 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIDE: Efficient and Lossless MoE Diffusion LLM Inference with I/O-aware Expert Offload
May 19, 2026Diffusion Large Language Models (dLLMs) have emerged as a competitive alternative to autoregressive (AR) models, offering better hardware utilization and bidirectional context through parallel block-level decoding. However, as dLLMs continue to scale up with mixture-of-experts (MoE) architectures, their deployment on resource-constrained devices remains an open challenge. Existing AR-based methods often incur either prohibitive I/O overhead or significant compute bottlenecks. In this work, we propose TIDE, a novel resource-efficient inference system that leverages the temporal stability of expert activations during the diffusion process within the block. Specifically, we leverage the temporal stability of expert activations during the diffusion process within the block and introduce an interval-based expert refresh strategy that updates the expert placement in an I/O-aware fashion. To ensure optimal performance, we formulate the inference scheduling as a mathematical programming problem, solving for the optimal interval that minimizes I/O traffic and CPU computation. Most importantly, TIDE is a lossless optimization that requires no model training, providing a "free lunch" acceleration for dLLM inference. In a single GPU-CPU system, we demonstrate that TIDE achieves up to 1.4$\times$ and 1.5$\times$ throughput improvements over prior baselines on LLaDA2.0-mini and LLaDA2.0-flash models, respectively.
A.I.R.: Enabling Adaptive, Iterative, and Reasoning-based Frame Selection For Video Question Answering
Oct 06, 2025Effectively applying Vision-Language Models (VLMs) to Video Question Answering (VideoQA) hinges on selecting a concise yet comprehensive set of frames, as processing entire videos is computationally infeasible. However, current frame selection methods face a critical trade-off: approaches relying on lightweight similarity models, such as CLIP, often fail to capture the nuances of complex queries, resulting in inaccurate similarity scores that cannot reflect the authentic query-frame relevance, which further undermines frame selection. Meanwhile, methods that leverage a VLM for deeper analysis achieve higher accuracy but incur prohibitive computational costs. To address these limitations, we propose A.I.R., a training-free approach for Adaptive, Iterative, and Reasoning-based frame selection. We leverage a powerful VLM to perform deep, semantic analysis on complex queries, and this analysis is deployed within a cost-effective iterative loop that processes only a small batch of the most high-potential frames at a time. Extensive experiments on various VideoQA benchmarks demonstrate that our approach outperforms existing frame selection methods, significantly boosts the performance of the foundation VLM, and achieves substantial gains in computational efficiency over other VLM-based techniques.
AIRES: Accelerating Out-of-Core GCNs via Algorithm-System Co-Design
Jul 02, 2025


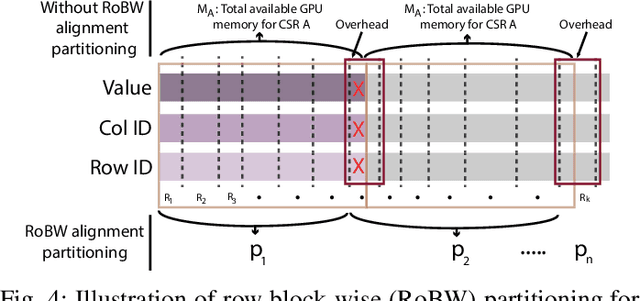
Graph convolutional networks (GCNs) are fundamental in various scientific applications, ranging from biomedical protein-protein interactions (PPI) to large-scale recommendation systems. An essential component for modeling graph structures in GCNs is sparse general matrix-matrix multiplication (SpGEMM). As the size of graph data continues to scale up, SpGEMMs are often conducted in an out-of-core fashion due to limited GPU memory space in resource-constrained systems. Albeit recent efforts that aim to alleviate the memory constraints of out-of-core SpGEMM through either GPU feature caching, hybrid CPU-GPU memory layout, or performing the computation in sparse format, current systems suffer from both high I/O latency and GPU under-utilization issues. In this paper, we first identify the problems of existing systems, where sparse format data alignment and memory allocation are the main performance bottlenecks, and propose AIRES, a novel algorithm-system co-design solution to accelerate out-of-core SpGEMM computation for GCNs. Specifically, from the algorithm angle, AIRES proposes to alleviate the data alignment issues on the block level for matrices in sparse formats and develops a tiling algorithm to facilitate row block-wise alignment. On the system level, AIRES employs a three-phase dynamic scheduling that features a dual-way data transfer strategy utilizing a tiered memory system: integrating GPU memory, GPU Direct Storage (GDS), and host memory to reduce I/O latency and improve throughput. Evaluations show that AIRES significantly outperforms the state-of-the-art methods, achieving up to 1.8x lower latency in real-world graph processing benchmarks.
Understanding and Tackling Label Errors in Individual-Level Nature Language Understanding
Feb 18, 2025Natural language understanding (NLU) is a task that enables machines to understand human language. Some tasks, such as stance detection and sentiment analysis, are closely related to individual subjective perspectives, thus termed individual-level NLU. Previously, these tasks are often simplified to text-level NLU tasks, ignoring individual factors. This not only makes inference difficult and unexplainable but often results in a large number of label errors when creating datasets. To address the above limitations, we propose a new NLU annotation guideline based on individual-level factors. Specifically, we incorporate other posts by the same individual and then annotate individual subjective perspectives after considering all individual posts. We use this guideline to expand and re-annotate the stance detection and topic-based sentiment analysis datasets. We find that error rates in the samples were as high as 31.7\% and 23.3\%. We further use large language models to conduct experiments on the re-annotation datasets and find that the large language models perform well on both datasets after adding individual factors. Both GPT-4o and Llama3-70B can achieve an accuracy greater than 87\% on the re-annotation datasets. We also verify the effectiveness of individual factors through ablation studies. We call on future researchers to add individual factors when creating such datasets. Our re-annotation dataset can be found at https://github.com/24yearsoldstudent/Individual-NLU
RL-LLM-DT: An Automatic Decision Tree Generation Method Based on RL Evaluation and LLM Enhancement
Dec 17, 2024



Traditionally, AI development for two-player zero-sum games has relied on two primary techniques: decision trees and reinforcement learning (RL). A common approach involves using a fixed decision tree as one player's strategy while training an RL agent as the opponent to identify vulnerabilities in the decision tree, thereby improving its strategic strength iteratively. However, this process often requires significant human intervention to refine the decision tree after identifying its weaknesses, resulting in inefficiencies and hindering full automation of the strategy enhancement process. Fortunately, the advent of Large Language Models (LLMs) offers a transformative opportunity to automate the process. We propose RL-LLM-DT, an automatic decision tree generation method based on RL Evaluation and LLM Enhancement. Given an initial decision tree, the method involves two important iterative steps. Response Policy Search: RL is used to discover counter-strategies targeting the decision tree. Policy Improvement: LLMs analyze failure scenarios and generate improved decision tree code. In our method, RL focuses on finding the decision tree's flaws while LLM is prompted to generate an improved version of the decision tree. The iterative refinement process terminates when RL can't find any flaw of the tree or LLM fails to improve the tree. To evaluate the effectiveness of this integrated approach, we conducted experiments in a curling game. After iterative refinements, our curling AI based on the decision tree ranks first on the Jidi platform among 34 curling AIs in total, which demonstrates that LLMs can significantly enhance the robustness and adaptability of decision trees, representing a substantial advancement in the field of Game AI. Our code is available at https://github.com/Linjunjie99/RL-LLM-DT.
LMSeg: Unleashing the Power of Large-Scale Models for Open-Vocabulary Semantic Segmentation
Nov 30, 2024


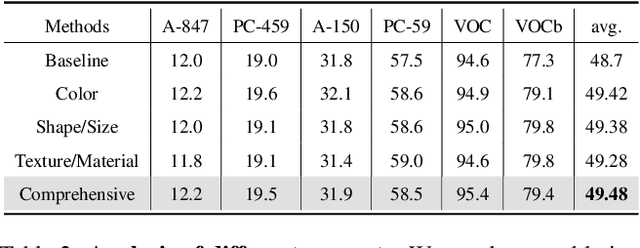
It is widely agreed that open-vocabulary-based approaches outperform classical closed-set training solutions for recognizing unseen objects in images for semantic segmentation. Existing open-vocabulary approaches leverage vision-language models, such as CLIP, to align visual features with rich semantic features acquired through pre-training on large-scale vision-language datasets. However, the text prompts employed in these methods are short phrases based on fixed templates, failing to capture comprehensive object attributes. Moreover, while the CLIP model excels at exploiting image-level features, it is less effective at pixel-level representation, which is crucial for semantic segmentation tasks. In this work, we propose to alleviate the above-mentioned issues by leveraging multiple large-scale models to enhance the alignment between fine-grained visual features and enriched linguistic features. Specifically, our method employs large language models (LLMs) to generate enriched language prompts with diverse visual attributes for each category, including color, shape/size, and texture/material. Additionally, for enhanced visual feature extraction, the SAM model is adopted as a supplement to the CLIP visual encoder through a proposed learnable weighted fusion strategy. Built upon these techniques, our method, termed LMSeg, achieves state-of-the-art performance across all major open-vocabulary segmentation benchmarks. The code will be made available soon.
ALISE: Accelerating Large Language Model Serving with Speculative Scheduling
Oct 31, 2024Large Language Models (LLMs) represent a revolutionary advancement in the contemporary landscape of artificial general intelligence (AGI). As exemplified by ChatGPT, LLM-based applications necessitate minimal response latency and maximal throughput for inference serving. However, due to the unpredictability of LLM execution, the first-come-first-serve (FCFS) scheduling policy employed by current LLM serving systems suffers from head-of-line (HoL) blocking issues and long job response times. In this paper, we propose a new efficient LLM inference serving framework, named ALISE. The key design paradigm of ALISE is to leverage a novel speculative scheduler by estimating the execution time for each job and exploiting such prior knowledge to assign appropriate job priority orders, thus minimizing potential queuing delays for heterogeneous workloads. Furthermore, to mitigate the memory overhead of the intermediate key-value (KV) cache, we employ a priority-based adaptive memory management protocol and quantization-based compression techniques. Evaluations demonstrate that in comparison to the state-of-the-art solution vLLM, ALISE improves the throughput of inference serving by up to 1.8x and 2.1x under the same latency constraint on the Alpaca and ShareGPT datasets, respectively.
CuDA2: An approach for Incorporating Traitor Agents into Cooperative Multi-Agent Systems
Jun 25, 2024



Cooperative Multi-Agent Reinforcement Learning (CMARL) strategies are well known to be vulnerable to adversarial perturbations. Previous works on adversarial attacks have primarily focused on white-box attacks that directly perturb the states or actions of victim agents, often in scenarios with a limited number of attacks. However, gaining complete access to victim agents in real-world environments is exceedingly difficult. To create more realistic adversarial attacks, we introduce a novel method that involves injecting traitor agents into the CMARL system. We model this problem as a Traitor Markov Decision Process (TMDP), where traitors cannot directly attack the victim agents but can influence their formation or positioning through collisions. In TMDP, traitors are trained using the same MARL algorithm as the victim agents, with their reward function set as the negative of the victim agents' reward. Despite this, the training efficiency for traitors remains low because it is challenging for them to directly associate their actions with the victim agents' rewards. To address this issue, we propose the Curiosity-Driven Adversarial Attack (CuDA2) framework. CuDA2 enhances the efficiency and aggressiveness of attacks on the specified victim agents' policies while maintaining the optimal policy invariance of the traitors. Specifically, we employ a pre-trained Random Network Distillation (RND) module, where the extra reward generated by the RND module encourages traitors to explore states unencountered by the victim agents. Extensive experiments on various scenarios from SMAC demonstrate that our CuDA2 framework offers comparable or superior adversarial attack capabilities compared to other baselines.
Mini Honor of Kings: A Lightweight Environment for Multi-Agent Reinforcement Learning
Jun 06, 2024Games are widely used as research environments for multi-agent reinforcement learning (MARL), but they pose three significant challenges: limited customization, high computational demands, and oversimplification. To address these issues, we introduce the first publicly available map editor for the popular mobile game Honor of Kings and design a lightweight environment, Mini Honor of Kings (Mini HoK), for researchers to conduct experiments. Mini HoK is highly efficient, allowing experiments to be run on personal PCs or laptops while still presenting sufficient challenges for existing MARL algorithms. We have tested our environment on common MARL algorithms and demonstrated that these algorithms have yet to find optimal solutions within this environment. This facilitates the dissemination and advancement of MARL methods within the research community. Additionally, we hope that more researchers will leverage the Honor of Kings map editor to develop innovative and scientifically valuable new maps. Our code and user manual are available at: https://github.com/tencent-ailab/mini-hok.
ALISA: Accelerating Large Language Model Inference via Sparsity-Aware KV Caching
Mar 26, 2024The Transformer architecture has significantly advanced natural language processing (NLP) and has been foundational in developing large language models (LLMs) such as LLaMA and OPT, which have come to dominate a broad range of NLP tasks. Despite their superior accuracy, LLMs present unique challenges in practical inference, concerning the compute and memory-intensive nature. Thanks to the autoregressive characteristic of LLM inference, KV caching for the attention layers in Transformers can effectively accelerate LLM inference by substituting quadratic-complexity computation with linear-complexity memory accesses. Yet, this approach requires increasing memory as demand grows for processing longer sequences. The overhead leads to reduced throughput due to I/O bottlenecks and even out-of-memory errors, particularly on resource-constrained systems like a single commodity GPU. In this paper, we propose ALISA, a novel algorithm-system co-design solution to address the challenges imposed by KV caching. On the algorithm level, ALISA prioritizes tokens that are most important in generating a new token via a Sparse Window Attention (SWA) algorithm. SWA introduces high sparsity in attention layers and reduces the memory footprint of KV caching at negligible accuracy loss. On the system level, ALISA employs three-phase token-level dynamical scheduling and optimizes the trade-off between caching and recomputation, thus maximizing the overall performance in resource-constrained systems. In a single GPU-CPU system, we demonstrate that under varying workloads, ALISA improves the throughput of baseline systems such as FlexGen and vLLM by up to 3X and 1.9X, respectively.