 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Value in the Age of Scaling: Understanding LLM Scaling Dynamics Under Real-Synthetic Data Mixtures
Nov 17, 2025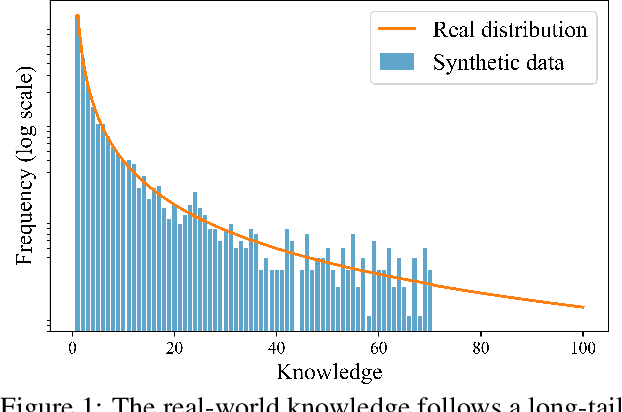
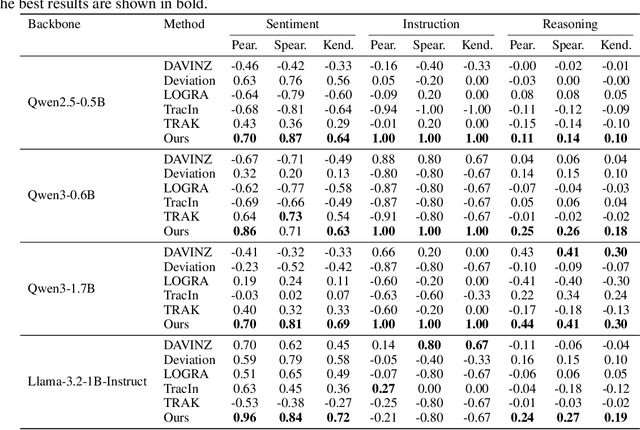
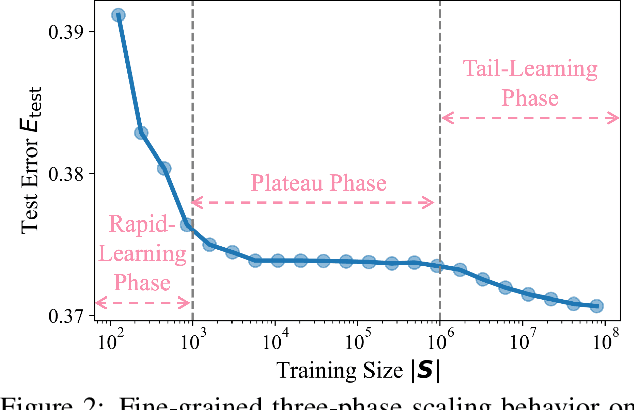
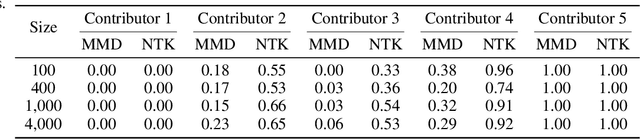
The rapid progress of large language models (LLMs) is fueled by the growing reliance on datasets that blend real and synthetic data. While synthetic data offers scalability and cost-efficiency, it often introduces systematic distributional discrepancies, particularly underrepresenting long-tail knowledge due to truncation effects from data generation mechanisms like top-p sampling, temperature scaling, and finite sampling. These discrepancies pose fundamental challenges in characterizing and evaluating the utility of mixed real-synthetic datasets. In this paper, we identify a three-phase scaling behavior characterized by two breakpoints that reflect transitions in model behavior across learning head and tail knowledge. We further derive an LLM generalization bound designed for real and synthetic mixtures, revealing several key factors that govern their generalization performance. Building on our theoretical findings, we propose an effective yet efficient data valuation method that scales to large-scale datasets. Comprehensive experiments across four tasks, including image classification, sentiment classification, instruction following, and complex reasoning, demonstrate that our method surpasses state-of-the-art baselines in data valuation with significantly low computational cost.
Evaluating Query Efficiency and Accuracy of Transfer Learning-based Model Extraction Attack in Federated Learning
May 25, 2025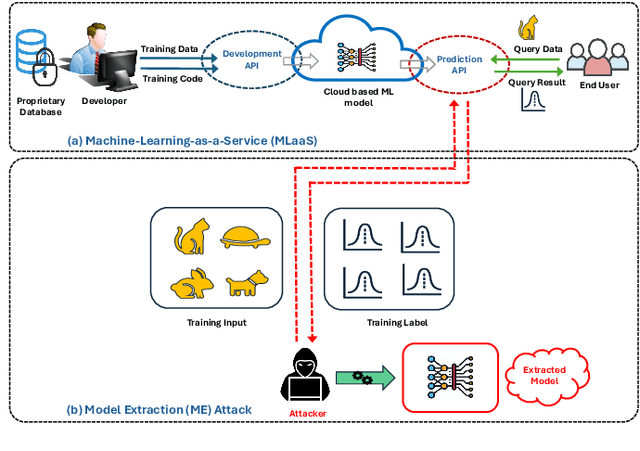
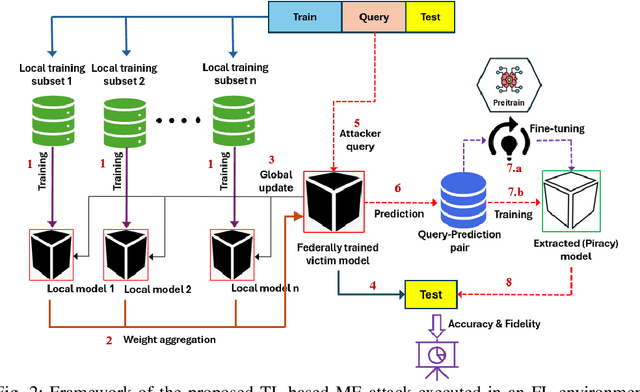
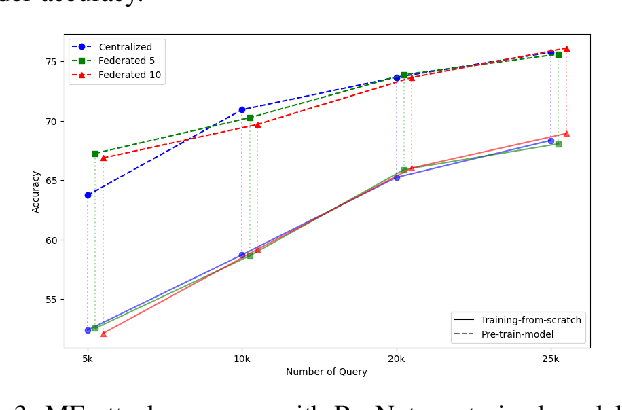
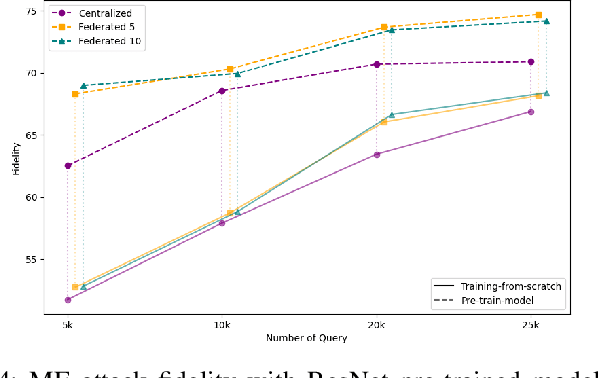
Federated Learning (FL) is a collaborative learning framework designed to protect client data, yet it remains highly vulnerable to Intellectual Property (IP) threats. Model extraction (ME) attacks pose a significant risk to Machine Learning as a Service (MLaaS) platforms, enabling attackers to replicate confidential models by querying black-box (without internal insight) APIs. Despite FL's privacy-preserving goals, its distributed nature makes it particularly susceptible to such attacks. This paper examines the vulnerability of FL-based victim models to two types of model extraction attacks. For various federated clients built under the NVFlare platform, we implemented ME attacks across two deep learning architectures and three image datasets. We evaluate the proposed ME attack performance using various metrics, including accuracy, fidelity, and KL divergence. The experiments show that for different FL clients, the accuracy and fidelity of the extracted model are closely related to the size of the attack query set. Additionally, we explore a transfer learning based approach where pretrained models serve as the starting point for the extraction process. The results indicate that the accuracy and fidelity of the fine-tuned pretrained extraction models are notably higher, particularly with smaller query sets, highlighting potential advantages for attackers.
Accuracy-Privacy Trade-off in the Mitigation of Membership Inference Attack in Federated Learning
Jul 26, 2024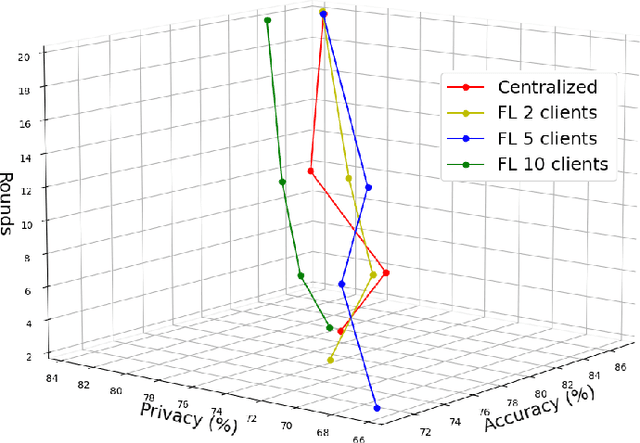
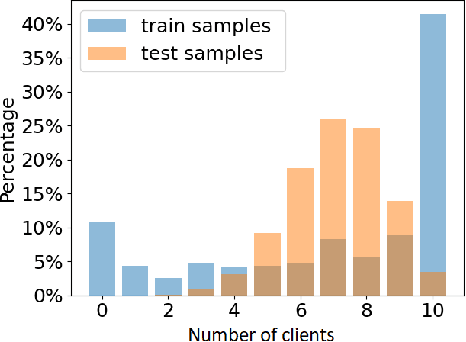
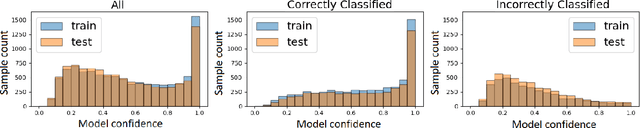
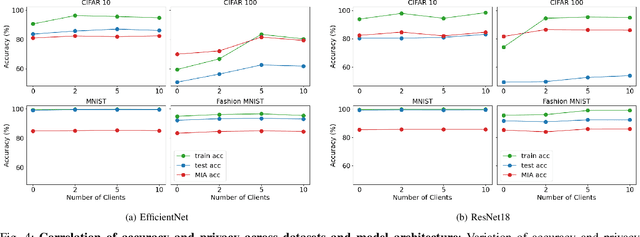
Over the last few years, federated learning (FL) has emerged as a prominent method in machine learning, emphasizing privacy preservation by allowing multiple clients to collaboratively build a model while keeping their training data private. Despite this focus on privacy, FL models are susceptible to various attacks, including membership inference attacks (MIAs), posing a serious threat to data confidentiality. In a recent study, Rezaei \textit{et al.} revealed the existence of an accuracy-privacy trade-off in deep ensembles and proposed a few fusion strategies to overcome it. In this paper, we aim to explore the relationship between deep ensembles and FL. Specifically, we investigate whether confidence-based metrics derived from deep ensembles apply to FL and whether there is a trade-off between accuracy and privacy in FL with respect to MIA. Empirical investigations illustrate a lack of a non-monotonic correlation between the number of clients and the accuracy-privacy trade-off. By experimenting with different numbers of federated clients, datasets, and confidence-metric-based fusion strategies, we identify and analytically justify the clear existence of the accuracy-privacy trade-off.