 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePareto-guided Pipeline for Distilling Featherweight AI Agents in Mobile MOBA Games
Feb 07, 2026Recent advances in game AI have demonstrated the feasibility of training agents that surpass top-tier human professionals in complex environments such as Honor of Kings (HoK), a leading mobile multiplayer online battle arena (MOBA) game. However, deploying such powerful agents on mobile devices remains a major challenge. On one hand, the intricate multi-modal state representation and hierarchical action space of HoK demand large, sophisticated policy networks that are inherently difficult to compress into lightweight forms. On the other hand, production deployment requires high-frequency inference under strict energy and latency constraints on mobile platform. To the best of our knowledge, bridging large-scale game AI and practical on-device deployment has not been systematically studied. In this work, we propose a Pareto optimality guided pipeline and design a high-efficiency student architecture search space tailored for mobile execution, enabling systematic exploration of the trade-off between performance and efficiency. Experimental results demonstrate that the distilled model achieves remarkable efficiency, including an $12.4\times$ faster inference speed (under 0.5ms per frame) and a $15.6\times$ improvement in energy efficiency (under 0.5mAh per game), while retaining a 40.32% win rate against the original teacher model.
RL-LLM-DT: An Automatic Decision Tree Generation Method Based on RL Evaluation and LLM Enhancement
Dec 17, 2024



Traditionally, AI development for two-player zero-sum games has relied on two primary techniques: decision trees and reinforcement learning (RL). A common approach involves using a fixed decision tree as one player's strategy while training an RL agent as the opponent to identify vulnerabilities in the decision tree, thereby improving its strategic strength iteratively. However, this process often requires significant human intervention to refine the decision tree after identifying its weaknesses, resulting in inefficiencies and hindering full automation of the strategy enhancement process. Fortunately, the advent of Large Language Models (LLMs) offers a transformative opportunity to automate the process. We propose RL-LLM-DT, an automatic decision tree generation method based on RL Evaluation and LLM Enhancement. Given an initial decision tree, the method involves two important iterative steps. Response Policy Search: RL is used to discover counter-strategies targeting the decision tree. Policy Improvement: LLMs analyze failure scenarios and generate improved decision tree code. In our method, RL focuses on finding the decision tree's flaws while LLM is prompted to generate an improved version of the decision tree. The iterative refinement process terminates when RL can't find any flaw of the tree or LLM fails to improve the tree. To evaluate the effectiveness of this integrated approach, we conducted experiments in a curling game. After iterative refinements, our curling AI based on the decision tree ranks first on the Jidi platform among 34 curling AIs in total, which demonstrates that LLMs can significantly enhance the robustness and adaptability of decision trees, representing a substantial advancement in the field of Game AI. Our code is available at https://github.com/Linjunjie99/RL-LLM-DT.
Hokoff: Real Game Dataset from Honor of Kings and its Offline Reinforcement Learning Benchmarks
Aug 20, 2024



The advancement of Offline Reinforcement Learning (RL) and Offline Multi-Agent Reinforcement Learning (MARL) critically depends on the availability of high-quality, pre-collected offline datasets that represent real-world complexities and practical applications. However, existing datasets often fall short in their simplicity and lack of realism. To address this gap, we propose Hokoff, a comprehensive set of pre-collected datasets that covers both offline RL and offline MARL, accompanied by a robust framework, to facilitate further research. This data is derived from Honor of Kings, a recognized Multiplayer Online Battle Arena (MOBA) game known for its intricate nature, closely resembling real-life situations. Utilizing this framework, we benchmark a variety of offline RL and offline MARL algorithms. We also introduce a novel baseline algorithm tailored for the inherent hierarchical action space of the game. We reveal the incompetency of current offline RL approaches in handling task complexity, generalization and multi-task learning.
SimsChat: A Customisable Persona-Driven Role-Playing Agent
Jun 25, 2024Large Language Models (LLMs) possess the remarkable capability to understand human instructions and generate high-quality text, enabling them to act as agents that simulate human behaviours. This capability allows LLMs to emulate human beings in a more advanced manner, beyond merely replicating simple human behaviours. However, there is a lack of exploring into leveraging LLMs to craft characters from several aspects. In this work, we introduce the Customisable Conversation Agent Framework, which employs LLMs to simulate real-world characters that can be freely customised according to different user preferences. The customisable framework is helpful for designing customisable characters and role-playing agents according to human's preferences. We first propose the SimsConv dataset, which comprises 68 different customised characters, 1,360 multi-turn role-playing dialogues, and encompasses 13,971 interaction dialogues in total. The characters are created from several real-world elements, such as career, aspiration, trait, and skill. Building on these foundations, we present SimsChat, a freely customisable role-playing agent. It incorporates different real-world scenes and topic-specific character interaction dialogues, simulating characters' life experiences in various scenarios and topic-specific interactions with specific emotions. Experimental results show that our proposed framework achieves desirable performance and provides helpful guideline for building better simulacra of human beings in the future. Our data and code are available at https://github.com/Bernard-Yang/SimsChat.
Leveraging Reinforcement Learning in Red Teaming for Advanced Ransomware Attack Simulations
Jun 25, 2024Ransomware presents a significant and increasing threat to individuals and organizations by encrypting their systems and not releasing them until a large fee has been extracted. To bolster preparedness against potential attacks, organizations commonly conduct red teaming exercises, which involve simulated attacks to assess existing security measures. This paper proposes a novel approach utilizing reinforcement learning (RL) to simulate ransomware attacks. By training an RL agent in a simulated environment mirroring real-world networks, effective attack strategies can be learned quickly, significantly streamlining traditional, manual penetration testing processes. The attack pathways revealed by the RL agent can provide valuable insights to the defense team, helping them identify network weak points and develop more resilient defensive measures. Experimental results on a 152-host example network confirm the effectiveness of the proposed approach, demonstrating the RL agent's capability to discover and orchestrate attacks on high-value targets while evading honeyfiles (decoy files strategically placed to detect unauthorized access).
Mini Honor of Kings: A Lightweight Environment for Multi-Agent Reinforcement Learning
Jun 06, 2024Games are widely used as research environments for multi-agent reinforcement learning (MARL), but they pose three significant challenges: limited customization, high computational demands, and oversimplification. To address these issues, we introduce the first publicly available map editor for the popular mobile game Honor of Kings and design a lightweight environment, Mini Honor of Kings (Mini HoK), for researchers to conduct experiments. Mini HoK is highly efficient, allowing experiments to be run on personal PCs or laptops while still presenting sufficient challenges for existing MARL algorithms. We have tested our environment on common MARL algorithms and demonstrated that these algorithms have yet to find optimal solutions within this environment. This facilitates the dissemination and advancement of MARL methods within the research community. Additionally, we hope that more researchers will leverage the Honor of Kings map editor to develop innovative and scientifically valuable new maps. Our code and user manual are available at: https://github.com/tencent-ailab/mini-hok.
Enhancing Human Experience in Human-Agent Collaboration: A Human-Centered Modeling Approach Based on Positive Human Gain
Jan 28, 2024



Existing game AI research mainly focuses on enhancing agents' abilities to win games, but this does not inherently make humans have a better experience when collaborating with these agents. For example, agents may dominate the collaboration and exhibit unintended or detrimental behaviors, leading to poor experiences for their human partners. In other words, most game AI agents are modeled in a "self-centered" manner. In this paper, we propose a "human-centered" modeling scheme for collaborative agents that aims to enhance the experience of humans. Specifically, we model the experience of humans as the goals they expect to achieve during the task. We expect that agents should learn to enhance the extent to which humans achieve these goals while maintaining agents' original abilities (e.g., winning games). To achieve this, we propose the Reinforcement Learning from Human Gain (RLHG) approach. The RLHG approach introduces a "baseline", which corresponds to the extent to which humans primitively achieve their goals, and encourages agents to learn behaviors that can effectively enhance humans in achieving their goals better. We evaluate the RLHG agent in the popular Multi-player Online Battle Arena (MOBA) game, Honor of Kings, by conducting real-world human-agent tests. Both objective performance and subjective preference results show that the RLHG agent provides participants better gaming experience.
Discovering Command and Control Channels Using Reinforcement Learning
Jan 13, 2024



Command and control (C2) paths for issuing commands to malware are sometimes the only indicators of its existence within networks. Identifying potential C2 channels is often a manually driven process that involves a deep understanding of cyber tradecraft. Efforts to improve discovery of these channels through using a reinforcement learning (RL) based approach that learns to automatically carry out C2 attack campaigns on large networks, where multiple defense layers are in place serves to drive efficiency for network operators. In this paper, we model C2 traffic flow as a three-stage process and formulate it as a Markov decision process (MDP) with the objective to maximize the number of valuable hosts whose data is exfiltrated. The approach also specifically models payload and defense mechanisms such as firewalls which is a novel contribution. The attack paths learned by the RL agent can in turn help the blue team identify high-priority vulnerabilities and develop improved defense strategies. The method is evaluated on a large network with more than a thousand hosts and the results demonstrate that the agent can effectively learn attack paths while avoiding firewalls.
Towards Effective and Interpretable Human-Agent Collaboration in MOBA Games: A Communication Perspective
Apr 23, 2023

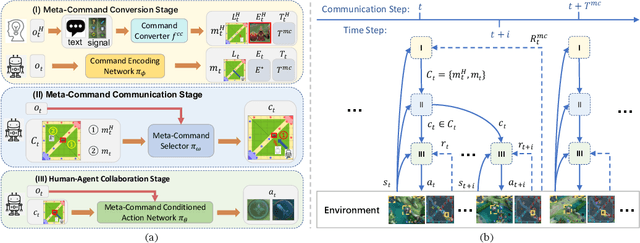

MOBA games, e.g., Dota2 and Honor of Kings, have been actively used as the testbed for the recent AI research on games, and various AI systems have been developed at the human level so far. However, these AI systems mainly focus on how to compete with humans, less on exploring how to collaborate with humans. To this end, this paper makes the first attempt to investigate human-agent collaboration in MOBA games. In this paper, we propose to enable humans and agents to collaborate through explicit communication by designing an efficient and interpretable Meta-Command Communication-based framework, dubbed MCC, for accomplishing effective human-agent collaboration in MOBA games. The MCC framework consists of two pivotal modules: 1) an interpretable communication protocol, i.e., the Meta-Command, to bridge the communication gap between humans and agents; 2) a meta-command value estimator, i.e., the Meta-Command Selector, to select a valuable meta-command for each agent to achieve effective human-agent collaboration. Experimental results in Honor of Kings demonstrate that MCC agents can collaborate reasonably well with human teammates and even generalize to collaborate with different levels and numbers of human teammates. Videos are available at https://sites.google.com/view/mcc-demo.
Exposing Surveillance Detection Routes via Reinforcement Learning, Attack Graphs, and Cyber Terrain
Nov 06, 2022Reinforcement learning (RL) operating on attack graphs leveraging cyber terrain principles are used to develop reward and state associated with determination of surveillance detection routes (SDR). This work extends previous efforts on developing RL methods for path analysis within enterprise networks. This work focuses on building SDR where the routes focus on exploring the network services while trying to evade risk. RL is utilized to support the development of these routes by building a reward mechanism that would help in realization of these paths. The RL algorithm is modified to have a novel warm-up phase which decides in the initial exploration which areas of the network are safe to explore based on the rewards and penalty scale factor.