 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStealthMark: Harmless and Stealthy Ownership Verification for Medical Segmentation via Uncertainty-Guided Backdoors
Jan 23, 2026Annotating medical data for training AI models is often costly and limited due to the shortage of specialists with relevant clinical expertise. This challenge is further compounded by privacy and ethical concerns associated with sensitive patient information. As a result, well-trained medical segmentation models on private datasets constitute valuable intellectual property requiring robust protection mechanisms. Existing model protection techniques primarily focus on classification and generative tasks, while segmentation models-crucial to medical image analysis-remain largely underexplored. In this paper, we propose a novel, stealthy, and harmless method, StealthMark, for verifying the ownership of medical segmentation models under black-box conditions. Our approach subtly modulates model uncertainty without altering the final segmentation outputs, thereby preserving the model's performance. To enable ownership verification, we incorporate model-agnostic explanation methods, e.g. LIME, to extract feature attributions from the model outputs. Under specific triggering conditions, these explanations reveal a distinct and verifiable watermark. We further design the watermark as a QR code to facilitate robust and recognizable ownership claims. We conducted extensive experiments across four medical imaging datasets and five mainstream segmentation models. The results demonstrate the effectiveness, stealthiness, and harmlessness of our method on the original model's segmentation performance. For example, when applied to the SAM model, StealthMark consistently achieved ASR above 95% across various datasets while maintaining less than a 1% drop in Dice and AUC scores, significantly outperforming backdoor-based watermarking methods and highlighting its strong potential for practical deployment. Our implementation code is made available at: https://github.com/Qinkaiyu/StealthMark.
Excavate the potential of Single-Scale Features: A Decomposition Network for Water-Related Optical Image Enhancement
Aug 06, 2025Underwater image enhancement (UIE) techniques aim to improve visual quality of images captured in aquatic environments by addressing degradation issues caused by light absorption and scattering effects, including color distortion, blurring, and low contrast. Current mainstream solutions predominantly employ multi-scale feature extraction (MSFE) mechanisms to enhance reconstruction quality through multi-resolution feature fusion. However, our extensive experiments demonstrate that high-quality image reconstruction does not necessarily rely on multi-scale feature fusion. Contrary to popular belief, our experiments show that single-scale feature extraction alone can match or surpass the performance of multi-scale methods, significantly reducing complexity. To comprehensively explore single-scale feature potential in underwater enhancement, we propose an innovative Single-Scale Decomposition Network (SSD-Net). This architecture introduces an asymmetrical decomposition mechanism that disentangles input image into clean layer along with degradation layer. The former contains scene-intrinsic information and the latter encodes medium-induced interference. It uniquely combines CNN's local feature extraction capabilities with Transformer's global modeling strengths through two core modules: 1) Parallel Feature Decomposition Block (PFDB), implementing dual-branch feature space decoupling via efficient attention operations and adaptive sparse transformer; 2) Bidirectional Feature Communication Block (BFCB), enabling cross-layer residual interactions for complementary feature mining and fusion. This synergistic design preserves feature decomposition independence while establishing dynamic cross-layer information pathways, effectively enhancing degradation decoupling capacity.
Are Spatial-Temporal Graph Convolution Networks for Human Action Recognition Over-Parameterized?
May 15, 2025Spatial-temporal graph convolutional networks (ST-GCNs) showcase impressive performance in skeleton-based human action recognition (HAR). However, despite the development of numerous models, their recognition performance does not differ significantly after aligning the input settings. With this observation, we hypothesize that ST-GCNs are over-parameterized for HAR, a conjecture subsequently confirmed through experiments employing the lottery ticket hypothesis. Additionally, a novel sparse ST-GCNs generator is proposed, which trains a sparse architecture from a randomly initialized dense network while maintaining comparable performance levels to the dense components. Moreover, we generate multi-level sparsity ST-GCNs by integrating sparse structures at various sparsity levels and demonstrate that the assembled model yields a significant enhancement in HAR performance. Thorough experiments on four datasets, including NTU-RGB+D 60(120), Kinetics-400, and FineGYM, demonstrate that the proposed sparse ST-GCNs can achieve comparable performance to their dense components. Even with 95% fewer parameters, the sparse ST-GCNs exhibit a degradation of <1% in top-1 accuracy. Meanwhile, the multi-level sparsity ST-GCNs, which require only 66% of the parameters of the dense ST-GCNs, demonstrate an improvement of >1% in top-1 accuracy. The code is available at https://github.com/davelailai/Sparse-ST-GCN.
A Clinician-Friendly Platform for Ophthalmic Image Analysis Without Technical Barriers
Apr 22, 2025Artificial intelligence (AI) shows remarkable potential in medical imaging diagnostics, but current models typically require retraining when deployed across different clinical centers, limiting their widespread adoption. We introduce GlobeReady, a clinician-friendly AI platform that enables ocular disease diagnosis without retraining/fine-tuning or technical expertise. GlobeReady achieves high accuracy across imaging modalities: 93.9-98.5% for an 11-category fundus photo dataset and 87.2-92.7% for a 15-category OCT dataset. Through training-free local feature augmentation, it addresses domain shifts across centers and populations, reaching an average accuracy of 88.9% across five centers in China, 86.3% in Vietnam, and 90.2% in the UK. The built-in confidence-quantifiable diagnostic approach further boosted accuracy to 94.9-99.4% (fundus) and 88.2-96.2% (OCT), while identifying out-of-distribution cases at 86.3% (49 CFP categories) and 90.6% (13 OCT categories). Clinicians from multiple countries rated GlobeReady highly (average 4.6 out of 5) for its usability and clinical relevance. These results demonstrate GlobeReady's robust, scalable diagnostic capability and potential to support ophthalmic care without technical barriers.
Incomplete Modality Disentangled Representation for Ophthalmic Disease Grading and Diagnosis
Feb 17, 2025



Ophthalmologists typically require multimodal data sources to improve diagnostic accuracy in clinical decisions. However, due to medical device shortages, low-quality data and data privacy concerns, missing data modalities are common in real-world scenarios. Existing deep learning methods tend to address it by learning an implicit latent subspace representation for different modality combinations. We identify two significant limitations of these methods: (1) implicit representation constraints that hinder the model's ability to capture modality-specific information and (2) modality heterogeneity, causing distribution gaps and redundancy in feature representations. To address these, we propose an Incomplete Modality Disentangled Representation (IMDR) strategy, which disentangles features into explicit independent modal-common and modal-specific features by guidance of mutual information, distilling informative knowledge and enabling it to reconstruct valuable missing semantics and produce robust multimodal representations. Furthermore, we introduce a joint proxy learning module that assists IMDR in eliminating intra-modality redundancy by exploiting the extracted proxies from each class. Experiments on four ophthalmology multimodal datasets demonstrate that the proposed IMDR outperforms the state-of-the-art methods significantly.
* 7 Pages, 6 figures
Self-adaptive vision-language model for 3D segmentation of pulmonary artery and vein
Jan 07, 2025Accurate segmentation of pulmonary structures iscrucial in clinical diagnosis, disease study, and treatment planning. Significant progress has been made in deep learning-based segmentation techniques, but most require much labeled data for training. Consequently, developing precise segmentation methods that demand fewer labeled datasets is paramount in medical image analysis. The emergence of pre-trained vision-language foundation models, such as CLIP, recently opened the door for universal computer vision tasks. Exploiting the generalization ability of these pre-trained foundation models on downstream tasks, such as segmentation, leads to unexpected performance with a relatively small amount of labeled data. However, exploring these models for pulmonary artery-vein segmentation is still limited. This paper proposes a novel framework called Language-guided self-adaptive Cross-Attention Fusion Framework. Our method adopts pre-trained CLIP as a strong feature extractor for generating the segmentation of 3D CT scans, while adaptively aggregating the cross-modality of text and image representations. We propose a s pecially designed adapter module to fine-tune pre-trained CLIP with a self-adaptive learning strategy to effectively fuse the two modalities of embeddings. We extensively validate our method on a local dataset, which is the largest pulmonary artery-vein CT dataset to date and consists of 718 labeled data in total. The experiments show that our method outperformed other state-of-the-art methods by a large margin. Our data and code will be made publicly available upon acceptance.
CathAction: A Benchmark for Endovascular Intervention Understanding
Aug 23, 2024Real-time visual feedback from catheterization analysis is crucial for enhancing surgical safety and efficiency during endovascular interventions. However, existing datasets are often limited to specific tasks, small scale, and lack the comprehensive annotations necessary for broader endovascular intervention understanding. To tackle these limitations, we introduce CathAction, a large-scale dataset for catheterization understanding. Our CathAction dataset encompasses approximately 500,000 annotated frames for catheterization action understanding and collision detection, and 25,000 ground truth masks for catheter and guidewire segmentation. For each task, we benchmark recent related works in the field. We further discuss the challenges of endovascular intentions compared to traditional computer vision tasks and point out open research questions. We hope that CathAction will facilitate the development of endovascular intervention understanding methods that can be applied to real-world applications. The dataset is available at https://airvlab.github.io/cathdata/.
Uncertainty is Fragile: Manipulating Uncertainty in Large Language Models
Jul 15, 2024



Large Language Models (LLMs) are employed across various high-stakes domains, where the reliability of their outputs is crucial. One commonly used method to assess the reliability of LLMs' responses is uncertainty estimation, which gauges the likelihood of their answers being correct. While many studies focus on improving the accuracy of uncertainty estimations for LLMs, our research investigates the fragility of uncertainty estimation and explores potential attacks. We demonstrate that an attacker can embed a backdoor in LLMs, which, when activated by a specific trigger in the input, manipulates the model's uncertainty without affecting the final output. Specifically, the proposed backdoor attack method can alter an LLM's output probability distribution, causing the probability distribution to converge towards an attacker-predefined distribution while ensuring that the top-1 prediction remains unchanged. Our experimental results demonstrate that this attack effectively undermines the model's self-evaluation reliability in multiple-choice questions. For instance, we achieved a 100 attack success rate (ASR) across three different triggering strategies in four models. Further, we investigate whether this manipulation generalizes across different prompts and domains. This work highlights a significant threat to the reliability of LLMs and underscores the need for future defenses against such attacks. The code is available at https://github.com/qcznlp/uncertainty_attack.
CLIP-DR: Textual Knowledge-Guided Diabetic Retinopathy Grading with Ranking-aware Prompting
Jul 04, 2024Diabetic retinopathy (DR) is a complication of diabetes and usually takes decades to reach sight-threatening levels. Accurate and robust detection of DR severity is critical for the timely management and treatment of diabetes. However, most current DR grading methods suffer from insufficient robustness to data variability (\textit{e.g.} colour fundus images), posing a significant difficulty for accurate and robust grading. In this work, we propose a novel DR grading framework CLIP-DR based on three observations: 1) Recent pre-trained visual language models, such as CLIP, showcase a notable capacity for generalisation across various downstream tasks, serving as effective baseline models. 2) The grading of image-text pairs for DR often adheres to a discernible natural sequence, yet most existing DR grading methods have primarily overlooked this aspect. 3) A long-tailed distribution among DR severity levels complicates the grading process. This work proposes a novel ranking-aware prompting strategy to help the CLIP model exploit the ordinal information. Specifically, we sequentially design learnable prompts between neighbouring text-image pairs in two different ranking directions. Additionally, we introduce a Similarity Matrix Smooth module into the structure of CLIP to balance the class distribution. Finally, we perform extensive comparisons with several state-of-the-art methods on the GDRBench benchmark, demonstrating our CLIP-DR's robustness and superior performance. The implementation code is available \footnote{\url{https://github.com/Qinkaiyu/CLIP-DR}
Common and Rare Fundus Diseases Identification Using Vision-Language Foundation Model with Knowledge of Over 400 Diseases
Jun 13, 2024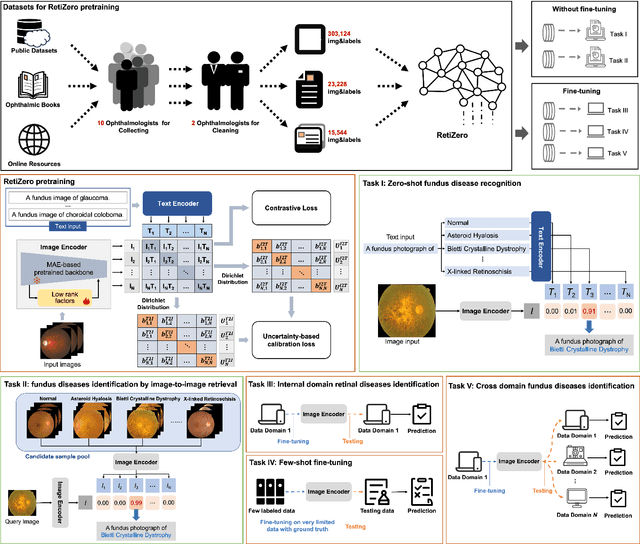
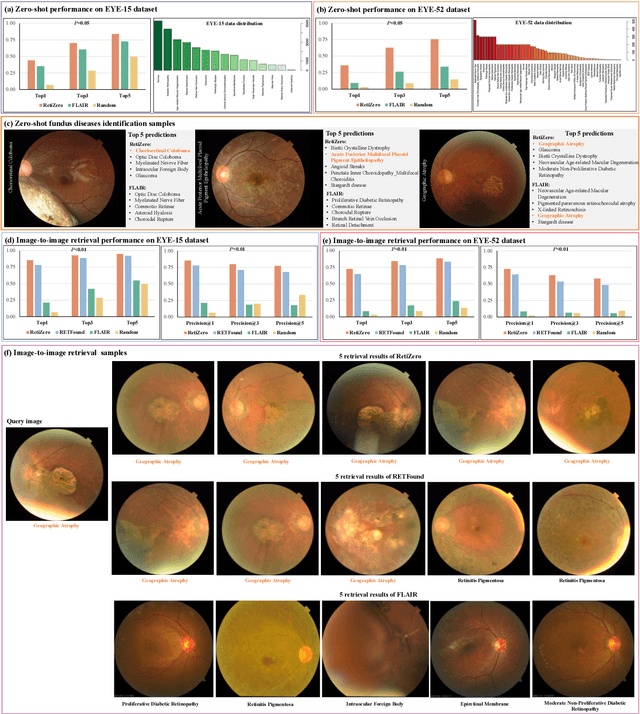
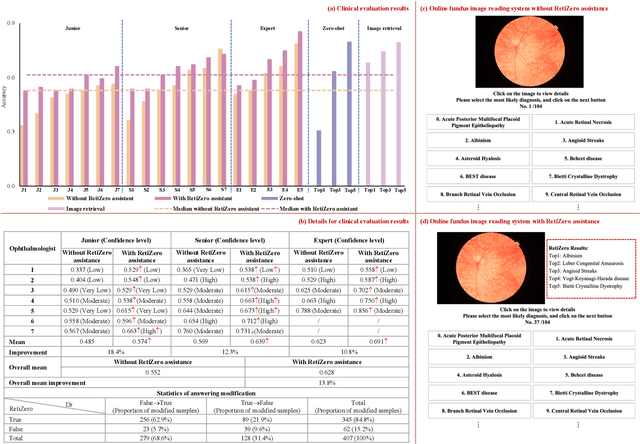
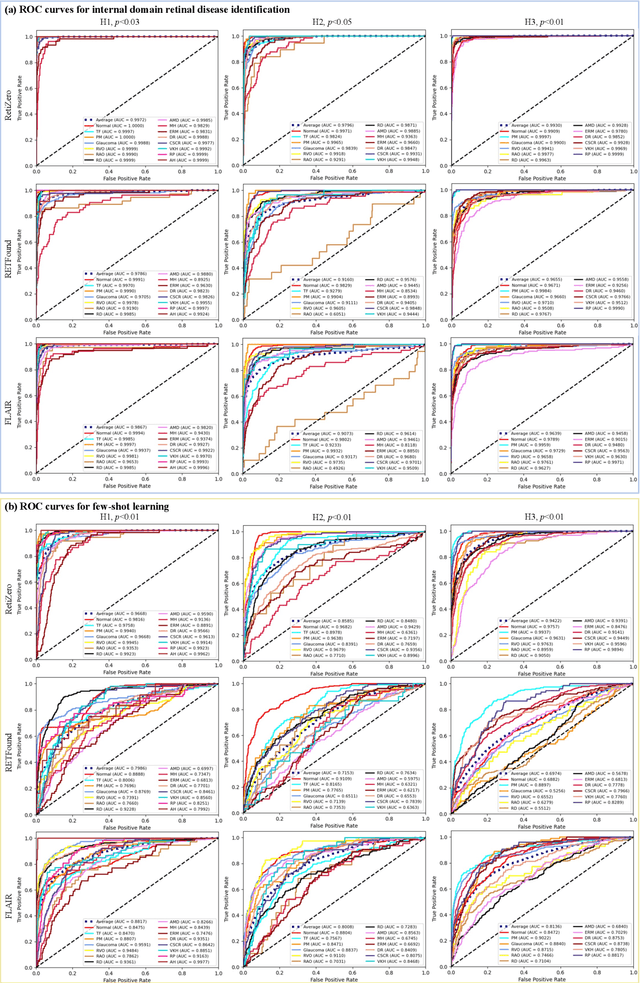
The current retinal artificial intelligence models were trained using data with a limited category of diseases and limited knowledge. In this paper, we present a retinal vision-language foundation model (RetiZero) with knowledge of over 400 fundus diseases. Specifically, we collected 341,896 fundus images paired with text descriptions from 29 publicly available datasets, 180 ophthalmic books, and online resources, encompassing over 400 fundus diseases across multiple countries and ethnicities. RetiZero achieved outstanding performance across various downstream tasks, including zero-shot retinal disease recognition, image-to-image retrieval, internal domain and cross-domain retinal disease classification, and few-shot fine-tuning. Specially, in the zero-shot scenario, RetiZero achieved a Top5 score of 0.8430 and 0.7561 on 15 and 52 fundus diseases respectively. In the image-retrieval task, RetiZero achieved a Top5 score of 0.9500 and 0.8860 on 15 and 52 retinal diseases respectively. Furthermore, clinical evaluations by ophthalmology experts from different countries demonstrate that RetiZero can achieve performance comparable to experienced ophthalmologists using zero-shot and image retrieval methods without requiring model retraining. These capabilities of retinal disease identification strengthen our RetiZero foundation model in clinical implementation.