 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Self-Evolving Synthetic Data to Verifiable-Reward RL: Post-Training Multi-turn Interactive Tool-Using Agents
Jan 30, 2026Interactive tool-using agents must solve real-world tasks via multi-turn interaction with both humans and external environments, requiring dialogue state tracking, multi-step tool execution, while following complex instructions. Post-training such agents is challenging because synthesis for high-quality multi-turn tool-use data is difficult to scale, and reinforcement learning (RL) could face noisy signals caused by user simulation, leading to degraded training efficiency. We propose a unified framework that combines a self-evolving data agent with verifier-based RL. Our system, EigenData, is a hierarchical multi-agent engine that synthesizes tool-grounded dialogues together with executable per-instance checkers, and improves generation reliability via closed-loop self-evolving process that updates prompts and workflow. Building on the synthetic data, we develop an RL recipe that first fine-tunes the user model and then applies GRPO-style training with trajectory-level group-relative advantages and dynamic filtering, yielding consistent improvements beyond SFT. Evaluated on tau^2-bench, our best model reaches 73.0% pass^1 on Airline and 98.3% pass^1 on Telecom, matching or exceeding frontier models. Overall, our results suggest a scalable pathway for bootstrapping complex tool-using behaviors without expensive human annotation.
Toward Ultra-Long-Horizon Agentic Science: Cognitive Accumulation for Machine Learning Engineering
Jan 15, 2026The advancement of artificial intelligence toward agentic science is currently bottlenecked by the challenge of ultra-long-horizon autonomy, the ability to sustain strategic coherence and iterative correction over experimental cycles spanning days or weeks. While Large Language Models (LLMs) have demonstrated prowess in short-horizon reasoning, they are easily overwhelmed by execution details in the high-dimensional, delayed-feedback environments of real-world research, failing to consolidate sparse feedback into coherent long-term guidance. Here, we present ML-Master 2.0, an autonomous agent that masters ultra-long-horizon machine learning engineering (MLE) which is a representative microcosm of scientific discovery. By reframing context management as a process of cognitive accumulation, our approach introduces Hierarchical Cognitive Caching (HCC), a multi-tiered architecture inspired by computer systems that enables the structural differentiation of experience over time. By dynamically distilling transient execution traces into stable knowledge and cross-task wisdom, HCC allows agents to decouple immediate execution from long-term experimental strategy, effectively overcoming the scaling limits of static context windows. In evaluations on OpenAI's MLE-Bench under 24-hour budgets, ML-Master 2.0 achieves a state-of-the-art medal rate of 56.44%. Our findings demonstrate that ultra-long-horizon autonomy provides a scalable blueprint for AI capable of autonomous exploration beyond human-precedent complexities.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
One Prompt Fits All: Universal Graph Adaptation for Pretrained Models
Sep 26, 2025Graph Prompt Learning (GPL) has emerged as a promising paradigm that bridges graph pretraining models and downstream scenarios, mitigating label dependency and the misalignment between upstream pretraining and downstream tasks. Although existing GPL studies explore various prompt strategies, their effectiveness and underlying principles remain unclear. We identify two critical limitations: (1) Lack of consensus on underlying mechanisms: Despite current GPLs have advanced the field, there is no consensus on how prompts interact with pretrained models, as different strategies intervene at varying spaces within the model, i.e., input-level, layer-wise, and representation-level prompts. (2) Limited scenario adaptability: Most methods fail to generalize across diverse downstream scenarios, especially under data distribution shifts (e.g., homophilic-to-heterophilic graphs). To address these issues, we theoretically analyze existing GPL approaches and reveal that representation-level prompts essentially function as fine-tuning a simple downstream classifier, proposing that graph prompt learning should focus on unleashing the capability of pretrained models, and the classifier adapts to downstream scenarios. Based on our findings, we propose UniPrompt, a novel GPL method that adapts any pretrained models, unleashing the capability of pretrained models while preserving the structure of the input graph. Extensive experiments demonstrate that our method can effectively integrate with various pretrained models and achieve strong performance across in-domain and cross-domain scenarios.
HGMP:Heterogeneous Graph Multi-Task Prompt Learning
Jul 10, 2025


The pre-training and fine-tuning methods have gained widespread attention in the field of heterogeneous graph neural networks due to their ability to leverage large amounts of unlabeled data during the pre-training phase, allowing the model to learn rich structural features. However, these methods face the issue of a mismatch between the pre-trained model and downstream tasks, leading to suboptimal performance in certain application scenarios. Prompt learning methods have emerged as a new direction in heterogeneous graph tasks, as they allow flexible adaptation of task representations to address target inconsistency. Building on this idea, this paper proposes a novel multi-task prompt framework for the heterogeneous graph domain, named HGMP. First, to bridge the gap between the pre-trained model and downstream tasks, we reformulate all downstream tasks into a unified graph-level task format. Next, we address the limitations of existing graph prompt learning methods, which struggle to integrate contrastive pre-training strategies in the heterogeneous graph domain. We design a graph-level contrastive pre-training strategy to better leverage heterogeneous information and enhance performance in multi-task scenarios. Finally, we introduce heterogeneous feature prompts, which enhance model performance by refining the representation of input graph features. Experimental results on public datasets show that our proposed method adapts well to various tasks and significantly outperforms baseline methods.
Pisces: An Auto-regressive Foundation Model for Image Understanding and Generation
Jun 12, 2025Recent advances in large language models (LLMs) have enabled multimodal foundation models to tackle both image understanding and generation within a unified framework. Despite these gains, unified models often underperform compared to specialized models in either task. A key challenge in developing unified models lies in the inherent differences between the visual features needed for image understanding versus generation, as well as the distinct training processes required for each modality. In this work, we introduce Pisces, an auto-regressive multimodal foundation model that addresses this challenge through a novel decoupled visual encoding architecture and tailored training techniques optimized for multimodal generation. Combined with meticulous data curation, pretraining, and finetuning, Pisces achieves competitive performance in both image understanding and image generation. We evaluate Pisces on over 20 public benchmarks for image understanding, where it demonstrates strong performance across a wide range of tasks. Additionally, on GenEval, a widely adopted benchmark for image generation, Pisces exhibits robust generative capabilities. Our extensive analysis reveals the synergistic relationship between image understanding and generation, and the benefits of using separate visual encoders, advancing the field of unified multimodal models.
Single-Node Trigger Backdoor Attacks in Graph-Based Recommendation Systems
Jun 10, 2025Graph recommendation systems have been widely studied due to their ability to effectively capture the complex interactions between users and items. However, these systems also exhibit certain vulnerabilities when faced with attacks. The prevailing shilling attack methods typically manipulate recommendation results by injecting a large number of fake nodes and edges. However, such attack strategies face two primary challenges: low stealth and high destructiveness. To address these challenges, this paper proposes a novel graph backdoor attack method that aims to enhance the exposure of target items to the target user in a covert manner, without affecting other unrelated nodes. Specifically, we design a single-node trigger generator, which can effectively expose multiple target items to the target user by inserting only one fake user node. Additionally, we introduce constraint conditions between the target nodes and irrelevant nodes to mitigate the impact of fake nodes on the recommendation system's performance. Experimental results show that the exposure of the target items reaches no less than 50% in 99% of the target users, while the impact on the recommendation system's performance is controlled within approximately 5%.
Boosting LLM Reasoning via Spontaneous Self-Correction
Jun 07, 2025



While large language models (LLMs) have demonstrated remarkable success on a broad range of tasks, math reasoning remains a challenging one. One of the approaches for improving math reasoning is self-correction, which designs self-improving loops to let the model correct its own mistakes. However, existing self-correction approaches treat corrections as standalone post-generation refinements, relying on extra prompt and system designs to elicit self-corrections, instead of performing real-time, spontaneous self-corrections in a single pass. To address this, we propose SPOC, a spontaneous self-correction approach that enables LLMs to generate interleaved solutions and verifications in a single inference pass, with generation dynamically terminated based on verification outcomes, thereby effectively scaling inference time compute. SPOC considers a multi-agent perspective by assigning dual roles -- solution proposer and verifier -- to the same model. We adopt a simple yet effective approach to generate synthetic data for fine-tuning, enabling the model to develop capabilities for self-verification and multi-agent collaboration. We further improve its solution proposal and verification accuracy through online reinforcement learning. Experiments on mathematical reasoning benchmarks show that SPOC significantly improves performance. Notably, SPOC boosts the accuracy of Llama-3.1-8B and 70B Instruct models, achieving gains of 8.8% and 11.6% on MATH500, 10.0% and 20.0% on AMC23, and 3.3% and 6.7% on AIME24, respectively.
WorkForceAgent-R1: Incentivizing Reasoning Capability in LLM-based Web Agents via Reinforcement Learning
May 28, 2025Large language models (LLMs)-empowered web agents enables automating complex, real-time web navigation tasks in enterprise environments. However, existing web agents relying on supervised fine-tuning (SFT) often struggle with generalization and robustness due to insufficient reasoning capabilities when handling the inherently dynamic nature of web interactions. In this study, we introduce WorkForceAgent-R1, an LLM-based web agent trained using a rule-based R1-style reinforcement learning framework designed explicitly to enhance single-step reasoning and planning for business-oriented web navigation tasks. We employ a structured reward function that evaluates both adherence to output formats and correctness of actions, enabling WorkForceAgent-R1 to implicitly learn robust intermediate reasoning without explicit annotations or extensive expert demonstrations. Extensive experiments on the WorkArena benchmark demonstrate that WorkForceAgent-R1 substantially outperforms SFT baselines by 10.26-16.59%, achieving competitive performance relative to proprietary LLM-based agents (gpt-4o) in workplace-oriented web navigation tasks.
MAMBO-NET: Multi-Causal Aware Modeling Backdoor-Intervention Optimization for Medical Image Segmentation Network
May 28, 2025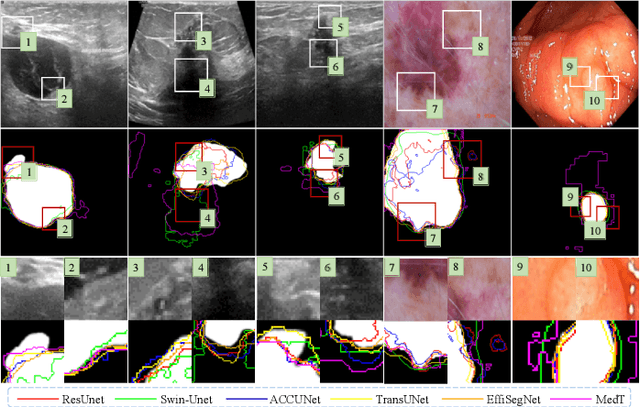
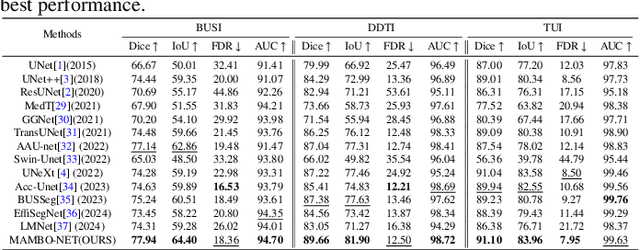
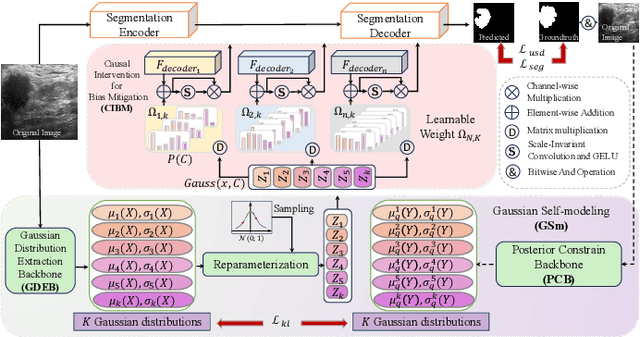
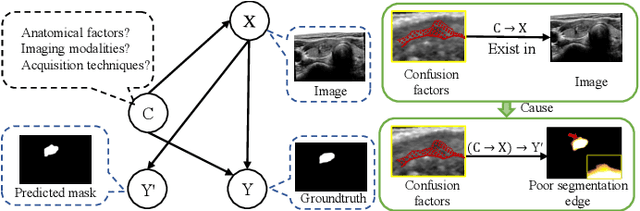
Medical image segmentation methods generally assume that the process from medical image to segmentation is unbiased, and use neural networks to establish conditional probability models to complete the segmentation task. This assumption does not consider confusion factors, which can affect medical images, such as complex anatomical variations and imaging modality limitations. Confusion factors obfuscate the relevance and causality of medical image segmentation, leading to unsatisfactory segmentation results. To address this issue, we propose a multi-causal aware modeling backdoor-intervention optimization (MAMBO-NET) network for medical image segmentation. Drawing insights from causal inference, MAMBO-NET utilizes self-modeling with multi-Gaussian distributions to fit the confusion factors and introduce causal intervention into the segmentation process. Moreover, we design appropriate posterior probability constraints to effectively train the distributions of confusion factors. For the distributions to effectively guide the segmentation and mitigate and eliminate the Impact of confusion factors on the segmentation, we introduce classical backdoor intervention techniques and analyze their feasibility in the segmentation task. To evaluate the effectiveness of our approach, we conducted extensive experiments on five medical image datasets. The results demonstrate that our method significantly reduces the influence of confusion factors, leading to enhanced segmentation accuracy.