 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Command and Control Channels Using Reinforcement Learning
Jan 13, 2024



Command and control (C2) paths for issuing commands to malware are sometimes the only indicators of its existence within networks. Identifying potential C2 channels is often a manually driven process that involves a deep understanding of cyber tradecraft. Efforts to improve discovery of these channels through using a reinforcement learning (RL) based approach that learns to automatically carry out C2 attack campaigns on large networks, where multiple defense layers are in place serves to drive efficiency for network operators. In this paper, we model C2 traffic flow as a three-stage process and formulate it as a Markov decision process (MDP) with the objective to maximize the number of valuable hosts whose data is exfiltrated. The approach also specifically models payload and defense mechanisms such as firewalls which is a novel contribution. The attack paths learned by the RL agent can in turn help the blue team identify high-priority vulnerabilities and develop improved defense strategies. The method is evaluated on a large network with more than a thousand hosts and the results demonstrate that the agent can effectively learn attack paths while avoiding firewalls.
Exposing Surveillance Detection Routes via Reinforcement Learning, Attack Graphs, and Cyber Terrain
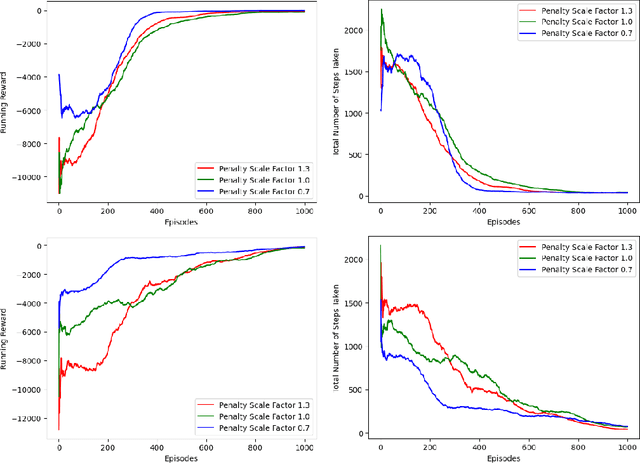
Nov 06, 2022Reinforcement learning (RL) operating on attack graphs leveraging cyber terrain principles are used to develop reward and state associated with determination of surveillance detection routes (SDR). This work extends previous efforts on developing RL methods for path analysis within enterprise networks. This work focuses on building SDR where the routes focus on exploring the network services while trying to evade risk. RL is utilized to support the development of these routes by building a reward mechanism that would help in realization of these paths. The RL algorithm is modified to have a novel warm-up phase which decides in the initial exploration which areas of the network are safe to explore based on the rewards and penalty scale factor.
Lateral Movement Detection Using User Behavioral Analysis
Aug 29, 2022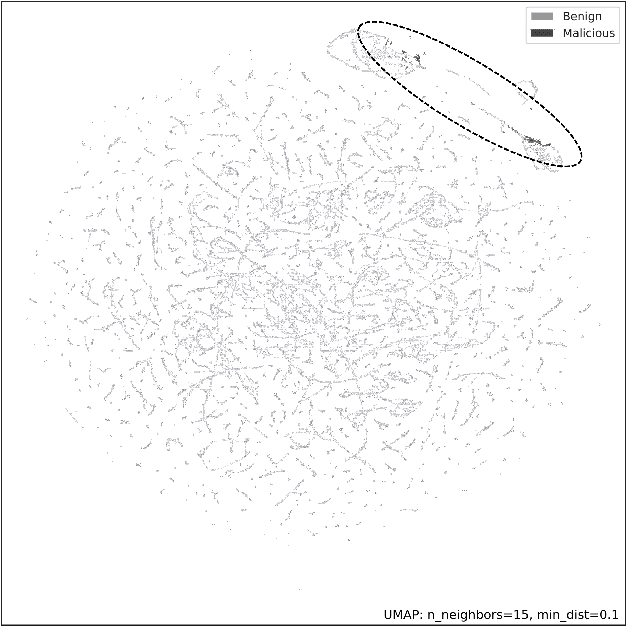
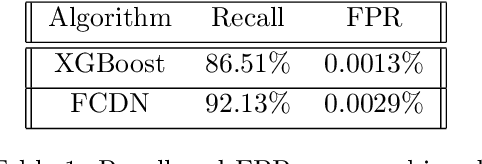
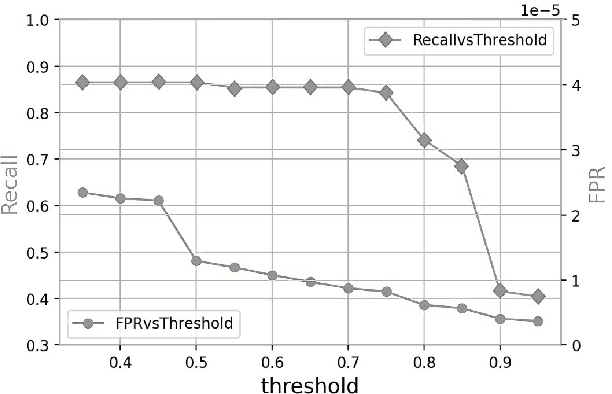
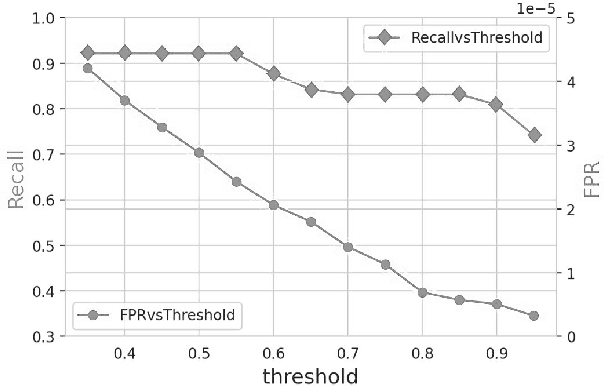
Lateral Movement refers to methods by which threat actors gain initial access to a network and then progressively move through said network collecting key data about assets until they reach the ultimate target of their attack. Lateral Movement intrusions have become more intricate with the increasing complexity and interconnected nature of enterprise networks, and require equally sophisticated detection mechanisms to proactively detect such threats in near real-time at enterprise scale. In this paper, the authors propose a novel, lightweight method for Lateral Movement detection using user behavioral analysis and machine learning. Specifically, this paper introduces a novel methodology for cyber domain-specific feature engineering that identifies Lateral Movement behavior on a per-user basis. Furthermore, the engineered features have also been used to develop two supervised machine learning models for Lateral Movement identification that have demonstrably outperformed models previously seen in literature while maintaining robust performance on datasets with high class imbalance. The models and methodology introduced in this paper have also been designed in collaboration with security operators to be relevant and interpretable in order to maximize impact and minimize time to value as a cyber threat detection toolkit. The underlying goal of the paper is to provide a computationally efficient, domain-specific approach to near real-time Lateral Movement detection that is interpretable and robust to enterprise-scale data volumes and class imbalance.
Discovering Exfiltration Paths Using Reinforcement Learning with Attack Graphs
Jan 28, 2022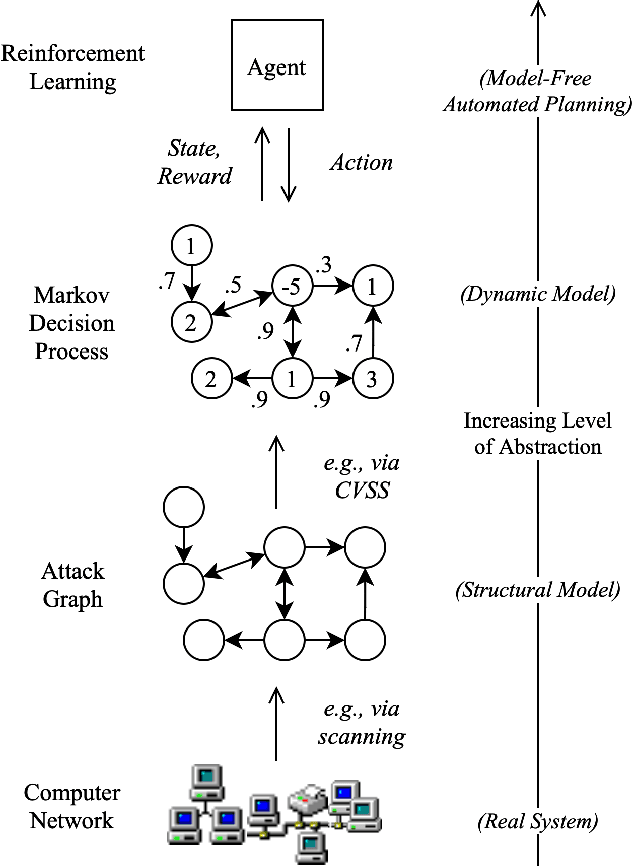
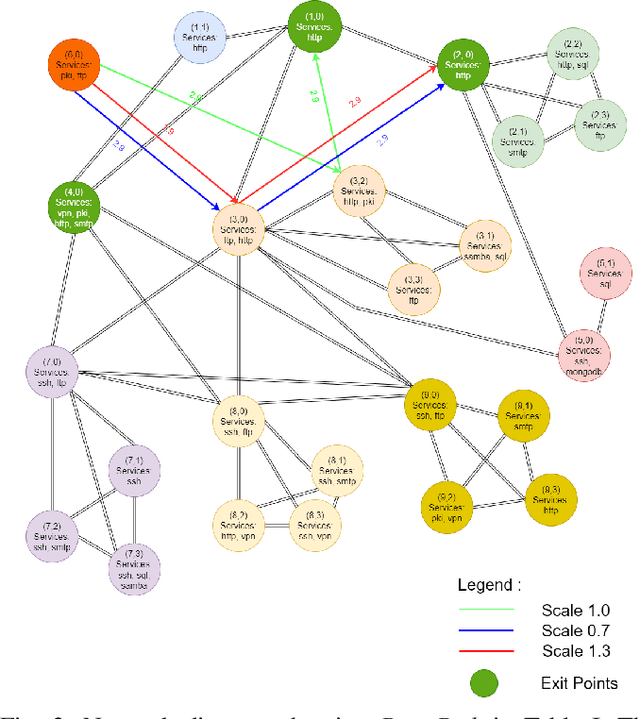
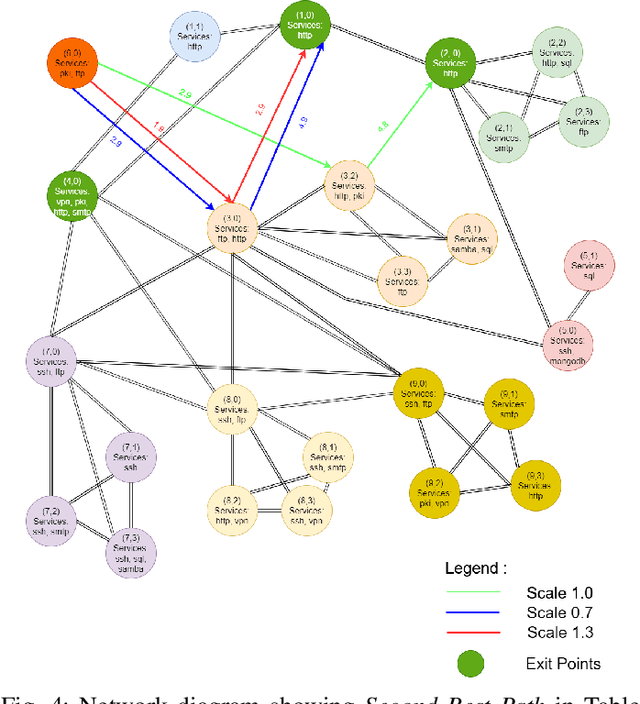
Reinforcement learning (RL), in conjunction with attack graphs and cyber terrain, are used to develop reward and state associated with determination of optimal paths for exfiltration of data in enterprise networks. This work builds on previous crown jewels (CJ) identification that focused on the target goal of computing optimal paths that adversaries may traverse toward compromising CJs or hosts within their proximity. This work inverts the previous CJ approach based on the assumption that data has been stolen and now must be quietly exfiltrated from the network. RL is utilized to support the development of a reward function based on the identification of those paths where adversaries desire reduced detection. Results demonstrate promising performance for a sizable network environment.