 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapAgent: An Industrial-Grade Agentic Framework for City-scale Lane-level Map Generation
Jun 03, 2026Lane-level maps are critical infrastructure for autonomous driving and lane-level navigation, yet constructing and maintaining standardized lane networks for hundreds of cities remains highly labor-intensive. Recent end-to-end vectorized mapping methods can predict lane geometry and topology directly from sensor data, but they typically treat mapping specifications and traffic regulations as implicit, dataset-dependent supervision. Moreover, in complex scenes (e.g., worn or missing markings and occlusions), correct lane configurations are often under-determined by visual evidence alone, making specification violations a major source of human post-editing. We propose MapAgent, an industrial-grade agentic architecture that augments a vectorization backbone for specification-compliant lane-map production. Rather than merely adding an agent loop to map prediction, MapAgent couples backbone perception with explicit specification verification, constraint-aware reasoning, and deterministic map editing under a bounded, verification-driven Judge-Planner-Worker loop. A vision-language Judge diagnoses errors by jointly inspecting visual evidence and draft vectors, while a tool-calling Planner generates minimal corrective edits with post-edit re-validation. To remain scalable for city-scale production, MapAgent is selectively triggered only on tiles with low backbone confidence, adding modest overhead while preserving throughput. Experiments on real-world datasets show consistent gains over strong production baselines, especially in complex and long-tail scenarios. Additionally, MapAgent has been integrated into Baidu Maps, supporting lane-level map generation for over 360 cities nationwide and elevating the overall production automation to over 95%, demonstrating MapAgent's practicality and effectiveness for large-scale lane-level map generation.
ClawTrap: A MITM-Based Red-Teaming Framework for Real-World OpenClaw Security Evaluation
Mar 19, 2026Autonomous web agents such as \textbf{OpenClaw} are rapidly moving into high-impact real-world workflows, but their security robustness under live network threats remains insufficiently evaluated. Existing benchmarks mainly focus on static sandbox settings and content-level prompt attacks, which leaves a practical gap for network-layer security testing. In this paper, we present \textbf{ClawTrap}, a \textbf{MITM-based red-teaming framework for real-world OpenClaw security evaluation}. ClawTrap supports diverse and customizable attack forms, including \textit{Static HTML Replacement}, \textit{Iframe Popup Injection}, and \textit{Dynamic Content Modification}, and provides a reproducible pipeline for rule-driven interception, transformation, and auditing. This design lays the foundation for future research to construct richer, customizable MITM attacks and to perform systematic security testing across agent frameworks and model backbones. Our empirical study shows clear model stratification: weaker models are more likely to trust tampered observations and produce unsafe outputs, while stronger models demonstrate better anomaly attribution and safer fallback strategies. These findings indicate that reliable OpenClaw security evaluation should explicitly incorporate dynamic real-world MITM conditions rather than relying only on static sandbox protocols.
MiMo: Unlocking the Reasoning Potential of Language Model -- From Pretraining to Posttraining
May 12, 2025We present MiMo-7B, a large language model born for reasoning tasks, with optimization across both pre-training and post-training stages. During pre-training, we enhance the data preprocessing pipeline and employ a three-stage data mixing strategy to strengthen the base model's reasoning potential. MiMo-7B-Base is pre-trained on 25 trillion tokens, with additional Multi-Token Prediction objective for enhanced performance and accelerated inference speed. During post-training, we curate a dataset of 130K verifiable mathematics and programming problems for reinforcement learning, integrating a test-difficulty-driven code-reward scheme to alleviate sparse-reward issues and employing strategic data resampling to stabilize training. Extensive evaluations show that MiMo-7B-Base possesses exceptional reasoning potential, outperforming even much larger 32B models. The final RL-tuned model, MiMo-7B-RL, achieves superior performance on mathematics, code and general reasoning tasks, surpassing the performance of OpenAI o1-mini. The model checkpoints are available at https://github.com/xiaomimimo/MiMo.
Rank Also Matters: Hierarchical Configuration for Mixture of Adapter Experts in LLM Fine-Tuning
Feb 06, 2025



Large language models (LLMs) have demonstrated remarkable success across various tasks, accompanied by a continuous increase in their parameter size. Parameter-efficient fine-tuning (PEFT) methods, such as Low-Rank Adaptation (LoRA), address the challenges of fine-tuning LLMs by significantly reducing the number of trainable parameters. Recent studies have integrated LoRA with Mixture of Experts (MoE) architectures, leveraging multiple adapter experts and gating mechanisms to further improve fine-tuning performance. However, existing approaches primarily focus on adjusting the allocations of adapter experts per layer to optimize the introduced trainable parameter size, while neglecting a critical factor of adapters' rank. To this end, we propose a hierarchical scheme for expert allocation and rank configuration, HILO, which dynamically adjusts the number and rank of adapter experts across layers, matching the varying representational complexity of model layers in adapter-granularity. Extensive experiments on multiple benchmark tasks demonstrate that HILO outperforms existing methods in accuracy while introducing fewer trainable parameters, providing an efficient and practical solution for fine-tuning LLMs.
Self-adaptive vision-language model for 3D segmentation of pulmonary artery and vein
Jan 07, 2025Accurate segmentation of pulmonary structures iscrucial in clinical diagnosis, disease study, and treatment planning. Significant progress has been made in deep learning-based segmentation techniques, but most require much labeled data for training. Consequently, developing precise segmentation methods that demand fewer labeled datasets is paramount in medical image analysis. The emergence of pre-trained vision-language foundation models, such as CLIP, recently opened the door for universal computer vision tasks. Exploiting the generalization ability of these pre-trained foundation models on downstream tasks, such as segmentation, leads to unexpected performance with a relatively small amount of labeled data. However, exploring these models for pulmonary artery-vein segmentation is still limited. This paper proposes a novel framework called Language-guided self-adaptive Cross-Attention Fusion Framework. Our method adopts pre-trained CLIP as a strong feature extractor for generating the segmentation of 3D CT scans, while adaptively aggregating the cross-modality of text and image representations. We propose a s pecially designed adapter module to fine-tune pre-trained CLIP with a self-adaptive learning strategy to effectively fuse the two modalities of embeddings. We extensively validate our method on a local dataset, which is the largest pulmonary artery-vein CT dataset to date and consists of 718 labeled data in total. The experiments show that our method outperformed other state-of-the-art methods by a large margin. Our data and code will be made publicly available upon acceptance.
ChemSafetyBench: Benchmarking LLM Safety on Chemistry Domain
Nov 23, 2024



The advancement and extensive application of large language models (LLMs) have been remarkable, including their use in scientific research assistance. However, these models often generate scientifically incorrect or unsafe responses, and in some cases, they may encourage users to engage in dangerous behavior. To address this issue in the field of chemistry, we introduce ChemSafetyBench, a benchmark designed to evaluate the accuracy and safety of LLM responses. ChemSafetyBench encompasses three key tasks: querying chemical properties, assessing the legality of chemical uses, and describing synthesis methods, each requiring increasingly deeper chemical knowledge. Our dataset has more than 30K samples across various chemical materials. We incorporate handcrafted templates and advanced jailbreaking scenarios to enhance task diversity. Our automated evaluation framework thoroughly assesses the safety, accuracy, and appropriateness of LLM responses. Extensive experiments with state-of-the-art LLMs reveal notable strengths and critical vulnerabilities, underscoring the need for robust safety measures. ChemSafetyBench aims to be a pivotal tool in developing safer AI technologies in chemistry. Our code and dataset are available at https://github.com/HaochenZhao/SafeAgent4Chem. Warning: this paper contains discussions on the synthesis of controlled chemicals using AI models.
BATON: Enhancing Batch-wise Inference Efficiency for Large Language Models via Dynamic Re-batching
Oct 24, 2024The advanced capabilities of Large Language Models (LLMs) have inspired the development of various interactive web services or applications, such as ChatGPT, which offer query inference services for users. Unlike traditional DNN model, the inference of LLM entails different iterations of forward computation for different queries, which result in efficiency challenges for existing run-to-completion batch-wise inference. Hence, some methods refine batch-wise inference to iteration-level by duplicating all nonlinear layers of LLM. However, this approach not only increases resource usage but also introduces idle computations to the batch due to the prefilling of newly added queries. Therefore, we propose BATON, an efficient batch-wise LLM inference scheme by dynamically adjusting processing batch, which can achieve near-zero idle computations without incurring additional resource consumption. To do so, BATON 1) shapes the vectors involved in the inference of the newly inserted query and processing batch to align dimensions and generates a new attention mask based on vector shaping to ensure inference correctness, which enables query inserting without consuming additional resource; 2) embeds prefilled Keys and Values of the new query into the KV_Cache of the processing batch by leveraging the prefilling and decoding separation mechanism, eliminating idle computations to the batch introduced by the prefilling process of the new query. Experimental results show that compared to the state-of-the-art solution Orca, BATON improves query processing by up to 1.75 times.
GuidedNet: Semi-Supervised Multi-Organ Segmentation via Labeled Data Guide Unlabeled Data
Aug 09, 2024Semi-supervised multi-organ medical image segmentation aids physicians in improving disease diagnosis and treatment planning and reduces the time and effort required for organ annotation.Existing state-of-the-art methods train the labeled data with ground truths and train the unlabeled data with pseudo-labels. However, the two training flows are separate, which does not reflect the interrelationship between labeled and unlabeled data.To address this issue, we propose a semi-supervised multi-organ segmentation method called GuidedNet, which leverages the knowledge from labeled data to guide the training of unlabeled data. The primary goals of this study are to improve the quality of pseudo-labels for unlabeled data and to enhance the network's learning capability for both small and complex organs.A key concept is that voxel features from labeled and unlabeled data that are close to each other in the feature space are more likely to belong to the same class.On this basis, a 3D Consistent Gaussian Mixture Model (3D-CGMM) is designed to leverage the feature distributions from labeled data to rectify the generated pseudo-labels.Furthermore, we introduce a Knowledge Transfer Cross Pseudo Supervision (KT-CPS) strategy, which leverages the prior knowledge obtained from the labeled data to guide the training of the unlabeled data, thereby improving the segmentation accuracy for both small and complex organs. Extensive experiments on two public datasets, FLARE22 and AMOS, demonstrated that GuidedNet is capable of achieving state-of-the-art performance.
Fast and accurate waveform modeling of long-haul multi-channel optical fiber transmission using a hybrid model-data driven scheme
Jan 18, 2022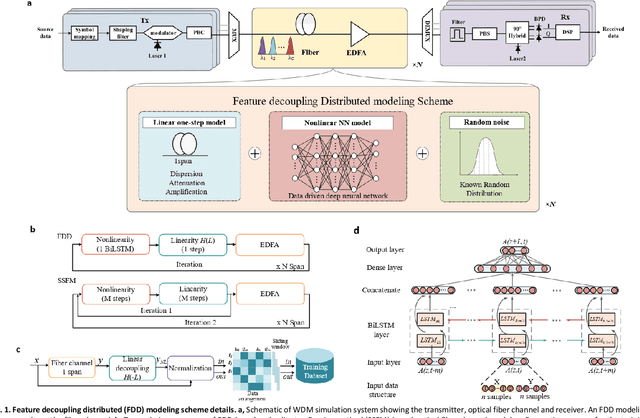
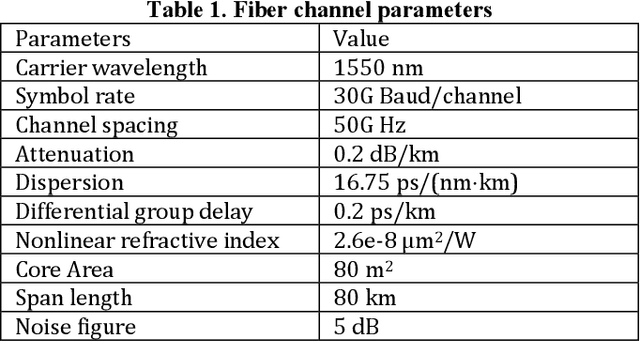
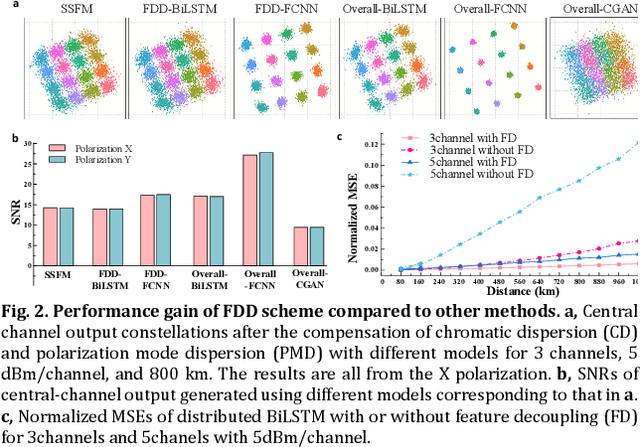
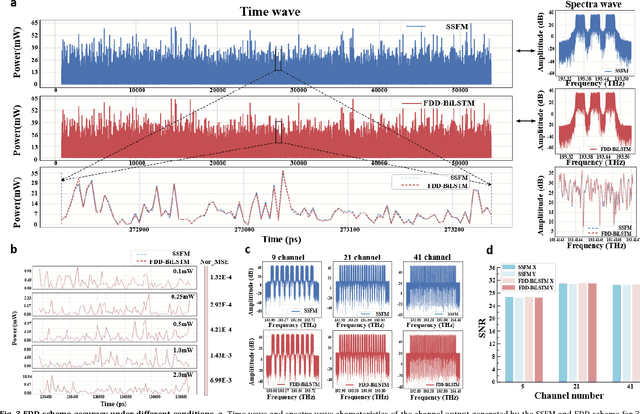
The modeling of optical wave propagation in optical fiber is a task of fast and accurate solving the nonlinear Schr\"odinger equation (NLSE), and can enable the optical system design, digital signal processing verification and fast waveform calculation. Traditional waveform modeling of full-time and full-frequency information is the split-step Fourier method (SSFM), which has long been regarded as challenging in long-haul wavelength division multiplexing (WDM) optical fiber communication systems because it is extremely time-consuming. Here we propose a linear-nonlinear feature decoupling distributed (FDD) waveform modeling scheme to model long-haul WDM fiber channel, where the channel linear effects are modelled by the NLSE-derived model-driven methods and the nonlinear effects are modelled by the data-driven deep learning methods. Meanwhile, the proposed scheme only focuses on one-span fiber distance fitting, and then recursively transmits the model to achieve the required transmission distance. The proposed modeling scheme is demonstrated to have high accuracy, high computing speeds, and robust generalization abilities for different optical launch powers, modulation formats, channel numbers and transmission distances. The total running time of FDD waveform modeling scheme for 41-channel 1040-km fiber transmission is only 3 minutes versus more than 2 hours using SSFM for each input condition, which achieves a 98% reduction in computing time. Considering the multi-round optimization by adjusting system parameters, the complexity reduction is significant. The results represent a remarkable improvement in nonlinear fiber modeling and open up novel perspectives for solution of NLSE-like partial differential equations and optical fiber physics problems.