.e. different bit-widths), e.g., understanding tasks tend to exhibit higher tolerance to reduced precision compared to generation tasks. Conventional quantization, typically relying on scaling factors that are incompatible across bit-widths, fails to support the on-device switching of precisions when confronted with complex real-world scenarios. To overcome the dilemma, we propose OTARo, a novel method that enables on-device LLMs to flexibly switch quantization precisions while maintaining performance robustness through once fine-tuning. OTARo introduces Shared Exponent Floating Point (SEFP), a distinct quantization mechanism, to produce different bit-widths through simple mantissa truncations of a single model. Moreover, to achieve bit-width robustness in downstream applications, OTARo performs a learning process toward losses induced by different bit-widths. The method involves two critical strategies: (1) Exploitation-Exploration Bit-Width Path Search (BPS), which iteratively updates the search path via a designed scoring mechanism; (2) Low-Precision Asynchronous Accumulation (LAA), which performs asynchronous gradient accumulations and delayed updates under low bit-widths. Experiments on popular LLMs, e.g., LLaMA3.2-1B, LLaMA3-8B, demonstrate that OTARo achieves consistently strong and robust performance for all precisions.
VAEVQ: Enhancing Discrete Visual Tokenization through Variational Modeling
Nov 10, 2025Vector quantization (VQ) transforms continuous image features into discrete representations, providing compressed, tokenized inputs for generative models. However, VQ-based frameworks suffer from several issues, such as non-smooth latent spaces, weak alignment between representations before and after quantization, and poor coherence between the continuous and discrete domains. These issues lead to unstable codeword learning and underutilized codebooks, ultimately degrading the performance of both reconstruction and downstream generation tasks. To this end, we propose VAEVQ, which comprises three key components: (1) Variational Latent Quantization (VLQ), replacing the AE with a VAE for quantization to leverage its structured and smooth latent space, thereby facilitating more effective codeword activation; (2) Representation Coherence Strategy (RCS), adaptively modulating the alignment strength between pre- and post-quantization features to enhance consistency and prevent overfitting to noise; and (3) Distribution Consistency Regularization (DCR), aligning the entire codebook distribution with the continuous latent distribution to improve utilization. Extensive experiments on two benchmark datasets demonstrate that VAEVQ outperforms state-of-the-art methods.
AIM: Software and Hardware Co-design for Architecture-level IR-drop Mitigation in High-performance PIM
Nov 06, 2025



SRAM Processing-in-Memory (PIM) has emerged as the most promising implementation for high-performance PIM, delivering superior computing density, energy efficiency, and computational precision. However, the pursuit of higher performance necessitates more complex circuit designs and increased operating frequencies, which exacerbate IR-drop issues. Severe IR-drop can significantly degrade chip performance and even threaten reliability. Conventional circuit-level IR-drop mitigation methods, such as back-end optimizations, are resource-intensive and often compromise power, performance, and area (PPA). To address these challenges, we propose AIM, comprehensive software and hardware co-design for architecture-level IR-drop mitigation in high-performance PIM. Initially, leveraging the bit-serial and in-situ dataflow processing properties of PIM, we introduce Rtog and HR, which establish a direct correlation between PIM workloads and IR-drop. Building on this foundation, we propose LHR and WDS, enabling extensive exploration of architecture-level IR-drop mitigation while maintaining computational accuracy through software optimization. Subsequently, we develop IR-Booster, a dynamic adjustment mechanism that integrates software-level HR information with hardware-based IR-drop monitoring to adapt the V-f pairs of the PIM macro, achieving enhanced energy efficiency and performance. Finally, we propose the HR-aware task mapping method, bridging software and hardware designs to achieve optimal improvement. Post-layout simulation results on a 7nm 256-TOPS PIM chip demonstrate that AIM achieves up to 69.2% IR-drop mitigation, resulting in 2.29x energy efficiency improvement and 1.152x speedup.
MEGG: Replay via Maximally Extreme GGscore in Incremental Learning for Neural Recommendation Models
Sep 09, 2025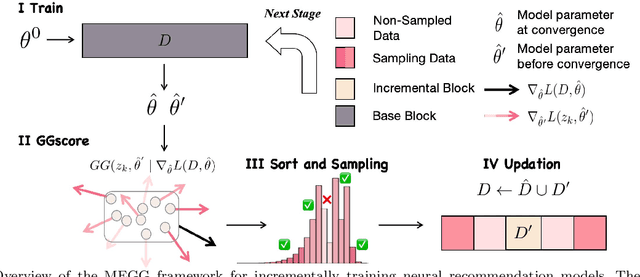
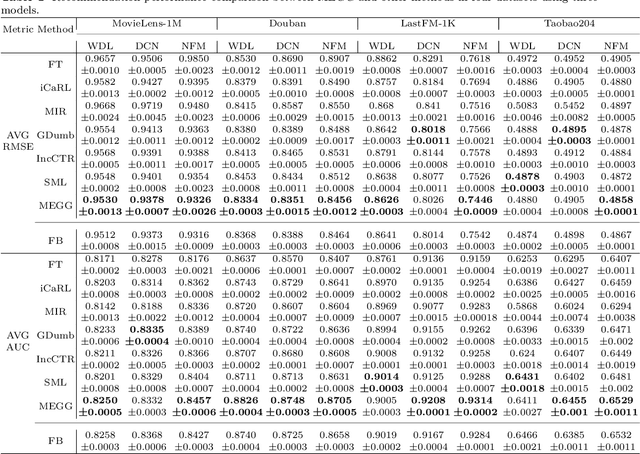
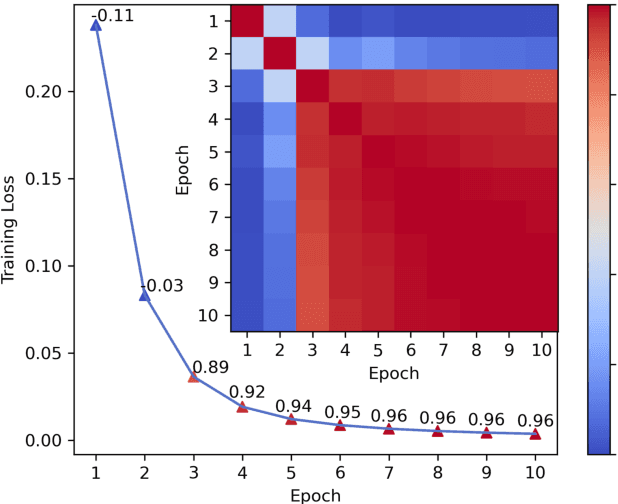
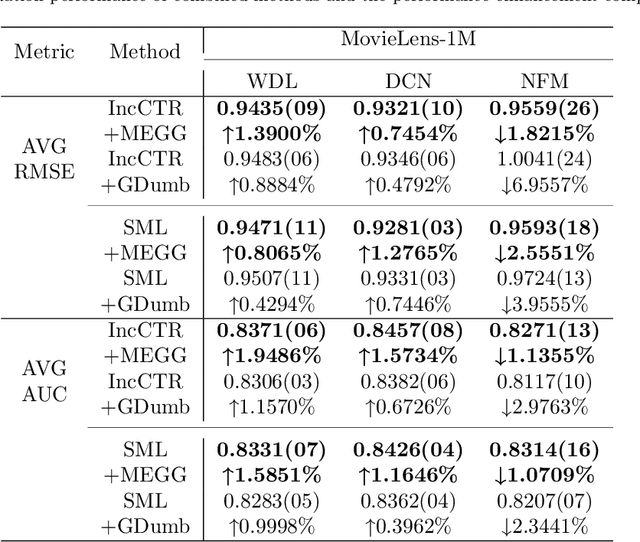
Neural Collaborative Filtering models are widely used in recommender systems but are typically trained under static settings, assuming fixed data distributions. This limits their applicability in dynamic environments where user preferences evolve. Incremental learning offers a promising solution, yet conventional methods from computer vision or NLP face challenges in recommendation tasks due to data sparsity and distinct task paradigms. Existing approaches for neural recommenders remain limited and often lack generalizability. To address this, we propose MEGG, Replay Samples with Maximally Extreme GGscore, an experience replay based incremental learning framework. MEGG introduces GGscore, a novel metric that quantifies sample influence, enabling the selective replay of highly influential samples to mitigate catastrophic forgetting. Being model-agnostic, MEGG integrates seamlessly across architectures and frameworks. Experiments on three neural models and four benchmark datasets show superior performance over state-of-the-art baselines, with strong scalability, efficiency, and robustness. Implementation will be released publicly upon acceptance.
JointSplat: Probabilistic Joint Flow-Depth Optimization for Sparse-View Gaussian Splatting
Jun 04, 2025Reconstructing 3D scenes from sparse viewpoints is a long-standing challenge with wide applications. Recent advances in feed-forward 3D Gaussian sparse-view reconstruction methods provide an efficient solution for real-time novel view synthesis by leveraging geometric priors learned from large-scale multi-view datasets and computing 3D Gaussian centers via back-projection. Despite offering strong geometric cues, both feed-forward multi-view depth estimation and flow-depth joint estimation face key limitations: the former suffers from mislocation and artifact issues in low-texture or repetitive regions, while the latter is prone to local noise and global inconsistency due to unreliable matches when ground-truth flow supervision is unavailable. To overcome this, we propose JointSplat, a unified framework that leverages the complementarity between optical flow and depth via a novel probabilistic optimization mechanism. Specifically, this pixel-level mechanism scales the information fusion between depth and flow based on the matching probability of optical flow during training. Building upon the above mechanism, we further propose a novel multi-view depth-consistency loss to leverage the reliability of supervision while suppressing misleading gradients in uncertain areas. Evaluated on RealEstate10K and ACID, JointSplat consistently outperforms state-of-the-art (SOTA) methods, demonstrating the effectiveness and robustness of our proposed probabilistic joint flow-depth optimization approach for high-fidelity sparse-view 3D reconstruction.
Enhancing News Recommendation with Hierarchical LLM Prompting
Apr 29, 2025



Personalized news recommendation systems often struggle to effectively capture the complexity of user preferences, as they rely heavily on shallow representations, such as article titles and abstracts. To address this problem, we introduce a novel method, namely PNR-LLM, for Large Language Models for Personalized News Recommendation. Specifically, PNR-LLM harnesses the generation capabilities of LLMs to enrich news titles and abstracts, and consequently improves recommendation quality. PNR-LLM contains a novel module, News Enrichment via LLMs, which generates deeper semantic information and relevant entities from articles, transforming shallow contents into richer representations. We further propose an attention mechanism to aggregate enriched semantic- and entity-level data, forming unified user and news embeddings that reveal a more accurate user-news match. Extensive experiments on MIND datasets show that PNR-LLM outperforms state-of-the-art baselines. Moreover, the proposed data enrichment module is model-agnostic, and we empirically show that applying our proposed module to multiple existing models can further improve their performance, verifying the advantage of our design.
ANNs-SaDE: A Machine-Learning-Based Design Automation Framework for Microwave Branch-Line Couplers
Mar 31, 2025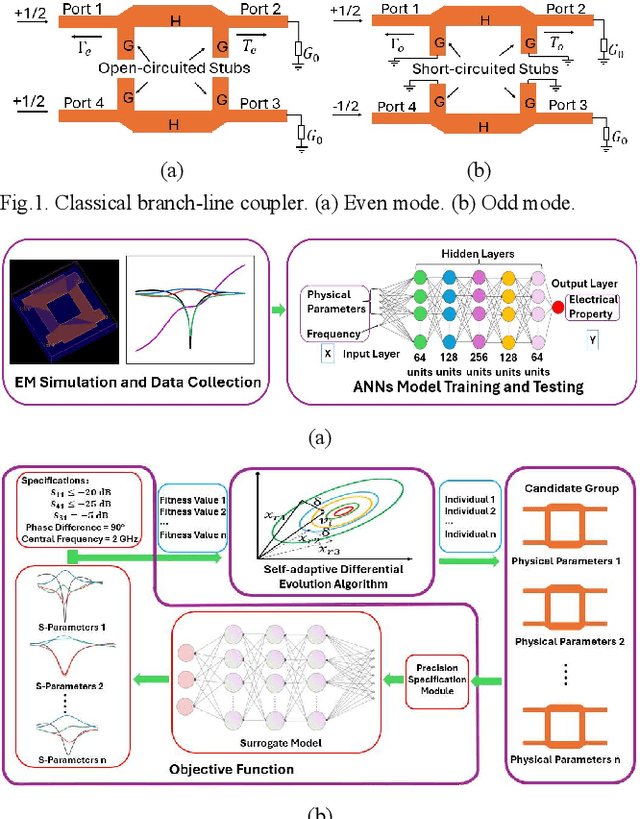
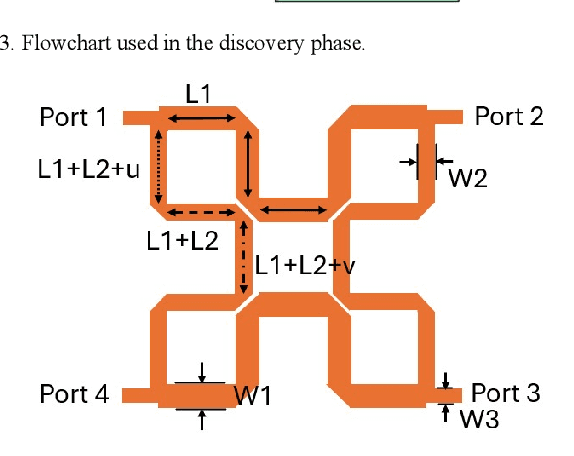
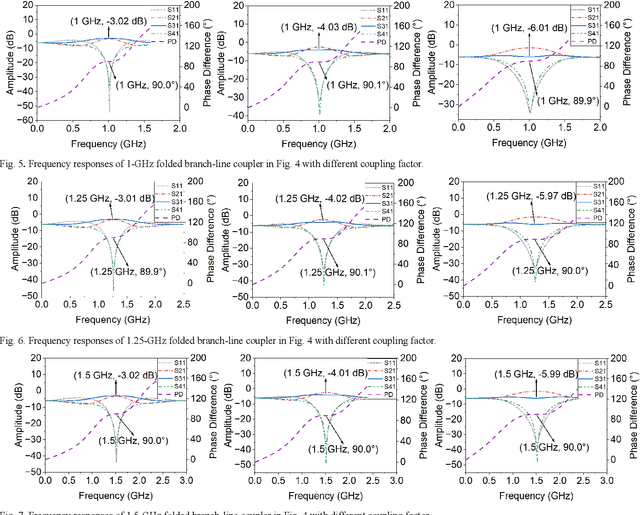
The traditional method for designing branch-line couplers involves a trial-and-error optimization process that requires multiple design iterations through electromagnetic (EM) simulations. Thus, it is extremely time consuming and labor intensive. In this paper, a novel machine-learning-based framework is proposed to tackle this issue. It integrates artificial neural networks with a self-adaptive differential evolution algorithm (ANNs-SaDE). This framework enables the self-adaptive design of various types of microwave branch-line couplers by precisely optimizing essential electrical properties, such as coupling factor, isolation, and phase difference between output ports. The effectiveness of the ANNs-SaDE framework is demonstrated by the designs of folded single-stage branch-line couplers and multi-stage wideband branch-line couplers.
A Parallel Hybrid Action Space Reinforcement Learning Model for Real-world Adaptive Traffic Signal Control
Mar 18, 2025Adaptive traffic signal control (ATSC) can effectively reduce vehicle travel times by dynamically adjusting signal timings but poses a critical challenge in real-world scenarios due to the complexity of real-time decision-making in dynamic and uncertain traffic conditions. The burgeoning field of intelligent transportation systems, bolstered by artificial intelligence techniques and extensive data availability, offers new prospects for the implementation of ATSC. In this study, we introduce a parallel hybrid action space reinforcement learning model (PH-DDPG) that optimizes traffic signal phase and duration of traffic signals simultaneously, eliminating the need for sequential decision-making seen in traditional two-stage models. Our model features a task-specific parallel hybrid action space tailored for adaptive traffic control, which directly outputs discrete phase selections and their associated continuous duration parameters concurrently, thereby inherently addressing dynamic traffic adaptation through unified parametric optimization. %Our model features a unique parallel hybrid action space that allows for the simultaneous output of each action and its optimal parameters, streamlining the decision-making process. Furthermore, to ascertain the robustness and effectiveness of this approach, we executed ablation studies focusing on the utilization of a random action parameter mask within the critic network, which decouples the parameter space for individual actions, facilitating the use of preferable parameters for each action. The results from these studies confirm the efficacy of this method, distinctly enhancing real-world applicability