 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Value in the Age of Scaling: Understanding LLM Scaling Dynamics Under Real-Synthetic Data Mixtures
Nov 17, 2025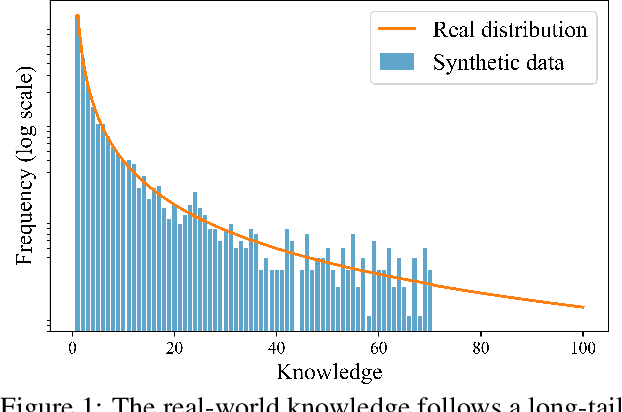
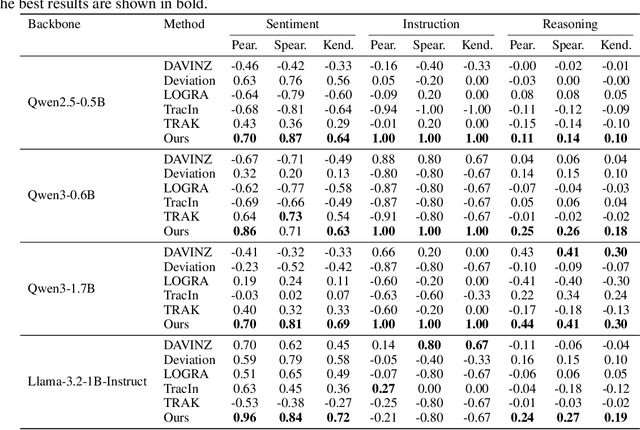
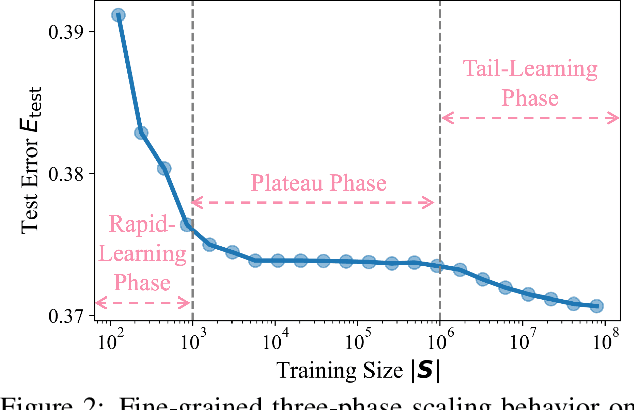
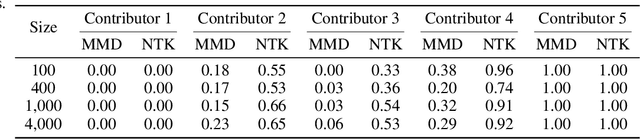
The rapid progress of large language models (LLMs) is fueled by the growing reliance on datasets that blend real and synthetic data. While synthetic data offers scalability and cost-efficiency, it often introduces systematic distributional discrepancies, particularly underrepresenting long-tail knowledge due to truncation effects from data generation mechanisms like top-p sampling, temperature scaling, and finite sampling. These discrepancies pose fundamental challenges in characterizing and evaluating the utility of mixed real-synthetic datasets. In this paper, we identify a three-phase scaling behavior characterized by two breakpoints that reflect transitions in model behavior across learning head and tail knowledge. We further derive an LLM generalization bound designed for real and synthetic mixtures, revealing several key factors that govern their generalization performance. Building on our theoretical findings, we propose an effective yet efficient data valuation method that scales to large-scale datasets. Comprehensive experiments across four tasks, including image classification, sentiment classification, instruction following, and complex reasoning, demonstrate that our method surpasses state-of-the-art baselines in data valuation with significantly low computational cost.
GENUINE: Graph Enhanced Multi-level Uncertainty Estimation for Large Language Models
Sep 09, 2025Uncertainty estimation is essential for enhancing the reliability of Large Language Models (LLMs), particularly in high-stakes applications. Existing methods often overlook semantic dependencies, relying on token-level probability measures that fail to capture structural relationships within the generated text. We propose GENUINE: Graph ENhanced mUlti-level uncertaINty Estimation for Large Language Models, a structure-aware framework that leverages dependency parse trees and hierarchical graph pooling to refine uncertainty quantification. By incorporating supervised learning, GENUINE effectively models semantic and structural relationships, improving confidence assessments. Extensive experiments across NLP tasks show that GENUINE achieves up to 29% higher AUROC than semantic entropy-based approaches and reduces calibration errors by over 15%, demonstrating the effectiveness of graph-based uncertainty modeling. The code is available at https://github.com/ODYSSEYWT/GUQ.
LENSLLM: Unveiling Fine-Tuning Dynamics for LLM Selection
May 01, 2025The proliferation of open-sourced Large Language Models (LLMs) and diverse downstream tasks necessitates efficient model selection, given the impracticality of fine-tuning all candidates due to computational constraints. Despite the recent advances in LLM selection, a fundamental research question largely remains nascent: how can we model the dynamic behaviors of LLMs during fine-tuning, thereby enhancing our understanding of their generalization performance across diverse downstream tasks? In this work, we propose a novel theoretical framework that provides a proper lens to assess the generalization capabilities of LLMs, thereby enabling accurate and efficient LLM selection for downstream applications. In particular, we first derive a Hessian-based PAC-Bayes generalization bound that unveils fine-tuning dynamics of LLMs and then introduce LENSLLM, a Neural Tangent Kernel(NTK)-based Rectified Scaling Model that enables accurate performance predictions across diverse tasks while maintaining computational efficiency. Extensive empirical results on 3 large-scale benchmarks demonstrate that our model achieves up to 91.1% accuracy and reduces up to 88.5% computational cost in LLM selection, outperforming 5 state-of-the-art methods. We open-source our proposed LENSLLM model and corresponding results at the Github link: https://github.com/Susan571/LENSLLM.git.
On Extending the Automatic Test Markup Language (ATML) for Machine Learning
Apr 04, 2024This paper addresses the urgent need for messaging standards in the operational test and evaluation (T&E) of machine learning (ML) applications, particularly in edge ML applications embedded in systems like robots, satellites, and unmanned vehicles. It examines the suitability of the IEEE Standard 1671 (IEEE Std 1671), known as the Automatic Test Markup Language (ATML), an XML-based standard originally developed for electronic systems, for ML application testing. The paper explores extending IEEE Std 1671 to encompass the unique challenges of ML applications, including the use of datasets and dependencies on software. Through modeling various tests such as adversarial robustness and drift detection, this paper offers a framework adaptable to specific applications, suggesting that minor modifications to ATML might suffice to address the novelties of ML. This paper differentiates ATML's focus on testing from other ML standards like Predictive Model Markup Language (PMML) or Open Neural Network Exchange (ONNX), which concentrate on ML model specification. We conclude that ATML is a promising tool for effective, near real-time operational T&E of ML applications, an essential aspect of AI lifecycle management, safety, and governance.
A Systems Theoretic Approach to Online Machine Learning
Apr 04, 2024The machine learning formulation of online learning is incomplete from a systems theoretic perspective. Typically, machine learning research emphasizes domains and tasks, and a problem solving worldview. It focuses on algorithm parameters, features, and samples, and neglects the perspective offered by considering system structure and system behavior or dynamics. Online learning is an active field of research and has been widely explored in terms of statistical theory and computational algorithms, however, in general, the literature still lacks formal system theoretical frameworks for modeling online learning systems and resolving systems-related concept drift issues. Furthermore, while the machine learning formulation serves to classify methods and literature, the systems theoretic formulation presented herein serves to provide a framework for the top-down design of online learning systems, including a novel definition of online learning and the identification of key design parameters. The framework is formulated in terms of input-output systems and is further divided into system structure and system behavior. Concept drift is a critical challenge faced in online learning, and this work formally approaches it as part of the system behavior characteristics. Healthcare provider fraud detection using machine learning is used as a case study throughout the paper to ground the discussion in a real-world online learning challenge.
Discovering Command and Control (C2) Channels on Tor and Public Networks Using Reinforcement Learning
Feb 14, 2024Command and control (C2) channels are an essential component of many types of cyber attacks, as they enable attackers to remotely control their malware-infected machines and execute harmful actions, such as propagating malicious code across networks, exfiltrating confidential data, or initiating distributed denial of service (DDoS) attacks. Identifying these C2 channels is therefore crucial in helping to mitigate and prevent cyber attacks. However, identifying C2 channels typically involves a manual process, requiring deep knowledge and expertise in cyber operations. In this paper, we propose a reinforcement learning (RL) based approach to automatically emulate C2 attack campaigns using both the normal (public) and the Tor networks. In addition, payload size and network firewalls are configured to simulate real-world attack scenarios. Results on a typical network configuration show that the RL agent can automatically discover resilient C2 attack paths utilizing both Tor-based and conventional communication channels, while also bypassing network firewalls.
Discovering Command and Control Channels Using Reinforcement Learning
Jan 13, 2024



Command and control (C2) paths for issuing commands to malware are sometimes the only indicators of its existence within networks. Identifying potential C2 channels is often a manually driven process that involves a deep understanding of cyber tradecraft. Efforts to improve discovery of these channels through using a reinforcement learning (RL) based approach that learns to automatically carry out C2 attack campaigns on large networks, where multiple defense layers are in place serves to drive efficiency for network operators. In this paper, we model C2 traffic flow as a three-stage process and formulate it as a Markov decision process (MDP) with the objective to maximize the number of valuable hosts whose data is exfiltrated. The approach also specifically models payload and defense mechanisms such as firewalls which is a novel contribution. The attack paths learned by the RL agent can in turn help the blue team identify high-priority vulnerabilities and develop improved defense strategies. The method is evaluated on a large network with more than a thousand hosts and the results demonstrate that the agent can effectively learn attack paths while avoiding firewalls.
Improving Intrusion Detection with Domain-Invariant Representation Learning in Latent Space
Jan 02, 2024


Domain generalization focuses on leveraging knowledge from multiple related domains with ample training data and labels to enhance inference on unseen in-distribution (IN) and out-of-distribution (OOD) domains. In our study, we introduce a two-phase representation learning technique using multi-task learning. This approach aims to cultivate a latent space from features spanning multiple domains, encompassing both native and cross-domains, to amplify generalization to IN and OOD territories. Additionally, we attempt to disentangle the latent space by minimizing the mutual information between the prior and latent space, effectively de-correlating spurious feature correlations. Collectively, the joint optimization will facilitate domain-invariant feature learning. We assess the model's efficacy across multiple cybersecurity datasets, using standard classification metrics on both unseen IN and OOD sets, and juxtapose the results with contemporary domain generalization methods.
A Systems-Theoretical Formalization of Closed Systems
Nov 16, 2023There is a lack of formalism for some key foundational concepts in systems engineering. One of the most recently acknowledged deficits is the inadequacy of systems engineering practices for engineering intelligent systems. In our previous works, we proposed that closed systems precepts could be used to accomplish a required paradigm shift for the systems engineering of intelligent systems. However, to enable such a shift, formal foundations for closed systems precepts that expand the theory of systems engineering are needed. The concept of closure is a critical concept in the formalism underlying closed systems precepts. In this paper, we provide formal, systems- and information-theoretic definitions of closure to identify and distinguish different types of closed systems. Then, we assert a mathematical framework to evaluate the subjective formation of the boundaries and constraints of such systems. Finally, we argue that engineering an intelligent system can benefit from appropriate closed and open systems paradigms on multiple levels of abstraction of the system. In the main, this framework will provide the necessary fundamentals to aid in systems engineering of intelligent systems.
Test & Evaluation Best Practices for Machine Learning-Enabled Systems
Oct 10, 2023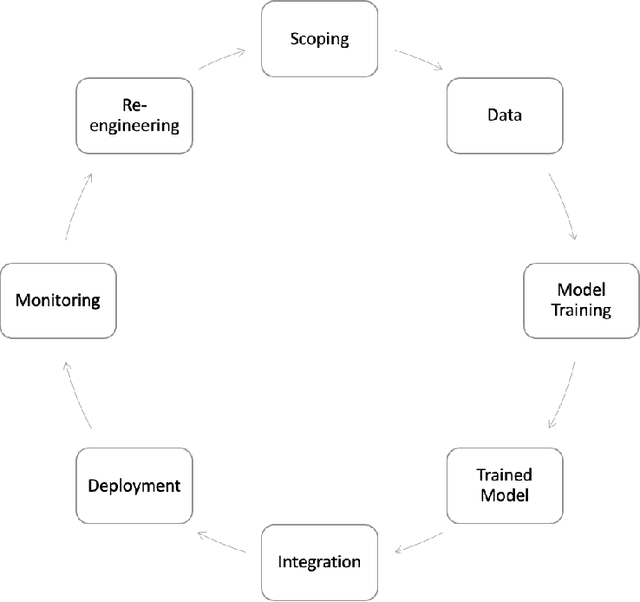
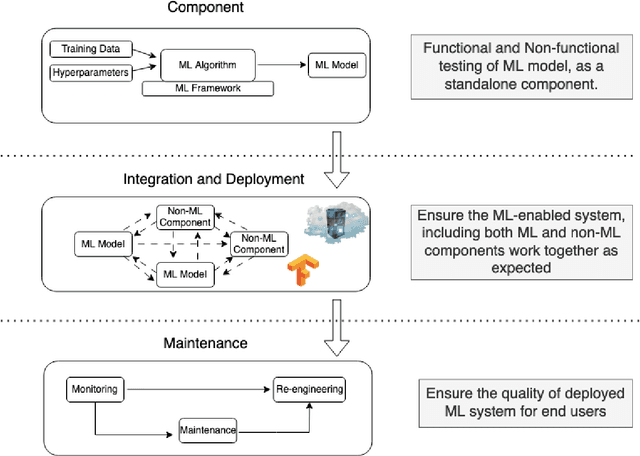
Machine learning (ML) - based software systems are rapidly gaining adoption across various domains, making it increasingly essential to ensure they perform as intended. This report presents best practices for the Test and Evaluation (T&E) of ML-enabled software systems across its lifecycle. We categorize the lifecycle of ML-enabled software systems into three stages: component, integration and deployment, and post-deployment. At the component level, the primary objective is to test and evaluate the ML model as a standalone component. Next, in the integration and deployment stage, the goal is to evaluate an integrated ML-enabled system consisting of both ML and non-ML components. Finally, once the ML-enabled software system is deployed and operationalized, the T&E objective is to ensure the system performs as intended. Maintenance activities for ML-enabled software systems span the lifecycle and involve maintaining various assets of ML-enabled software systems. Given its unique characteristics, the T&E of ML-enabled software systems is challenging. While significant research has been reported on T&E at the component level, limited work is reported on T&E in the remaining two stages. Furthermore, in many cases, there is a lack of systematic T&E strategies throughout the ML-enabled system's lifecycle. This leads practitioners to resort to ad-hoc T&E practices, which can undermine user confidence in the reliability of ML-enabled software systems. New systematic testing approaches, adequacy measurements, and metrics are required to address the T&E challenges across all stages of the ML-enabled system lifecycle.