 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMSeg: Unleashing the Power of Large-Scale Models for Open-Vocabulary Semantic Segmentation
Nov 30, 2024


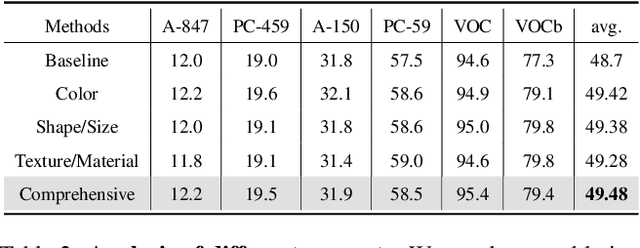
It is widely agreed that open-vocabulary-based approaches outperform classical closed-set training solutions for recognizing unseen objects in images for semantic segmentation. Existing open-vocabulary approaches leverage vision-language models, such as CLIP, to align visual features with rich semantic features acquired through pre-training on large-scale vision-language datasets. However, the text prompts employed in these methods are short phrases based on fixed templates, failing to capture comprehensive object attributes. Moreover, while the CLIP model excels at exploiting image-level features, it is less effective at pixel-level representation, which is crucial for semantic segmentation tasks. In this work, we propose to alleviate the above-mentioned issues by leveraging multiple large-scale models to enhance the alignment between fine-grained visual features and enriched linguistic features. Specifically, our method employs large language models (LLMs) to generate enriched language prompts with diverse visual attributes for each category, including color, shape/size, and texture/material. Additionally, for enhanced visual feature extraction, the SAM model is adopted as a supplement to the CLIP visual encoder through a proposed learnable weighted fusion strategy. Built upon these techniques, our method, termed LMSeg, achieves state-of-the-art performance across all major open-vocabulary segmentation benchmarks. The code will be made available soon.
Merino: Entropy-driven Design for Generative Language Models on IoT Devices
Feb 28, 2024Generative Large Language Models (LLMs) stand as a revolutionary advancement in the modern era of artificial intelligence (AI). However, directly deploying LLMs in resource-constrained hardware, such as Internet-of-Things (IoT) devices, is difficult due to their high computational cost. In this paper, we propose a novel information-entropy framework for designing mobile-friendly generative language models. Our key design paradigm is to maximize the entropy of transformer decoders within the given computational budgets. The whole design procedure involves solving a mathematical programming (MP) problem, which can be done on the CPU within minutes, making it nearly zero-cost. We evaluate our designed models, termed MeRino, across nine NLP downstream tasks, showing their competitive performance against the state-of-the-art autoregressive transformer models under the mobile setting. Notably, MeRino achieves similar or better zero performance compared to the 350M parameter OPT while being 4.9x faster on NVIDIA Jetson Nano with 5.5x reduction in model size. Code will be made available soon.
Lightweight Vision Transformer with Cross Feature Attention
Jul 15, 2022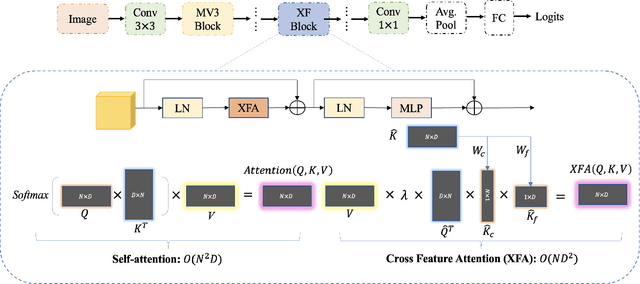
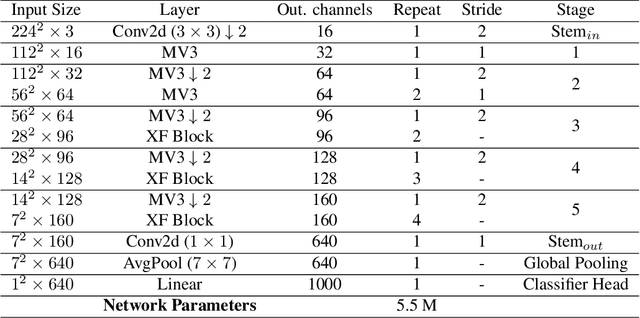


Recent advances in vision transformers (ViTs) have achieved great performance in visual recognition tasks. Convolutional neural networks (CNNs) exploit spatial inductive bias to learn visual representations, but these networks are spatially local. ViTs can learn global representations with their self-attention mechanism, but they are usually heavy-weight and unsuitable for mobile devices. In this paper, we propose cross feature attention (XFA) to bring down computation cost for transformers, and combine efficient mobile CNNs to form a novel efficient light-weight CNN-ViT hybrid model, XFormer, which can serve as a general-purpose backbone to learn both global and local representation. Experimental results show that XFormer outperforms numerous CNN and ViT-based models across different tasks and datasets. On ImageNet1K dataset, XFormer achieves top-1 accuracy of 78.5% with 5.5 million parameters, which is 2.2% and 6.3% more accurate than EfficientNet-B0 (CNN-based) and DeiT (ViT-based) for similar number of parameters. Our model also performs well when transferring to object detection and semantic segmentation tasks. On MS COCO dataset, XFormer exceeds MobileNetV2 by 10.5 AP (22.7 -> 33.2 AP) in YOLOv3 framework with only 6.3M parameters and 3.8G FLOPs. On Cityscapes dataset, with only a simple all-MLP decoder, XFormer achieves mIoU of 78.5 and FPS of 15.3, surpassing state-of-the-art lightweight segmentation networks.