 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemGym: a Long-Horizon Memory Environment for LLM Agents
May 20, 2026Memory is a central capability for LLM agents operating across long-horizon tasks. Existing memory benchmarks predominantly evaluate retention of personalized information in multi-turn chat scenarios, overlooking the dynamic memory formation that occurs during extended agent execution. Consequently, the memory systems they produce transfer poorly to realistic agentic environments, such as coding and web navigation. We present MemGym, a benchmark for agentic memory that unifies existing agent gyms and in-house memory-grounded pipelines behind one memory-reasoning interface. MemGym spans five evaluation tracks grouped into four agentic regimes: tool-use dialogue (tau2-bench), multi-turn deep-research search (MEMGYM-DR), coding (SWE-Gym and MEMGYM-CODEQA), and computer use (WebArena-Infinity). MemGym reports memory-isolated scores that decouple memory performance from reasoning, retrieval, and tool-use ability, so memory strategies can be ranked without those confounders. Our synthetic pipelines for MEMGYM-CODEQA and MEMGYM-DR are length-controllable, ablation-verified at every stage, and tightly aligned with downstream scenarios. To make evaluation on coding environments academically tractable, we train MemRM, a lightweight reward model (Qwen3-1.7B fine-tuned with QLoRA) that scores compression quality as a fast scalar read in place of full Docker rollouts.
All Circuits Lead to Rome: Rethinking Functional Anisotropy in Circuit and Sheaf Discovery for LLMs
May 12, 2026In this paper, we present empirical and theoretical evidence against a central but largely implicit assumption in circuit and sheaf discovery (CSD), which we term the Functional Anisotropy Hypothesis: the idea that functions in large language models (LLMs) are localised to a unique or near-unique internal mechanism. We show that a single LLM task can instead be supported by multiple, structurally distinct circuits or sheaves that are simultaneously faithful, sparse, and complete. To systematically uncover such competing mechanisms, we introduce Overlap-Aware Sheaf Repulsion, a method that augments the CSD objective with an explicit penalty on structural overlap across multiple discovery runs, enabling the discovery of circuits or sheaves with strong task performance but minimal shared structure across a plethora of common CSD benchmarks. We find that this phenomenon becomes increasingly pronounced as the number of discovered sheaves grows and persists robustly across major CSD methods. We further identify an ultra-sparse three-edge sheaf and show that none of its edges is individually indispensable, undermining even weakened notions of canonical or essential components. To explain these findings, we propose a Distributive Dense Circuit Hypothesis and provide a theoretical analysis demonstrating that non-unique, low-overlap circuit explanations arise naturally from high-dimensional superposition under mild assumptions. Together, our results suggest that mechanistic explanations in LLMs are inherently non-canonical and call for a rethinking of how CSD results should be interpreted and evaluated.
Farther the Shift, Sparser the Representation: Analyzing OOD Mechanisms in LLMs
Mar 03, 2026In this work, we investigate how Large Language Models (LLMs) adapt their internal representations when encountering inputs of increasing difficulty, quantified as the degree of out-of-distribution (OOD) shift. We reveal a consistent and quantifiable phenomenon: as task difficulty increases, whether through harder reasoning questions, longer contexts, or adding answer choices, the last hidden states of LLMs become substantially sparser. In short, \textbf{\textit{the farther the shift, the sparser the representations}}. This sparsity--difficulty relation is observable across diverse models and domains, suggesting that language models respond to unfamiliar or complex inputs by concentrating computation into specialized subspaces in the last hidden state. Through a series of controlled analyses with a learning dynamic explanation, we demonstrate that this sparsity is not incidental but an adaptive mechanism for stabilizing reasoning under OOD. Leveraging this insight, we design \textit{Sparsity-Guided Curriculum In-Context Learning (SG-ICL)}, a strategy that explicitly uses representation sparsity to schedule few-shot demonstrations, leading to considerable performance enhancements. Our study provides new mechanistic insights into how LLMs internalize OOD challenges. The source code is available at the URL: https://github.com/MingyuJ666/sparsityLLM.
SAE-SSV: Supervised Steering in Sparse Representation Spaces for Reliable Control of Language Models
May 22, 2025Large language models (LLMs) have demonstrated impressive capabilities in natural language understanding and generation, but controlling their behavior reliably remains challenging, especially in open-ended generation settings. This paper introduces a novel supervised steering approach that operates in sparse, interpretable representation spaces. We employ sparse autoencoders (SAEs)to obtain sparse latent representations that aim to disentangle semantic attributes from model activations. Then we train linear classifiers to identify a small subspace of task-relevant dimensions in latent representations. Finally, we learn supervised steering vectors constrained to this subspace, optimized to align with target behaviors. Experiments across sentiment, truthfulness, and politics polarity steering tasks with multiple LLMs demonstrate that our supervised steering vectors achieve higher success rates with minimal degradation in generation quality compared to existing methods. Further analysis reveals that a notably small subspace is sufficient for effective steering, enabling more targeted and interpretable interventions.
Do Larger Language Models Imply Better Reasoning? A Pretraining Scaling Law for Reasoning
Apr 04, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of tasks requiring complex reasoning. However, the effects of scaling on their reasoning abilities remain insufficiently understood. In this paper, we introduce a synthetic multihop reasoning environment designed to closely replicate the structure and distribution of real-world large-scale knowledge graphs. Our reasoning task involves completing missing edges in the graph, which requires advanced multi-hop reasoning and mimics real-world reasoning scenarios. To evaluate this, we pretrain language models (LMs) from scratch solely on triples from the incomplete graph and assess their ability to infer the missing edges. Interestingly, we observe that overparameterization can impair reasoning performance due to excessive memorization. We investigate different factors that affect this U-shaped loss curve, including graph structure, model size, and training steps. To predict the optimal model size for a specific knowledge graph, we find an empirical scaling that linearly maps the knowledge graph search entropy to the optimal model size. This work provides new insights into the relationship between scaling and reasoning in LLMs, shedding light on possible ways to optimize their performance for reasoning tasks.
Massive Values in Self-Attention Modules are the Key to Contextual Knowledge Understanding
Feb 03, 2025Large language models (LLMs) have achieved remarkable success in contextual knowledge understanding. In this paper, we show that these concentrated massive values consistently emerge in specific regions of attention queries (Q) and keys (K) while not having such patterns in values (V) in various modern transformer-based LLMs (Q, K, and V mean the representations output by the query, key, and value layers respectively). Through extensive experiments, we further demonstrate that these massive values play a critical role in interpreting contextual knowledge (knowledge obtained from the current context window) rather than in retrieving parametric knowledge stored within the model's parameters. Our further investigation of quantization strategies reveals that ignoring these massive values leads to a pronounced drop in performance on tasks requiring rich contextual understanding, aligning with our analysis. Finally, we trace the emergence of concentrated massive values and find that such concentration is caused by Rotary Positional Encoding (RoPE), which has appeared since the first layers. These findings shed new light on how Q and K operate in LLMs and offer practical insights for model design and optimization. The Code is Available at https://github.com/MingyuJ666/Rope_with_LLM.
Disentangling Memory and Reasoning Ability in Large Language Models
Nov 21, 2024Large Language Models (LLMs) have demonstrated strong performance in handling complex tasks requiring both extensive knowledge and reasoning abilities. However, the existing LLM inference pipeline operates as an opaque process without explicit separation between knowledge retrieval and reasoning steps, making the model's decision-making process unclear and disorganized. This ambiguity can lead to issues such as hallucinations and knowledge forgetting, which significantly impact the reliability of LLMs in high-stakes domains. In this paper, we propose a new inference paradigm that decomposes the complex inference process into two distinct and clear actions: (1) memory recall: which retrieves relevant knowledge, and (2) reasoning: which performs logical steps based on the recalled knowledge. To facilitate this decomposition, we introduce two special tokens memory and reason, guiding the model to distinguish between steps that require knowledge retrieval and those that involve reasoning. Our experiment results show that this decomposition not only improves model performance but also enhances the interpretability of the inference process, enabling users to identify sources of error and refine model responses effectively. The code is available at https://github.com/MingyuJ666/Disentangling-Memory-and-Reasoning.
Target-driven Attack for Large Language Models
Nov 13, 2024



Current large language models (LLM) provide a strong foundation for large-scale user-oriented natural language tasks. Many users can easily inject adversarial text or instructions through the user interface, thus causing LLM model security challenges like the language model not giving the correct answer. Although there is currently a large amount of research on black-box attacks, most of these black-box attacks use random and heuristic strategies. It is unclear how these strategies relate to the success rate of attacks and thus effectively improve model robustness. To solve this problem, we propose our target-driven black-box attack method to maximize the KL divergence between the conditional probabilities of the clean text and the attack text to redefine the attack's goal. We transform the distance maximization problem into two convex optimization problems based on the attack goal to solve the attack text and estimate the covariance. Furthermore, the projected gradient descent algorithm solves the vector corresponding to the attack text. Our target-driven black-box attack approach includes two attack strategies: token manipulation and misinformation attack. Experimental results on multiple Large Language Models and datasets demonstrate the effectiveness of our attack method.
Game-theoretic LLM: Agent Workflow for Negotiation Games
Nov 12, 2024



This paper investigates the rationality of large language models (LLMs) in strategic decision-making contexts, specifically within the framework of game theory. We evaluate several state-of-the-art LLMs across a spectrum of complete-information and incomplete-information games. Our findings reveal that LLMs frequently deviate from rational strategies, particularly as the complexity of the game increases with larger payoff matrices or deeper sequential trees. To address these limitations, we design multiple game-theoretic workflows that guide the reasoning and decision-making processes of LLMs. These workflows aim to enhance the models' ability to compute Nash Equilibria and make rational choices, even under conditions of uncertainty and incomplete information. Experimental results demonstrate that the adoption of these workflows significantly improves the rationality and robustness of LLMs in game-theoretic tasks. Specifically, with the workflow, LLMs exhibit marked improvements in identifying optimal strategies, achieving near-optimal allocations in negotiation scenarios, and reducing susceptibility to exploitation during negotiations. Furthermore, we explore the meta-strategic considerations of whether it is rational for agents to adopt such workflows, recognizing that the decision to use or forgo the workflow constitutes a game-theoretic issue in itself. Our research contributes to a deeper understanding of LLMs' decision-making capabilities in strategic contexts and provides insights into enhancing their rationality through structured workflows. The findings have implications for the development of more robust and strategically sound AI agents capable of navigating complex interactive environments. Code and data supporting this study are available at \url{https://github.com/Wenyueh/game_theory}.
AIPatient: Simulating Patients with EHRs and LLM Powered Agentic Workflow
Sep 27, 2024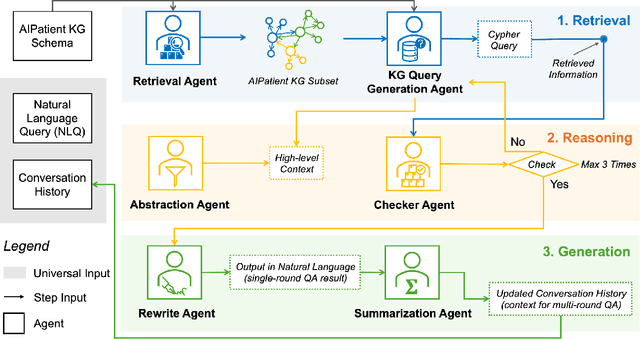
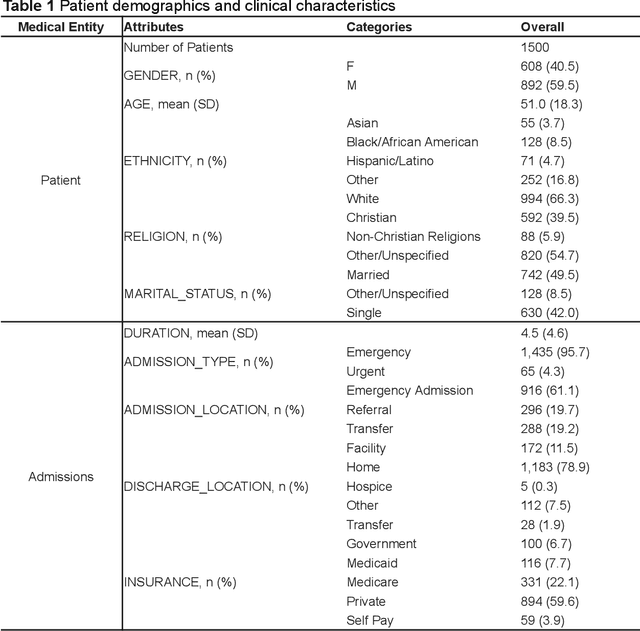
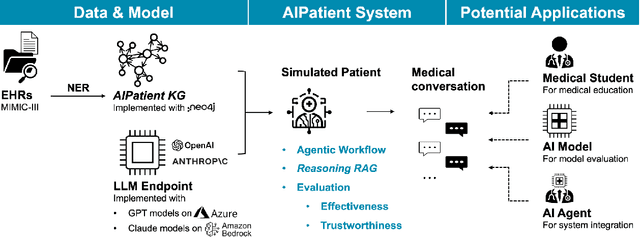
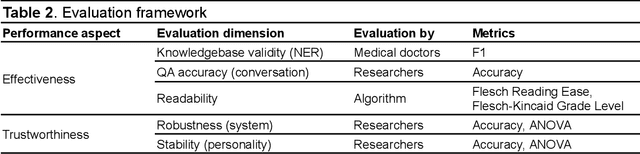
Simulated patient systems play a crucial role in modern medical education and research, providing safe, integrative learning environments and enabling clinical decision-making simulations. Large Language Models (LLM) could advance simulated patient systems by replicating medical conditions and patient-doctor interactions with high fidelity and low cost. However, ensuring the effectiveness and trustworthiness of these systems remains a challenge, as they require a large, diverse, and precise patient knowledgebase, along with a robust and stable knowledge diffusion to users. Here, we developed AIPatient, an advanced simulated patient system with AIPatient Knowledge Graph (AIPatient KG) as the input and the Reasoning Retrieval-Augmented Generation (Reasoning RAG) agentic workflow as the generation backbone. AIPatient KG samples data from Electronic Health Records (EHRs) in the Medical Information Mart for Intensive Care (MIMIC)-III database, producing a clinically diverse and relevant cohort of 1,495 patients with high knowledgebase validity (F1 0.89). Reasoning RAG leverages six LLM powered agents spanning tasks including retrieval, KG query generation, abstraction, checker, rewrite, and summarization. This agentic framework reaches an overall accuracy of 94.15% in EHR-based medical Question Answering (QA), outperforming benchmarks that use either no agent or only partial agent integration. Our system also presents high readability (median Flesch Reading Ease 77.23; median Flesch Kincaid Grade 5.6), robustness (ANOVA F-value 0.6126, p<0.1), and stability (ANOVA F-value 0.782, p<0.1). The promising performance of the AIPatient system highlights its potential to support a wide range of applications, including medical education, model evaluation, and system integration.