 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Solving to Verifying: A Unified Objective for Robust Reasoning in LLMs
Nov 19, 2025The reasoning capabilities of large language models (LLMs) have been significantly improved through reinforcement learning (RL). Nevertheless, LLMs still struggle to consistently verify their own reasoning traces. This raises the research question of how to enhance the self-verification ability of LLMs and whether such an ability can further improve reasoning performance. In this work, we propose GRPO-Verif, an algorithm that jointly optimizes solution generation and self-verification within a unified loss function, with an adjustable hyperparameter controlling the weight of the verification signal. Experimental results demonstrate that our method enhances self-verification capability while maintaining comparable performance in reasoning.
Data Value in the Age of Scaling: Understanding LLM Scaling Dynamics Under Real-Synthetic Data Mixtures
Nov 17, 2025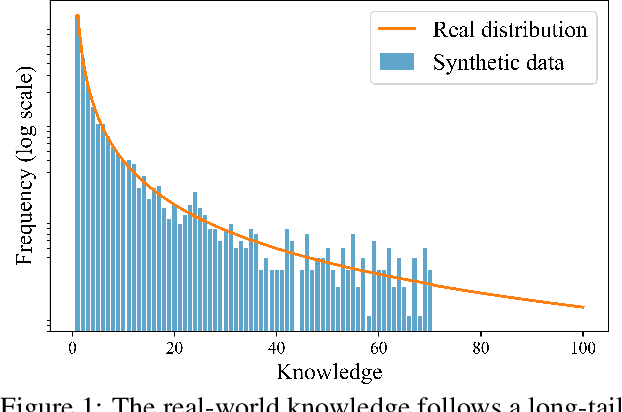
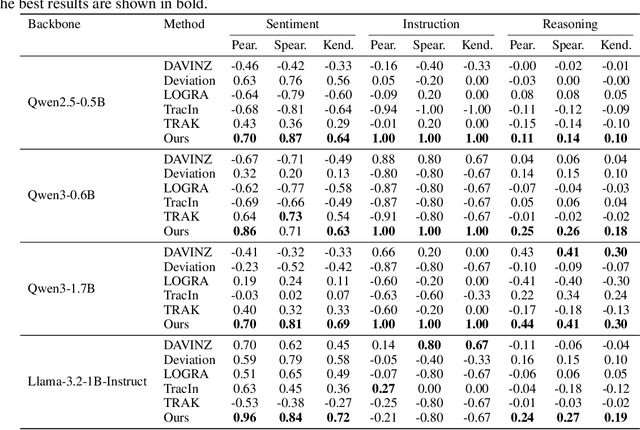
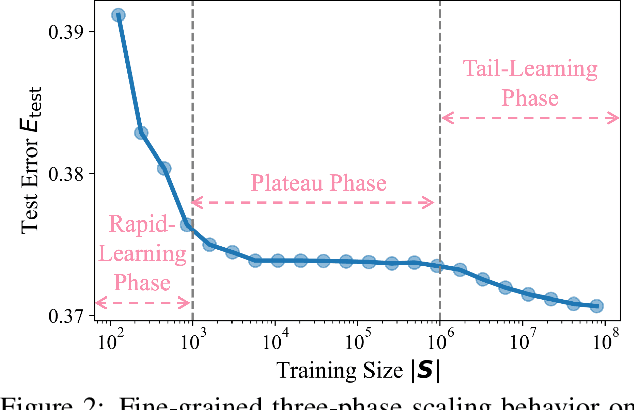
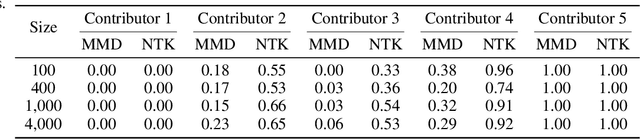
The rapid progress of large language models (LLMs) is fueled by the growing reliance on datasets that blend real and synthetic data. While synthetic data offers scalability and cost-efficiency, it often introduces systematic distributional discrepancies, particularly underrepresenting long-tail knowledge due to truncation effects from data generation mechanisms like top-p sampling, temperature scaling, and finite sampling. These discrepancies pose fundamental challenges in characterizing and evaluating the utility of mixed real-synthetic datasets. In this paper, we identify a three-phase scaling behavior characterized by two breakpoints that reflect transitions in model behavior across learning head and tail knowledge. We further derive an LLM generalization bound designed for real and synthetic mixtures, revealing several key factors that govern their generalization performance. Building on our theoretical findings, we propose an effective yet efficient data valuation method that scales to large-scale datasets. Comprehensive experiments across four tasks, including image classification, sentiment classification, instruction following, and complex reasoning, demonstrate that our method surpasses state-of-the-art baselines in data valuation with significantly low computational cost.
AR-RAG: Autoregressive Retrieval Augmentation for Image Generation
Jun 08, 2025We introduce Autoregressive Retrieval Augmentation (AR-RAG), a novel paradigm that enhances image generation by autoregressively incorporating knearest neighbor retrievals at the patch level. Unlike prior methods that perform a single, static retrieval before generation and condition the entire generation on fixed reference images, AR-RAG performs context-aware retrievals at each generation step, using prior-generated patches as queries to retrieve and incorporate the most relevant patch-level visual references, enabling the model to respond to evolving generation needs while avoiding limitations (e.g., over-copying, stylistic bias, etc.) prevalent in existing methods. To realize AR-RAG, we propose two parallel frameworks: (1) Distribution-Augmentation in Decoding (DAiD), a training-free plug-and-use decoding strategy that directly merges the distribution of model-predicted patches with the distribution of retrieved patches, and (2) Feature-Augmentation in Decoding (FAiD), a parameter-efficient fine-tuning method that progressively smooths the features of retrieved patches via multi-scale convolution operations and leverages them to augment the image generation process. We validate the effectiveness of AR-RAG on widely adopted benchmarks, including Midjourney-30K, GenEval and DPG-Bench, demonstrating significant performance gains over state-of-the-art image generation models.
MetaScientist: A Human-AI Synergistic Framework for Automated Mechanical Metamaterial Design
Dec 20, 2024



The discovery of novel mechanical metamaterials, whose properties are dominated by their engineered structures rather than chemical composition, is a knowledge-intensive and resource-demanding process. To accelerate the design of novel metamaterials, we present MetaScientist, a human-in-the-loop system that integrates advanced AI capabilities with expert oversight with two primary phases: (1) hypothesis generation, where the system performs complex reasoning to generate novel and scientifically sound hypotheses, supported with domain-specific foundation models and inductive biases retrieved from existing literature; (2) 3D structure synthesis, where a 3D structure is synthesized with a novel 3D diffusion model based on the textual hypothesis and refined it with a LLM-based refinement model to achieve better structure properties. At each phase, domain experts iteratively validate the system outputs, and provide feedback and supplementary materials to ensure the alignment of the outputs with scientific principles and human preferences. Through extensive evaluation from human scientists, MetaScientist is able to deliver novel and valid mechanical metamaterial designs that have the potential to be highly impactful in the metamaterial field.
RoRA-VLM: Robust Retrieval-Augmented Vision Language Models
Oct 11, 2024



Current vision-language models (VLMs) still exhibit inferior performance on knowledge-intensive tasks, primarily due to the challenge of accurately encoding all the associations between visual objects and scenes to their corresponding entities and background knowledge. While retrieval augmentation methods offer an efficient way to integrate external knowledge, extending them to vision-language domain presents unique challenges in (1) precisely retrieving relevant information from external sources due to the inherent discrepancy within the multimodal queries, and (2) being resilient to the irrelevant, extraneous and noisy information contained in the retrieved multimodal knowledge snippets. In this work, we introduce RORA-VLM, a novel and robust retrieval augmentation framework specifically tailored for VLMs, with two key innovations: (1) a 2-stage retrieval process with image-anchored textual-query expansion to synergistically combine the visual and textual information in the query and retrieve the most relevant multimodal knowledge snippets; and (2) a robust retrieval augmentation method that strengthens the resilience of VLMs against irrelevant information in the retrieved multimodal knowledge by injecting adversarial noises into the retrieval-augmented training process, and filters out extraneous visual information, such as unrelated entities presented in images, via a query-oriented visual token refinement strategy. We conduct extensive experiments to validate the effectiveness and robustness of our proposed methods on three widely adopted benchmark datasets. Our results demonstrate that with a minimal amount of training instance, RORA-VLM enables the base model to achieve significant performance improvement and constantly outperform state-of-the-art retrieval-augmented VLMs on all benchmarks while also exhibiting a novel zero-shot domain transfer capability.
MULTISCRIPT: Multimodal Script Learning for Supporting Open Domain Everyday Tasks
Oct 08, 2023Automatically generating scripts (i.e. sequences of key steps described in text) from video demonstrations and reasoning about the subsequent steps are crucial to the modern AI virtual assistants to guide humans to complete everyday tasks, especially unfamiliar ones. However, current methods for generative script learning rely heavily on well-structured preceding steps described in text and/or images or are limited to a certain domain, resulting in a disparity with real-world user scenarios. To address these limitations, we present a new benchmark challenge -- MultiScript, with two new tasks on task-oriented multimodal script learning: (1) multimodal script generation, and (2) subsequent step prediction. For both tasks, the input consists of a target task name and a video illustrating what has been done to complete the target task, and the expected output is (1) a sequence of structured step descriptions in text based on the demonstration video, and (2) a single text description for the subsequent step, respectively. Built from WikiHow, MultiScript covers multimodal scripts in videos and text descriptions for over 6,655 human everyday tasks across 19 diverse domains. To establish baseline performance on MultiScript, we propose two knowledge-guided multimodal generative frameworks that incorporate the task-related knowledge prompted from large language models such as Vicuna. Experimental results show that our proposed approaches significantly improve over the competitive baselines.
The Art of SOCRATIC QUESTIONING: Zero-shot Multimodal Reasoning with Recursive Thinking and Self-Questioning
May 24, 2023



Chain-of-Thought prompting (CoT) enables large-scale language models to solve complex reasoning problems by decomposing the problem and tackling it step-by-step. However, Chain-of-Thought is a greedy thinking process that requires the language model to come up with a starting point and generate the next step solely based on previous steps. This thinking process is different from how humans approach a complex problem e.g., we proactively raise sub-problems related to the original problem and recursively answer them. In this work, we propose Socratic Questioning, a divide-and-conquer fashion algorithm that simulates the self-questioning and recursive thinking process. Socratic Questioning is driven by a Self-Questioning module that employs a large-scale language model to propose sub-problems related to the original problem as intermediate steps and Socratic Questioning recursively backtracks and answers the sub-problems until reaches the original problem. We apply our proposed algorithm to the visual question-answering task as a case study and by evaluating it on three public benchmark datasets, we observe a significant performance improvement over all baselines on (almost) all datasets. In addition, the qualitative analysis clearly demonstrates the intermediate thinking steps elicited by Socratic Questioning are similar to the human's recursively thinking process of a complex reasoning problem.
A Deep-Learning Framework for Improving COVID-19 CT Image Quality and Diagnostic Accuracy
Dec 16, 2021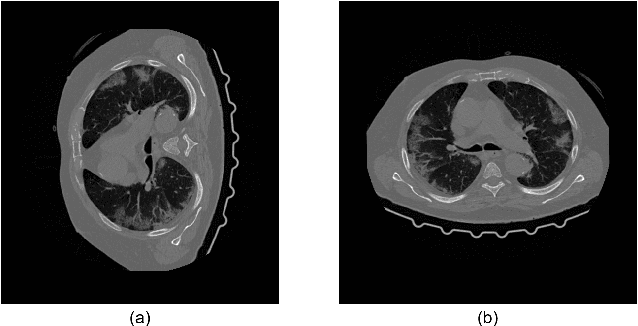
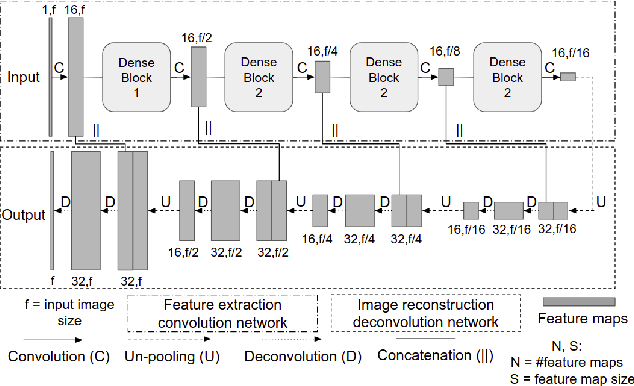
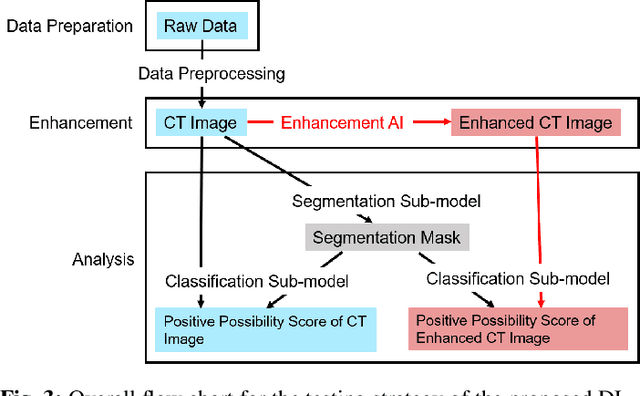
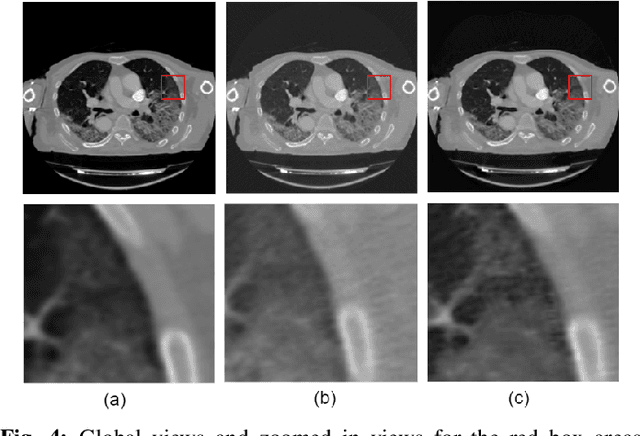
We present a deep-learning based computing framework for fast-and-accurate CT (DL-FACT) testing of COVID-19. Our CT-based DL framework was developed to improve the testing speed and accuracy of COVID-19 (plus its variants) via a DL-based approach for CT image enhancement and classification. The image enhancement network is adapted from DDnet, short for DenseNet and Deconvolution based network. To demonstrate its speed and accuracy, we evaluated DL-FACT across several sources of COVID-19 CT images. Our results show that DL-FACT can significantly shorten the turnaround time from days to minutes and improve the COVID-19 testing accuracy up to 91%. DL-FACT could be used as a software tool for medical professionals in diagnosing and monitoring COVID-19.