 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM as GNN: Graph Vocabulary Learning for Text-Attributed Graph Foundation Models
Mar 05, 2025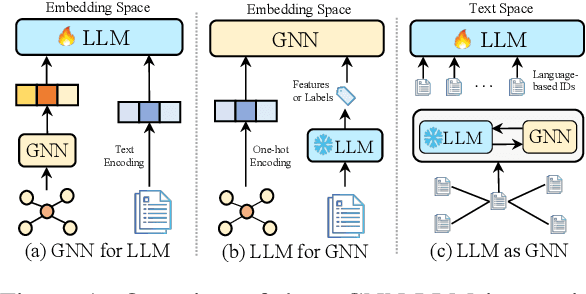
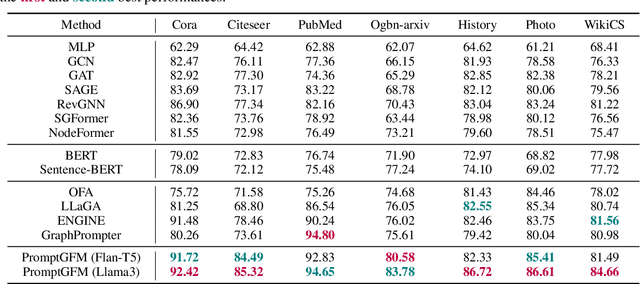
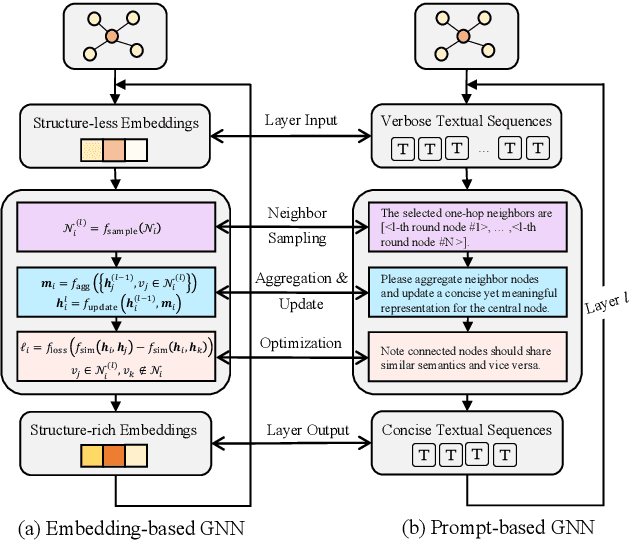
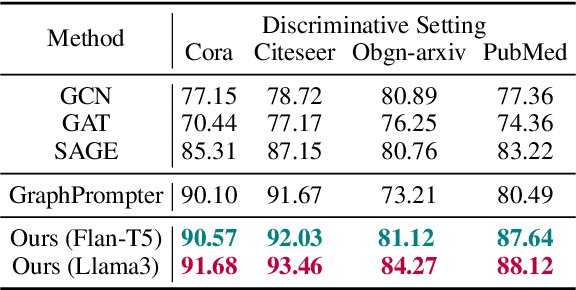
Text-Attributed Graphs (TAGs), where each node is associated with text descriptions, are ubiquitous in real-world scenarios. They typically exhibit distinctive structure and domain-specific knowledge, motivating the development of a Graph Foundation Model (GFM) that generalizes across diverse graphs and tasks. Despite large efforts to integrate Large Language Models (LLMs) and Graph Neural Networks (GNNs) for TAGs, existing approaches suffer from decoupled architectures with two-stage alignment, limiting their synergistic potential. Even worse, existing methods assign out-of-vocabulary (OOV) tokens to graph nodes, leading to graph-specific semantics, token explosion, and incompatibility with task-oriented prompt templates, which hinders cross-graph and cross-task transferability. To address these challenges, we propose PromptGFM, a versatile GFM for TAGs grounded in graph vocabulary learning. PromptGFM comprises two key components: (1) Graph Understanding Module, which explicitly prompts LLMs to replicate the finest GNN workflow within the text space, facilitating seamless GNN-LLM integration and elegant graph-text alignment; (2) Graph Inference Module, which establishes a language-based graph vocabulary ensuring expressiveness, transferability, and scalability, enabling readable instructions for LLM fine-tuning. Extensive experiments demonstrate our superiority and transferability across diverse graphs and tasks. The code is available at this: https://github.com/agiresearch/PromptGFM.
PersonaX: A Recommendation Agent Oriented User Modeling Framework for Long Behavior Sequence
Mar 04, 2025Recommendation agents leverage large language models for user modeling LLM UM to construct textual personas guiding alignment with real users. However existing LLM UM methods struggle with long user generated content UGC due to context limitations and performance degradation. To address this sampling strategies prioritize relevance or recency are often applied yet they inevitably neglect the diverse user interests embedded within the discarded behaviors resulting in incomplete modeling and degraded profiling quality. Furthermore relevance based sampling requires real time retrieval forcing the user modeling process to operate online which introduces significant latency overhead. In this paper we propose PersonaX an agent agnostic LLM UM framework that tackles these challenges through sub behavior sequence SBS selection and offline multi persona construction. PersonaX extracts compact SBS segments offline to capture diverse user interests generating fine grained textual personas that are cached for efficient online retrieval. This approach ensures that the user persona used for prompting remains highly relevant to the current context while eliminating the need for online user modeling. For SBS selection we ensure both efficiency length less than five and high representational quality by balancing prototypicality and diversity within the sampled data. Extensive experiments validate the effectiveness and versatility of PersonaX in high quality user profiling. Utilizing only 30 to 50 percent of the behavioral data with a sequence length of 480 integrating PersonaX with AgentCF yields an absolute performance improvement of 3 to 11 percent while integration with Agent4Rec results in a gain of 10 to 50 percent. PersonaX as an agent agnostic framework sets a new benchmark for scalable user modeling paving the way for more accurate and efficient LLM driven recommendation agents.
ECCOS: Efficient Capability and Cost Coordinated Scheduling for Multi-LLM Serving
Feb 27, 2025As large language models (LLMs) are increasingly deployed as service endpoints in systems, the surge in query volume creates significant scheduling challenges. Existing scheduling frameworks mainly target at latency optimization while neglecting the capability of LLMs to serve different level of queries, which could lead to computational resource waste. This paper addresses this challenge by proposing a capability-cost coordinated scheduling framework, ECCOS, for multi-LLM serving, which explicitly constrains response quality and workload to optimize LLM inference cost. Specifically, it introduces the two-stage scheduling by designing a multi-objective predictor and a constrained optimizer. The predictor estimates both model capabilities and computational costs through training-based and retrieval-based approaches, while the optimizer determines cost-optimal assignments under quality and workload constraints. It also introduces QAServe, a dataset collected for sample-wise response quality and costs by zero-shot prompting different LLMs on knowledge QA and mathematical reasoning. Extensive experiments demonstrate that ECCOS improves success rates by 6.30% while reducing costs by 10.15% compared to existing methods, consuming less than 0.5% of LLM response time. The code is available at: https://github.com/agiresearch/ECCOS.
I-MCTS: Enhancing Agentic AutoML via Introspective Monte Carlo Tree Search
Feb 21, 2025



Recent advancements in large language models (LLMs) have shown remarkable potential in automating machine learning tasks. However, existing LLM-based agents often struggle with low-diversity and suboptimal code generation. While recent work has introduced Monte Carlo Tree Search (MCTS) to address these issues, limitations persist in the quality and diversity of thoughts generated, as well as in the scalar value feedback mechanisms used for node selection. In this study, we introduce Introspective Monte Carlo Tree Search (I-MCTS), a novel approach that iteratively expands tree nodes through an introspective process that meticulously analyzes solutions and results from parent and sibling nodes. This facilitates a continuous refinement of the node in the search tree, thereby enhancing the overall decision-making process. Furthermore, we integrate a Large Language Model (LLM)-based value model to facilitate direct evaluation of each node's solution prior to conducting comprehensive computational rollouts. A hybrid rewarding mechanism is implemented to seamlessly transition the Q-value from LLM-estimated scores to actual performance scores. This allows higher-quality nodes to be traversed earlier. Applied to the various ML tasks, our approach demonstrates a 6% absolute improvement in performance compared to the strong open-source AutoML agents, showcasing its effectiveness in enhancing agentic AutoML systems. Resource available at https://github.com/jokieleung/I-MCTS
InstructAgent: Building User Controllable Recommender via LLM Agent
Feb 20, 2025Traditional recommender systems usually take the user-platform paradigm, where users are directly exposed under the control of the platform's recommendation algorithms. However, the defect of recommendation algorithms may put users in very vulnerable positions under this paradigm. First, many sophisticated models are often designed with commercial objectives in mind, focusing on the platform's benefits, which may hinder their ability to protect and capture users' true interests. Second, these models are typically optimized using data from all users, which may overlook individual user's preferences. Due to these shortcomings, users may experience several disadvantages under the traditional user-platform direct exposure paradigm, such as lack of control over the recommender system, potential manipulation by the platform, echo chamber effects, or lack of personalization for less active users due to the dominance of active users during collaborative learning. Therefore, there is an urgent need to develop a new paradigm to protect user interests and alleviate these issues. Recently, some researchers have introduced LLM agents to simulate user behaviors, these approaches primarily aim to optimize platform-side performance, leaving core issues in recommender systems unresolved. To address these limitations, we propose a new user-agent-platform paradigm, where agent serves as the protective shield between user and recommender system that enables indirect exposure. To this end, we first construct four recommendation datasets, denoted as $\dataset$, along with user instructions for each record.
A-MEM: Agentic Memory for LLM Agents
Feb 17, 2025While large language model (LLM) agents can effectively use external tools for complex real-world tasks, they require memory systems to leverage historical experiences. Current memory systems enable basic storage and retrieval but lack sophisticated memory organization, despite recent attempts to incorporate graph databases. Moreover, these systems' fixed operations and structures limit their adaptability across diverse tasks. To address this limitation, this paper proposes a novel agentic memory system for LLM agents that can dynamically organize memories in an agentic way. Following the basic principles of the Zettelkasten method, we designed our memory system to create interconnected knowledge networks through dynamic indexing and linking. When a new memory is added, we generate a comprehensive note containing multiple structured attributes, including contextual descriptions, keywords, and tags. The system then analyzes historical memories to identify relevant connections, establishing links where meaningful similarities exist. Additionally, this process enables memory evolution - as new memories are integrated, they can trigger updates to the contextual representations and attributes of existing historical memories, allowing the memory network to continuously refine its understanding. Our approach combines the structured organization principles of Zettelkasten with the flexibility of agent-driven decision making, allowing for more adaptive and context-aware memory management. Empirical experiments on six foundation models show superior improvement against existing SOTA baselines. The source code is available at https://github.com/WujiangXu/AgenticMemory.
Massive Values in Self-Attention Modules are the Key to Contextual Knowledge Understanding
Feb 03, 2025Large language models (LLMs) have achieved remarkable success in contextual knowledge understanding. In this paper, we show that these concentrated massive values consistently emerge in specific regions of attention queries (Q) and keys (K) while not having such patterns in values (V) in various modern transformer-based LLMs (Q, K, and V mean the representations output by the query, key, and value layers respectively). Through extensive experiments, we further demonstrate that these massive values play a critical role in interpreting contextual knowledge (knowledge obtained from the current context window) rather than in retrieving parametric knowledge stored within the model's parameters. Our further investigation of quantization strategies reveals that ignoring these massive values leads to a pronounced drop in performance on tasks requiring rich contextual understanding, aligning with our analysis. Finally, we trace the emergence of concentrated massive values and find that such concentration is caused by Rotary Positional Encoding (RoPE), which has appeared since the first layers. These findings shed new light on how Q and K operate in LLMs and offer practical insights for model design and optimization. The Code is Available at https://github.com/MingyuJ666/Rope_with_LLM.
APEER: Automatic Prompt Engineering Enhances Large Language Model Reranking
Jun 20, 2024Large Language Models (LLMs) have significantly enhanced Information Retrieval (IR) across various modules, such as reranking. Despite impressive performance, current zero-shot relevance ranking with LLMs heavily relies on human prompt engineering. Existing automatic prompt engineering algorithms primarily focus on language modeling and classification tasks, leaving the domain of IR, particularly reranking, underexplored. Directly applying current prompt engineering algorithms to relevance ranking is challenging due to the integration of query and long passage pairs in the input, where the ranking complexity surpasses classification tasks. To reduce human effort and unlock the potential of prompt optimization in reranking, we introduce a novel automatic prompt engineering algorithm named APEER. APEER iteratively generates refined prompts through feedback and preference optimization. Extensive experiments with four LLMs and ten datasets demonstrate the substantial performance improvement of APEER over existing state-of-the-art (SoTA) manual prompts. Furthermore, we find that the prompts generated by APEER exhibit better transferability across diverse tasks and LLMs. Code is available at https://github.com/jincan333/APEER.
MoralBench: Moral Evaluation of LLMs
Jun 06, 2024



In the rapidly evolving field of artificial intelligence, large language models (LLMs) have emerged as powerful tools for a myriad of applications, from natural language processing to decision-making support systems. However, as these models become increasingly integrated into societal frameworks, the imperative to ensure they operate within ethical and moral boundaries has never been more critical. This paper introduces a novel benchmark designed to measure and compare the moral reasoning capabilities of LLMs. We present the first comprehensive dataset specifically curated to probe the moral dimensions of LLM outputs, addressing a wide range of ethical dilemmas and scenarios reflective of real-world complexities. The main contribution of this work lies in the development of benchmark datasets and metrics for assessing the moral identity of LLMs, which accounts for nuance, contextual sensitivity, and alignment with human ethical standards. Our methodology involves a multi-faceted approach, combining quantitative analysis with qualitative insights from ethics scholars to ensure a thorough evaluation of model performance. By applying our benchmark across several leading LLMs, we uncover significant variations in moral reasoning capabilities of different models. These findings highlight the importance of considering moral reasoning in the development and evaluation of LLMs, as well as the need for ongoing research to address the biases and limitations uncovered in our study. We publicly release the benchmark at https://drive.google.com/drive/u/0/folders/1k93YZJserYc2CkqP8d4B3M3sgd3kA8W7 and also open-source the code of the project at https://github.com/agiresearch/MoralBench.
Information Maximization via Variational Autoencoders for Cross-Domain Recommendation
May 31, 2024



Cross-Domain Sequential Recommendation (CDSR) methods aim to address the data sparsity and cold-start problems present in Single-Domain Sequential Recommendation (SDSR). Existing CDSR methods typically rely on overlapping users, designing complex cross-domain modules to capture users' latent interests that can propagate across different domains. However, their propagated informative information is limited to the overlapping users and the users who have rich historical behavior records. As a result, these methods often underperform in real-world scenarios, where most users are non-overlapping (cold-start) and long-tailed. In this research, we introduce a new CDSR framework named Information Maximization Variational Autoencoder (\textbf{\texttt{IM-VAE}}). Here, we suggest using a Pseudo-Sequence Generator to enhance the user's interaction history input for downstream fine-grained CDSR models to alleviate the cold-start issues. We also propose a Generative Recommendation Framework combined with three regularizers inspired by the mutual information maximization (MIM) theory \cite{mcgill1954multivariate} to capture the semantic differences between a user's interests shared across domains and those specific to certain domains, as well as address the informational gap between a user's actual interaction sequences and the pseudo-sequences generated. To the best of our knowledge, this paper is the first CDSR work that considers the information disentanglement and denoising of pseudo-sequences in the open-world recommendation scenario. Empirical experiments illustrate that \texttt{IM-VAE} outperforms the state-of-the-art approaches on two real-world cross-domain datasets on all sorts of users, including cold-start and tailed users, demonstrating the effectiveness of \texttt{IM-VAE} in open-world recommendation.