 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Value in the Age of Scaling: Understanding LLM Scaling Dynamics Under Real-Synthetic Data Mixtures
Nov 17, 2025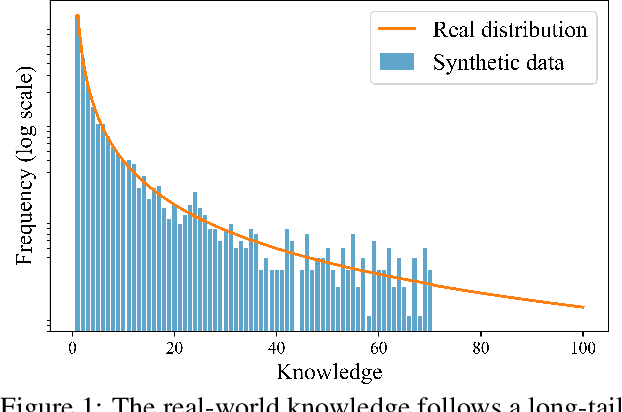
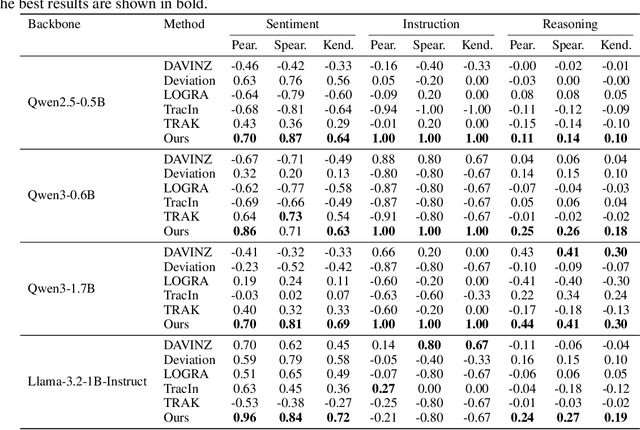
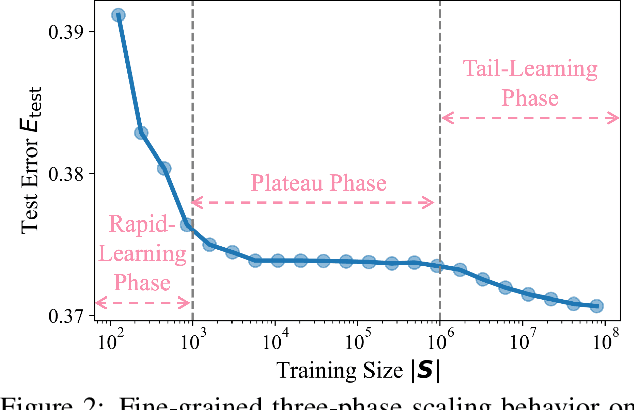
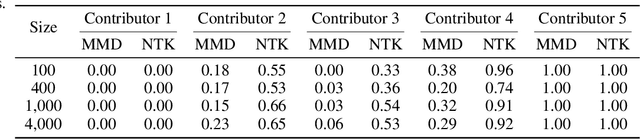
The rapid progress of large language models (LLMs) is fueled by the growing reliance on datasets that blend real and synthetic data. While synthetic data offers scalability and cost-efficiency, it often introduces systematic distributional discrepancies, particularly underrepresenting long-tail knowledge due to truncation effects from data generation mechanisms like top-p sampling, temperature scaling, and finite sampling. These discrepancies pose fundamental challenges in characterizing and evaluating the utility of mixed real-synthetic datasets. In this paper, we identify a three-phase scaling behavior characterized by two breakpoints that reflect transitions in model behavior across learning head and tail knowledge. We further derive an LLM generalization bound designed for real and synthetic mixtures, revealing several key factors that govern their generalization performance. Building on our theoretical findings, we propose an effective yet efficient data valuation method that scales to large-scale datasets. Comprehensive experiments across four tasks, including image classification, sentiment classification, instruction following, and complex reasoning, demonstrate that our method surpasses state-of-the-art baselines in data valuation with significantly low computational cost.
Evaluating Query Efficiency and Accuracy of Transfer Learning-based Model Extraction Attack in Federated Learning
May 25, 2025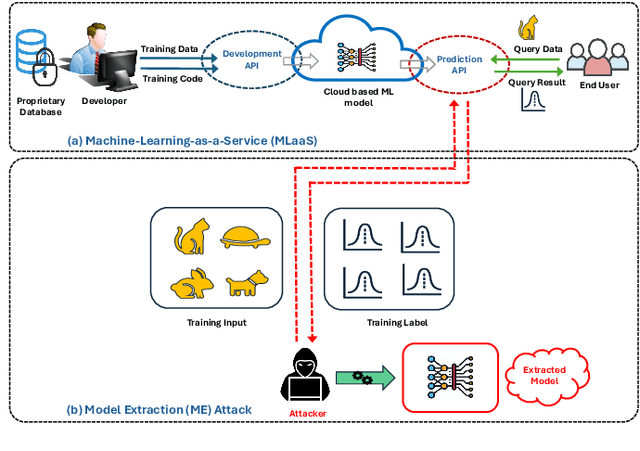
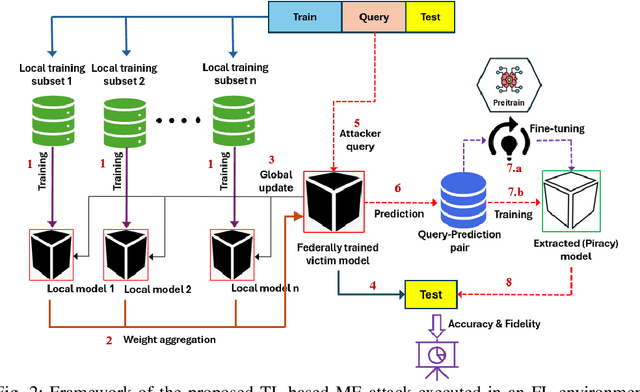
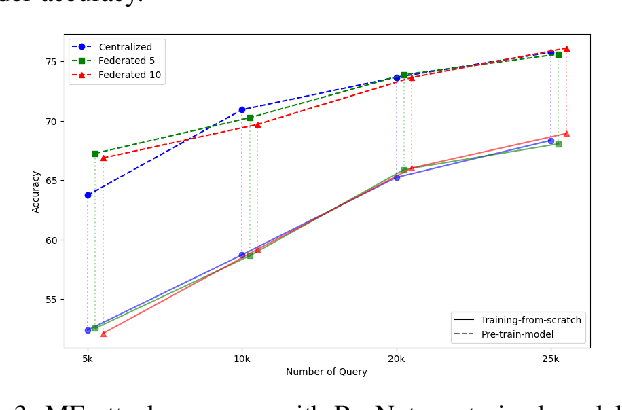
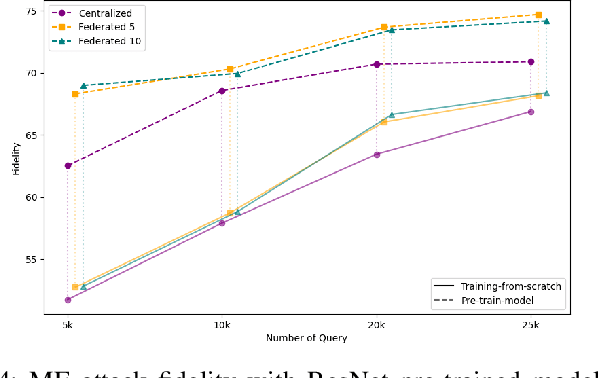
Federated Learning (FL) is a collaborative learning framework designed to protect client data, yet it remains highly vulnerable to Intellectual Property (IP) threats. Model extraction (ME) attacks pose a significant risk to Machine Learning as a Service (MLaaS) platforms, enabling attackers to replicate confidential models by querying black-box (without internal insight) APIs. Despite FL's privacy-preserving goals, its distributed nature makes it particularly susceptible to such attacks. This paper examines the vulnerability of FL-based victim models to two types of model extraction attacks. For various federated clients built under the NVFlare platform, we implemented ME attacks across two deep learning architectures and three image datasets. We evaluate the proposed ME attack performance using various metrics, including accuracy, fidelity, and KL divergence. The experiments show that for different FL clients, the accuracy and fidelity of the extracted model are closely related to the size of the attack query set. Additionally, we explore a transfer learning based approach where pretrained models serve as the starting point for the extraction process. The results indicate that the accuracy and fidelity of the fine-tuned pretrained extraction models are notably higher, particularly with smaller query sets, highlighting potential advantages for attackers.
AI-generated Text Detection: A Multifaceted Approach to Binary and Multiclass Classification
May 15, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in generating text that closely resembles human writing across a wide range of styles and genres. However, such capabilities are prone to potential misuse, such as fake news generation, spam email creation, and misuse in academic assignments. As a result, accurate detection of AI-generated text and identification of the model that generated it are crucial for maintaining the responsible use of LLMs. In this work, we addressed two sub-tasks put forward by the Defactify workshop under AI-Generated Text Detection shared task at the Association for the Advancement of Artificial Intelligence (AAAI 2025): Task A involved distinguishing between human-authored or AI-generated text, while Task B focused on attributing text to its originating language model. For each task, we proposed two neural architectures: an optimized model and a simpler variant. For Task A, the optimized neural architecture achieved fifth place with $F1$ score of 0.994, and for Task B, the simpler neural architecture also ranked fifth place with $F1$ score of 0.627.
Privacy Drift: Evolving Privacy Concerns in Incremental Learning
Dec 06, 2024In the evolving landscape of machine learning (ML), Federated Learning (FL) presents a paradigm shift towards decentralized model training while preserving user data privacy. This paper introduces the concept of ``privacy drift", an innovative framework that parallels the well-known phenomenon of concept drift. While concept drift addresses the variability in model accuracy over time due to changes in the data, privacy drift encapsulates the variation in the leakage of private information as models undergo incremental training. By defining and examining privacy drift, this study aims to unveil the nuanced relationship between the evolution of model performance and the integrity of data privacy. Through rigorous experimentation, we investigate the dynamics of privacy drift in FL systems, focusing on how model updates and data distribution shifts influence the susceptibility of models to privacy attacks, such as membership inference attacks (MIA). Our results highlight a complex interplay between model accuracy and privacy safeguards, revealing that enhancements in model performance can lead to increased privacy risks. We provide empirical evidence from experiments on customized datasets derived from CIFAR-100 (Canadian Institute for Advanced Research, 100 classes), showcasing the impact of data and concept drift on privacy. This work lays the groundwork for future research on privacy-aware machine learning, aiming to achieve a delicate balance between model accuracy and data privacy in decentralized environments.
Accuracy-Privacy Trade-off in the Mitigation of Membership Inference Attack in Federated Learning
Jul 26, 2024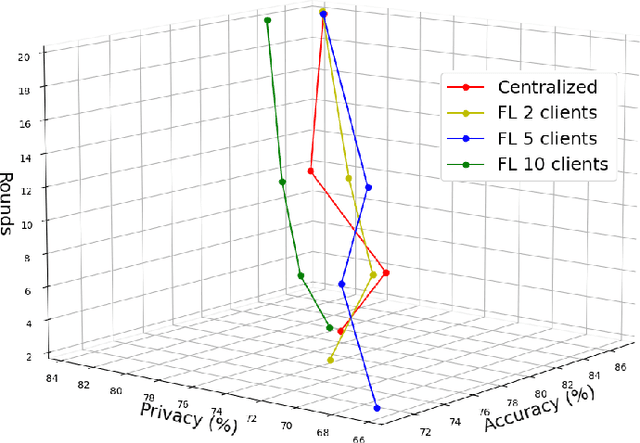
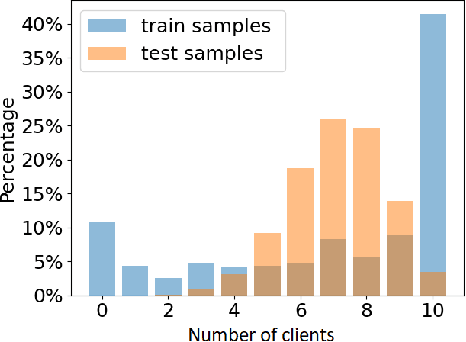
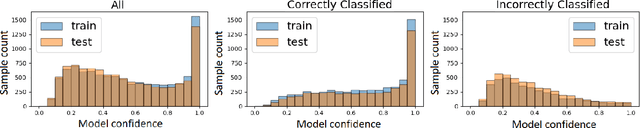
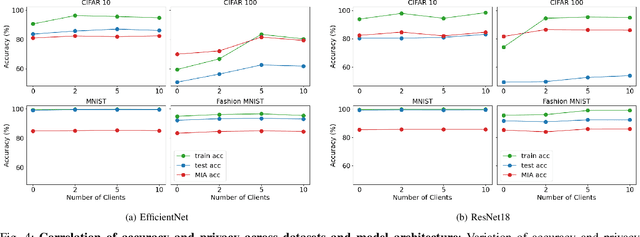
Over the last few years, federated learning (FL) has emerged as a prominent method in machine learning, emphasizing privacy preservation by allowing multiple clients to collaboratively build a model while keeping their training data private. Despite this focus on privacy, FL models are susceptible to various attacks, including membership inference attacks (MIAs), posing a serious threat to data confidentiality. In a recent study, Rezaei \textit{et al.} revealed the existence of an accuracy-privacy trade-off in deep ensembles and proposed a few fusion strategies to overcome it. In this paper, we aim to explore the relationship between deep ensembles and FL. Specifically, we investigate whether confidence-based metrics derived from deep ensembles apply to FL and whether there is a trade-off between accuracy and privacy in FL with respect to MIA. Empirical investigations illustrate a lack of a non-monotonic correlation between the number of clients and the accuracy-privacy trade-off. By experimenting with different numbers of federated clients, datasets, and confidence-metric-based fusion strategies, we identify and analytically justify the clear existence of the accuracy-privacy trade-off.
Leveraging Reinforcement Learning in Red Teaming for Advanced Ransomware Attack Simulations
Jun 25, 2024Ransomware presents a significant and increasing threat to individuals and organizations by encrypting their systems and not releasing them until a large fee has been extracted. To bolster preparedness against potential attacks, organizations commonly conduct red teaming exercises, which involve simulated attacks to assess existing security measures. This paper proposes a novel approach utilizing reinforcement learning (RL) to simulate ransomware attacks. By training an RL agent in a simulated environment mirroring real-world networks, effective attack strategies can be learned quickly, significantly streamlining traditional, manual penetration testing processes. The attack pathways revealed by the RL agent can provide valuable insights to the defense team, helping them identify network weak points and develop more resilient defensive measures. Experimental results on a 152-host example network confirm the effectiveness of the proposed approach, demonstrating the RL agent's capability to discover and orchestrate attacks on high-value targets while evading honeyfiles (decoy files strategically placed to detect unauthorized access).
Discovering Command and Control (C2) Channels on Tor and Public Networks Using Reinforcement Learning
Feb 14, 2024Command and control (C2) channels are an essential component of many types of cyber attacks, as they enable attackers to remotely control their malware-infected machines and execute harmful actions, such as propagating malicious code across networks, exfiltrating confidential data, or initiating distributed denial of service (DDoS) attacks. Identifying these C2 channels is therefore crucial in helping to mitigate and prevent cyber attacks. However, identifying C2 channels typically involves a manual process, requiring deep knowledge and expertise in cyber operations. In this paper, we propose a reinforcement learning (RL) based approach to automatically emulate C2 attack campaigns using both the normal (public) and the Tor networks. In addition, payload size and network firewalls are configured to simulate real-world attack scenarios. Results on a typical network configuration show that the RL agent can automatically discover resilient C2 attack paths utilizing both Tor-based and conventional communication channels, while also bypassing network firewalls.
Discovering Command and Control Channels Using Reinforcement Learning
Jan 13, 2024



Command and control (C2) paths for issuing commands to malware are sometimes the only indicators of its existence within networks. Identifying potential C2 channels is often a manually driven process that involves a deep understanding of cyber tradecraft. Efforts to improve discovery of these channels through using a reinforcement learning (RL) based approach that learns to automatically carry out C2 attack campaigns on large networks, where multiple defense layers are in place serves to drive efficiency for network operators. In this paper, we model C2 traffic flow as a three-stage process and formulate it as a Markov decision process (MDP) with the objective to maximize the number of valuable hosts whose data is exfiltrated. The approach also specifically models payload and defense mechanisms such as firewalls which is a novel contribution. The attack paths learned by the RL agent can in turn help the blue team identify high-priority vulnerabilities and develop improved defense strategies. The method is evaluated on a large network with more than a thousand hosts and the results demonstrate that the agent can effectively learn attack paths while avoiding firewalls.
FedBayes: A Zero-Trust Federated Learning Aggregation to Defend Against Adversarial Attacks
Dec 04, 2023Federated learning has created a decentralized method to train a machine learning model without needing direct access to client data. The main goal of a federated learning architecture is to protect the privacy of each client while still contributing to the training of the global model. However, the main advantage of privacy in federated learning is also the easiest aspect to exploit. Without being able to see the clients' data, it is difficult to determine the quality of the data. By utilizing data poisoning methods, such as backdoor or label-flipping attacks, or by sending manipulated information about their data back to the server, malicious clients are able to corrupt the global model and degrade performance across all clients within a federation. Our novel aggregation method, FedBayes, mitigates the effect of a malicious client by calculating the probabilities of a client's model weights given to the prior model's weights using Bayesian statistics. Our results show that this approach negates the effects of malicious clients and protects the overall federation.
MIA-BAD: An Approach for Enhancing Membership Inference Attack and its Mitigation with Federated Learning
Nov 28, 2023The membership inference attack (MIA) is a popular paradigm for compromising the privacy of a machine learning (ML) model. MIA exploits the natural inclination of ML models to overfit upon the training data. MIAs are trained to distinguish between training and testing prediction confidence to infer membership information. Federated Learning (FL) is a privacy-preserving ML paradigm that enables multiple clients to train a unified model without disclosing their private data. In this paper, we propose an enhanced Membership Inference Attack with the Batch-wise generated Attack Dataset (MIA-BAD), a modification to the MIA approach. We investigate that the MIA is more accurate when the attack dataset is generated batch-wise. This quantitatively decreases the attack dataset while qualitatively improving it. We show how training an ML model through FL, has some distinct advantages and investigate how the threat introduced with the proposed MIA-BAD approach can be mitigated with FL approaches. Finally, we demonstrate the qualitative effects of the proposed MIA-BAD methodology by conducting extensive experiments with various target datasets, variable numbers of federated clients, and training batch sizes.