 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBCTR: Bidirectional Conditioning Transformer for Scene Graph Generation
Jul 26, 2024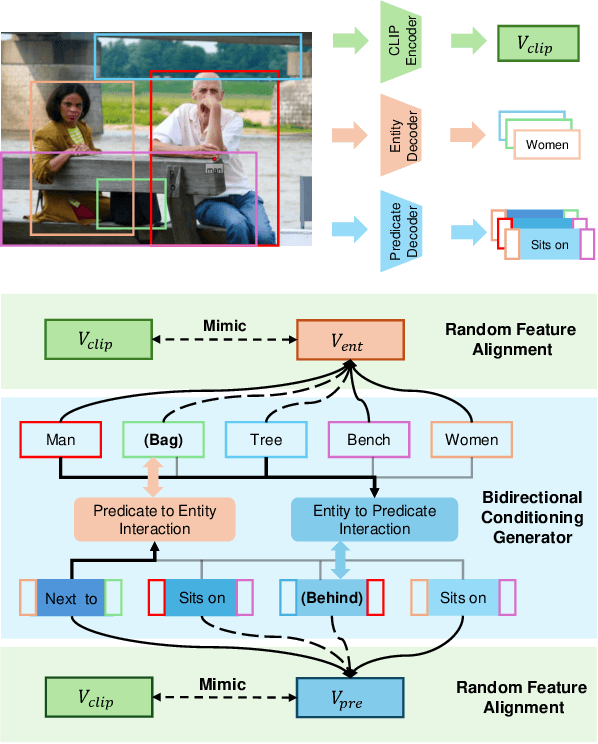
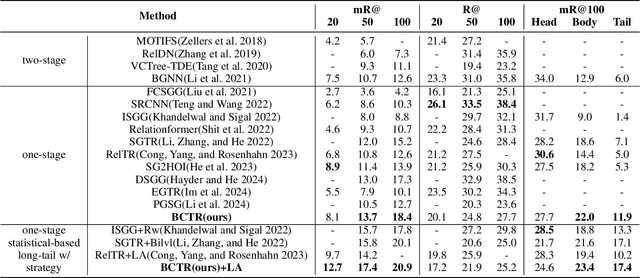
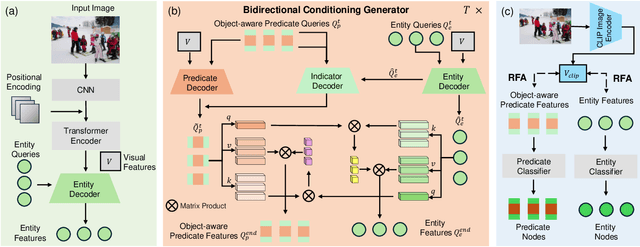
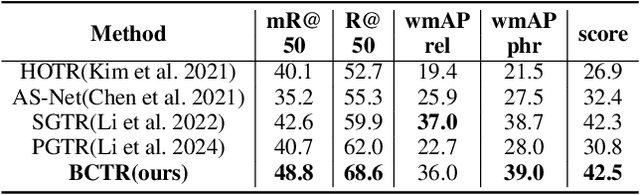
Scene Graph Generation (SGG) remains a challenging task due to its compositional property. Previous approaches improve prediction efficiency by learning in an end-to-end manner. However, these methods exhibit limited performance as they assume unidirectional conditioning between entities and predicates, leading to insufficient information interaction. To address this limitation, we propose a novel bidirectional conditioning factorization for SGG, introducing efficient interaction between entities and predicates. Specifically, we develop an end-to-end scene graph generation model, Bidirectional Conditioning Transformer (BCTR), to implement our factorization. BCTR consists of two key modules. First, the Bidirectional Conditioning Generator (BCG) facilitates multi-stage interactive feature augmentation between entities and predicates, enabling mutual benefits between the two predictions. Second, Random Feature Alignment (RFA) regularizes the feature space by distilling multi-modal knowledge from pre-trained models, enhancing BCTR's ability on tailed categories without relying on statistical priors. We conduct a series of experiments on Visual Genome and Open Image V6, demonstrating that BCTR achieves state-of-the-art performance on both benchmarks. The code will be available upon acceptance of the paper.
HyCIR: Boosting Zero-Shot Composed Image Retrieval with Synthetic Labels
Jul 09, 2024


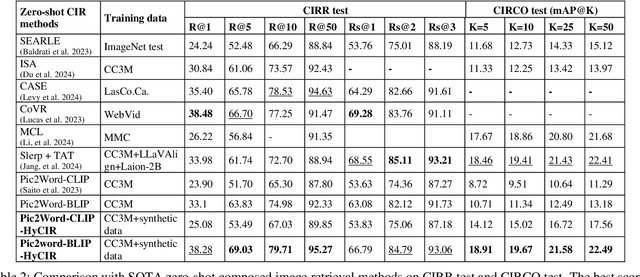
Composed Image Retrieval (CIR) aims to retrieve images based on a query image with text. Current Zero-Shot CIR (ZS-CIR) methods try to solve CIR tasks without using expensive triplet-labeled training datasets. However, the gap between ZS-CIR and triplet-supervised CIR is still large. In this work, we propose Hybrid CIR (HyCIR), which uses synthetic labels to boost the performance of ZS-CIR. A new label Synthesis pipeline for CIR (SynCir) is proposed, in which only unlabeled images are required. First, image pairs are extracted based on visual similarity. Second, query text is generated for each image pair based on vision-language model and LLM. Third, the data is further filtered in language space based on semantic similarity. To improve ZS-CIR performance, we propose a hybrid training strategy to work with both ZS-CIR supervision and synthetic CIR triplets. Two kinds of contrastive learning are adopted. One is to use large-scale unlabeled image dataset to learn an image-to-text mapping with good generalization. The other is to use synthetic CIR triplets to learn a better mapping for CIR tasks. Our approach achieves SOTA zero-shot performance on the common CIR benchmarks: CIRR and CIRCO.
Reversed Image Signal Processing and RAW Reconstruction. AIM 2022 Challenge Report
Oct 20, 2022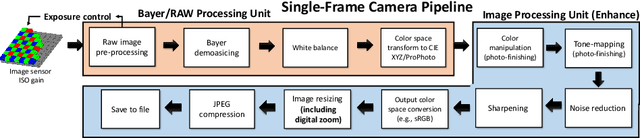
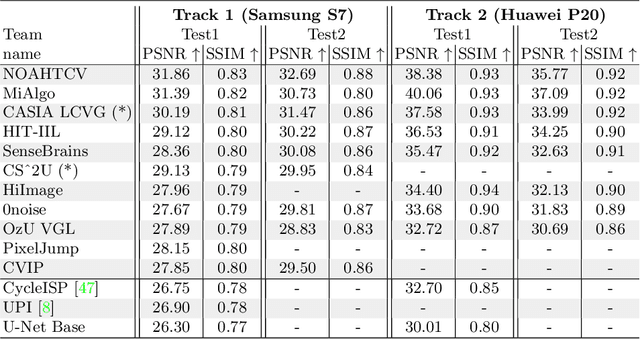
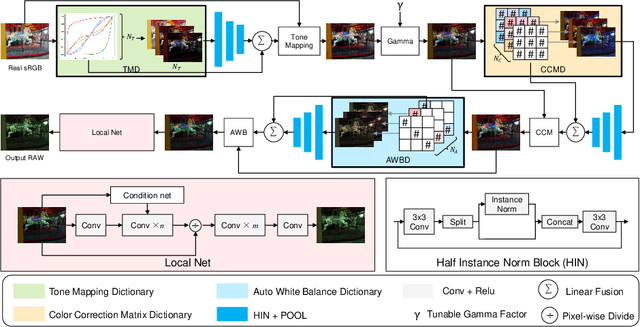
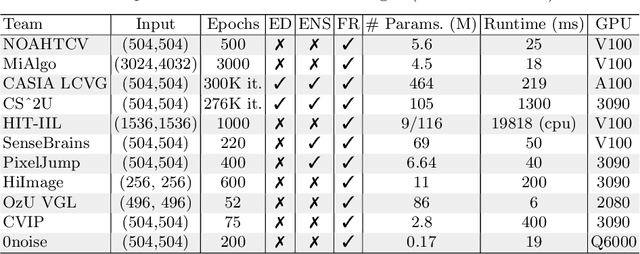
Cameras capture sensor RAW images and transform them into pleasant RGB images, suitable for the human eyes, using their integrated Image Signal Processor (ISP). Numerous low-level vision tasks operate in the RAW domain (e.g. image denoising, white balance) due to its linear relationship with the scene irradiance, wide-range of information at 12bits, and sensor designs. Despite this, RAW image datasets are scarce and more expensive to collect than the already large and public RGB datasets. This paper introduces the AIM 2022 Challenge on Reversed Image Signal Processing and RAW Reconstruction. We aim to recover raw sensor images from the corresponding RGBs without metadata and, by doing this, "reverse" the ISP transformation. The proposed methods and benchmark establish the state-of-the-art for this low-level vision inverse problem, and generating realistic raw sensor readings can potentially benefit other tasks such as denoising and super-resolution.
Lightweight Vision Transformer with Cross Feature Attention
Jul 15, 2022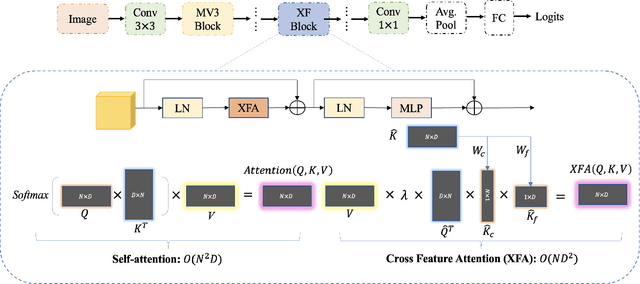
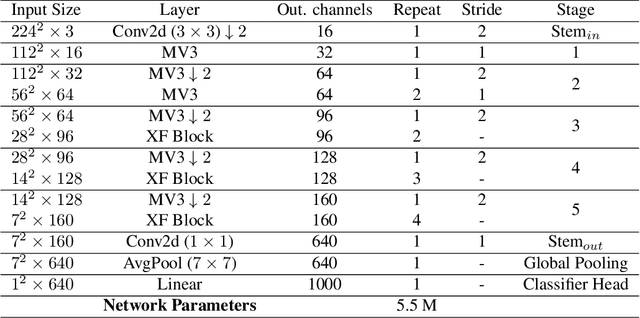


Recent advances in vision transformers (ViTs) have achieved great performance in visual recognition tasks. Convolutional neural networks (CNNs) exploit spatial inductive bias to learn visual representations, but these networks are spatially local. ViTs can learn global representations with their self-attention mechanism, but they are usually heavy-weight and unsuitable for mobile devices. In this paper, we propose cross feature attention (XFA) to bring down computation cost for transformers, and combine efficient mobile CNNs to form a novel efficient light-weight CNN-ViT hybrid model, XFormer, which can serve as a general-purpose backbone to learn both global and local representation. Experimental results show that XFormer outperforms numerous CNN and ViT-based models across different tasks and datasets. On ImageNet1K dataset, XFormer achieves top-1 accuracy of 78.5% with 5.5 million parameters, which is 2.2% and 6.3% more accurate than EfficientNet-B0 (CNN-based) and DeiT (ViT-based) for similar number of parameters. Our model also performs well when transferring to object detection and semantic segmentation tasks. On MS COCO dataset, XFormer exceeds MobileNetV2 by 10.5 AP (22.7 -> 33.2 AP) in YOLOv3 framework with only 6.3M parameters and 3.8G FLOPs. On Cityscapes dataset, with only a simple all-MLP decoder, XFormer achieves mIoU of 78.5 and FPS of 15.3, surpassing state-of-the-art lightweight segmentation networks.
WPNAS: Neural Architecture Search by jointly using Weight Sharing and Predictor
Mar 04, 2022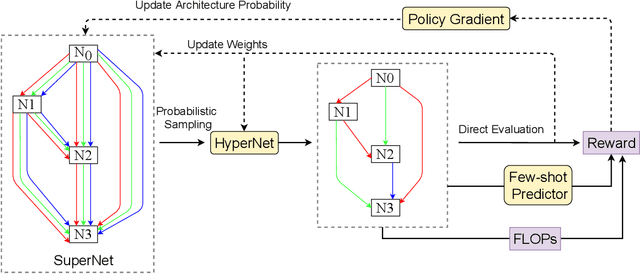
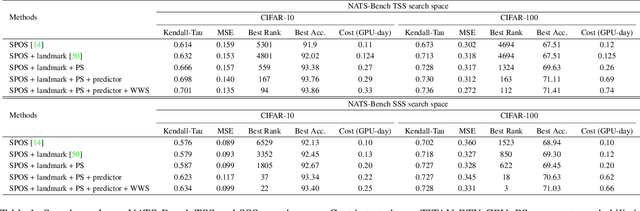

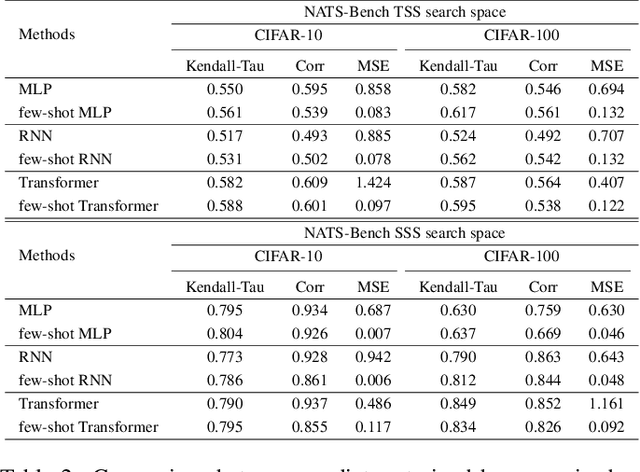
Weight sharing based and predictor based methods are two major types of fast neural architecture search methods. In this paper, we propose to jointly use weight sharing and predictor in a unified framework. First, we construct a SuperNet in a weight-sharing way and probabilisticly sample architectures from the SuperNet. To increase the correctness of the evaluation of architectures, besides direct evaluation using the inherited weights, we further apply a few-shot predictor to assess the architecture on the other hand. The final evaluation of the architecture is the combination of direct evaluation, the prediction from the predictor and the cost of the architecture. We regard the evaluation as a reward and apply a self-critical policy gradient approach to update the architecture probabilities. To further reduce the side effects of weight sharing, we propose a weakly weight sharing method by introducing another HyperNet. We conduct experiments on datasets including CIFAR-10, CIFAR-100 and ImageNet under NATS-Bench, DARTS and MobileNet search space. The proposed WPNAS method achieves state-of-the-art performance on these datasets.
Arbitrary Shape Scene Text Detection with Adaptive Text Region Representation
May 15, 2019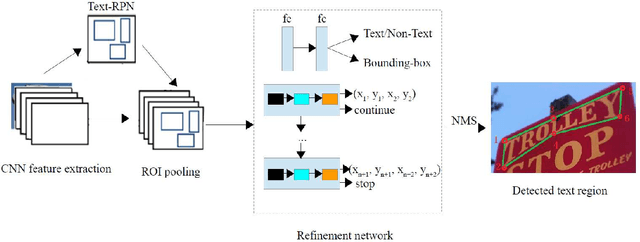

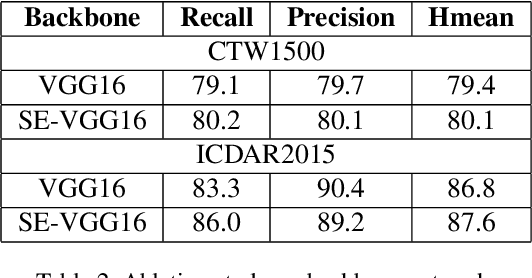
Scene text detection attracts much attention in computer vision, because it can be widely used in many applications such as real-time text translation, automatic information entry, blind person assistance, robot sensing and so on. Though many methods have been proposed for horizontal and oriented texts, detecting irregular shape texts such as curved texts is still a challenging problem. To solve the problem, we propose a robust scene text detection method with adaptive text region representation. Given an input image, a text region proposal network is first used for extracting text proposals. Then, these proposals are verified and refined with a refinement network. Here, recurrent neural network based adaptive text region representation is proposed for text region refinement, where a pair of boundary points are predicted each time step until no new points are found. In this way, text regions of arbitrary shapes are detected and represented with adaptive number of boundary points. This gives more accurate description of text regions. Experimental results on five benchmarks, namely, CTW1500, TotalText, ICDAR2013, ICDAR2015 and MSRATD500, show that the proposed method achieves state-of-the-art in scene text detection.
Deep Residual Text Detection Network for Scene Text
Nov 11, 2017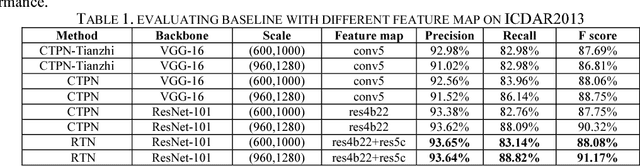

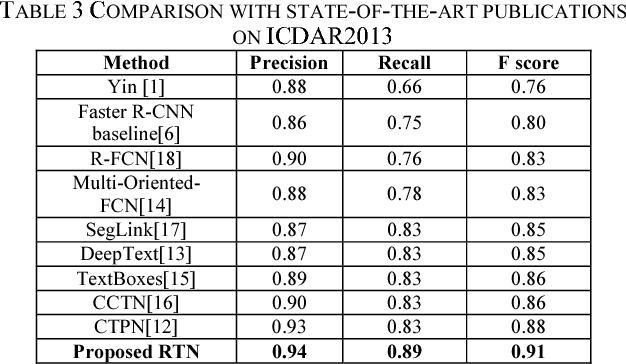
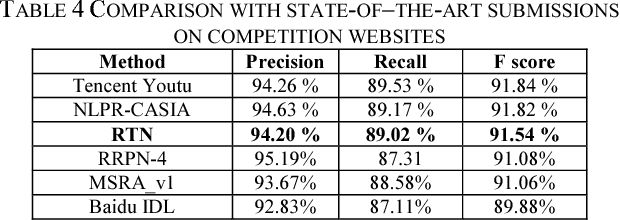
Scene text detection is a challenging problem in computer vision. In this paper, we propose a novel text detection network based on prevalent object detection frameworks. In order to obtain stronger semantic feature, we adopt ResNet as feature extraction layers and exploit multi-level feature by combining hierarchical convolutional networks. A vertical proposal mechanism is utilized to avoid proposal classification, while regression layer remains working to improve localization accuracy. Our approach evaluated on ICDAR2013 dataset achieves F-measure of 0.91, which outperforms previous state-of-the-art results in scene text detection.
R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection
Jun 30, 2017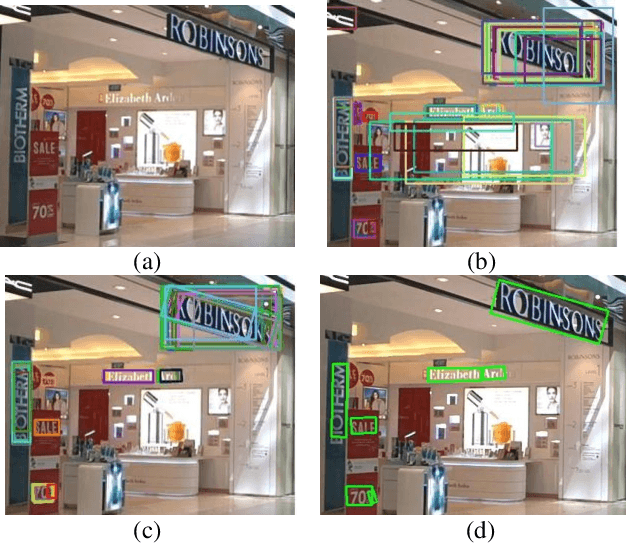
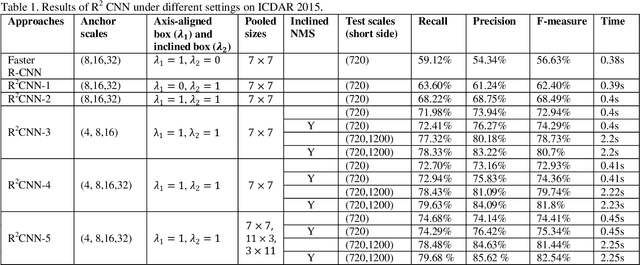

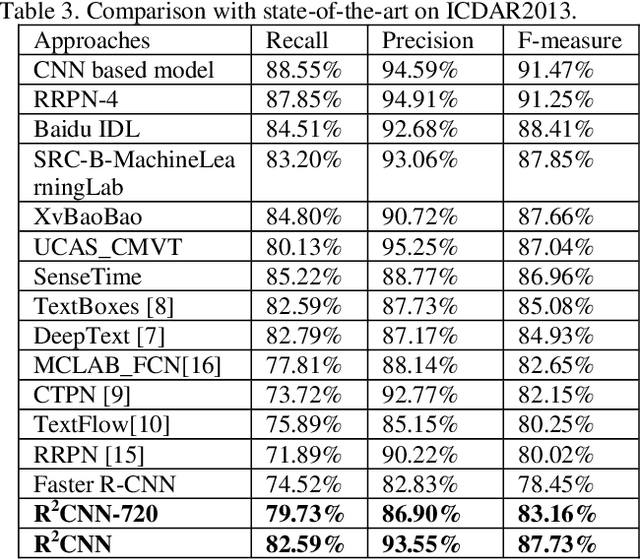
In this paper, we propose a novel method called Rotational Region CNN (R2CNN) for detecting arbitrary-oriented texts in natural scene images. The framework is based on Faster R-CNN [1] architecture. First, we use the Region Proposal Network (RPN) to generate axis-aligned bounding boxes that enclose the texts with different orientations. Second, for each axis-aligned text box proposed by RPN, we extract its pooled features with different pooled sizes and the concatenated features are used to simultaneously predict the text/non-text score, axis-aligned box and inclined minimum area box. At last, we use an inclined non-maximum suppression to get the detection results. Our approach achieves competitive results on text detection benchmarks: ICDAR 2015 and ICDAR 2013.