 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePowerAttention: Exponentially Scaling of Receptive Fields for Effective Sparse Attention
Mar 05, 2025Large Language Models (LLMs) face efficiency bottlenecks due to the quadratic complexity of the attention mechanism when processing long contexts. Sparse attention methods offer a promising solution, but existing approaches often suffer from incomplete effective context and/or require complex implementation of pipeline. We present a comprehensive analysis of sparse attention for autoregressive LLMs from the respective of receptive field, recognize the suboptimal nature of existing methods for expanding the receptive field, and introduce PowerAttention, a novel sparse attention design that facilitates effective and complete context extension through the theoretical analysis. PowerAttention achieves exponential receptive field growth in $d$-layer LLMs, allowing each output token to attend to $2^d$ tokens, ensuring completeness and continuity of the receptive field. Experiments demonstrate that PowerAttention outperforms existing static sparse attention methods by $5\sim 40\%$, especially on tasks demanding long-range dependencies like Passkey Retrieval and RULER, while maintaining a comparable time complexity to sliding window attention. Efficiency evaluations further highlight PowerAttention's superior speedup in both prefilling and decoding phases compared with dynamic sparse attentions and full attention ($3.0\times$ faster on 128K context), making it a highly effective and user-friendly solution for processing long sequences in LLMs.
I-MCTS: Enhancing Agentic AutoML via Introspective Monte Carlo Tree Search
Feb 21, 2025



Recent advancements in large language models (LLMs) have shown remarkable potential in automating machine learning tasks. However, existing LLM-based agents often struggle with low-diversity and suboptimal code generation. While recent work has introduced Monte Carlo Tree Search (MCTS) to address these issues, limitations persist in the quality and diversity of thoughts generated, as well as in the scalar value feedback mechanisms used for node selection. In this study, we introduce Introspective Monte Carlo Tree Search (I-MCTS), a novel approach that iteratively expands tree nodes through an introspective process that meticulously analyzes solutions and results from parent and sibling nodes. This facilitates a continuous refinement of the node in the search tree, thereby enhancing the overall decision-making process. Furthermore, we integrate a Large Language Model (LLM)-based value model to facilitate direct evaluation of each node's solution prior to conducting comprehensive computational rollouts. A hybrid rewarding mechanism is implemented to seamlessly transition the Q-value from LLM-estimated scores to actual performance scores. This allows higher-quality nodes to be traversed earlier. Applied to the various ML tasks, our approach demonstrates a 6% absolute improvement in performance compared to the strong open-source AutoML agents, showcasing its effectiveness in enhancing agentic AutoML systems. Resource available at https://github.com/jokieleung/I-MCTS
InstructAgent: Building User Controllable Recommender via LLM Agent
Feb 20, 2025Traditional recommender systems usually take the user-platform paradigm, where users are directly exposed under the control of the platform's recommendation algorithms. However, the defect of recommendation algorithms may put users in very vulnerable positions under this paradigm. First, many sophisticated models are often designed with commercial objectives in mind, focusing on the platform's benefits, which may hinder their ability to protect and capture users' true interests. Second, these models are typically optimized using data from all users, which may overlook individual user's preferences. Due to these shortcomings, users may experience several disadvantages under the traditional user-platform direct exposure paradigm, such as lack of control over the recommender system, potential manipulation by the platform, echo chamber effects, or lack of personalization for less active users due to the dominance of active users during collaborative learning. Therefore, there is an urgent need to develop a new paradigm to protect user interests and alleviate these issues. Recently, some researchers have introduced LLM agents to simulate user behaviors, these approaches primarily aim to optimize platform-side performance, leaving core issues in recommender systems unresolved. To address these limitations, we propose a new user-agent-platform paradigm, where agent serves as the protective shield between user and recommender system that enables indirect exposure. To this end, we first construct four recommendation datasets, denoted as $\dataset$, along with user instructions for each record.
A-MEM: Agentic Memory for LLM Agents
Feb 17, 2025While large language model (LLM) agents can effectively use external tools for complex real-world tasks, they require memory systems to leverage historical experiences. Current memory systems enable basic storage and retrieval but lack sophisticated memory organization, despite recent attempts to incorporate graph databases. Moreover, these systems' fixed operations and structures limit their adaptability across diverse tasks. To address this limitation, this paper proposes a novel agentic memory system for LLM agents that can dynamically organize memories in an agentic way. Following the basic principles of the Zettelkasten method, we designed our memory system to create interconnected knowledge networks through dynamic indexing and linking. When a new memory is added, we generate a comprehensive note containing multiple structured attributes, including contextual descriptions, keywords, and tags. The system then analyzes historical memories to identify relevant connections, establishing links where meaningful similarities exist. Additionally, this process enables memory evolution - as new memories are integrated, they can trigger updates to the contextual representations and attributes of existing historical memories, allowing the memory network to continuously refine its understanding. Our approach combines the structured organization principles of Zettelkasten with the flexibility of agent-driven decision making, allowing for more adaptive and context-aware memory management. Empirical experiments on six foundation models show superior improvement against existing SOTA baselines. The source code is available at https://github.com/WujiangXu/AgenticMemory.
MultiLingPoT: Enhancing Mathematical Reasoning with Multilingual Program Fine-tuning
Dec 17, 2024Program-of-Thought (PoT), which aims to use programming language instead of natural language as an intermediate step in reasoning, is an important way for LLMs to solve mathematical problems. Since different programming languages excel in different areas, it is natural to use the most suitable language for solving specific problems. However, current PoT research only focuses on single language PoT, ignoring the differences between different programming languages. Therefore, this paper proposes an multilingual program reasoning method, MultiLingPoT. This method allows the model to answer questions using multiple programming languages by fine-tuning on multilingual data. Additionally, prior and posterior hybrid methods are used to help the model select the most suitable language for each problem. Our experimental results show that the training of MultiLingPoT improves each program's mathematical reasoning by about 2.5\%. Moreover, with proper mixing, the performance of MultiLingPoT can be further improved, achieving a 6\% increase compared to the single-language PoT with the data augmentation.Resources of this paper can be found at https://github.com/Nianqi-Li/MultiLingPoT.
QUILL: Quotation Generation Enhancement of Large Language Models
Nov 06, 2024



While Large language models (LLMs) have become excellent writing assistants, they still struggle with quotation generation. This is because they either hallucinate when providing factual quotations or fail to provide quotes that exceed human expectations. To bridge the gap, we systematically study how to evaluate and improve LLMs' performance in quotation generation tasks. We first establish a holistic and automatic evaluation system for quotation generation task, which consists of five criteria each with corresponding automatic metric. To improve the LLMs' quotation generation abilities, we construct a bilingual knowledge base that is broad in scope and rich in dimensions, containing up to 32,022 quotes. Moreover, guided by our critiria, we further design a quotation-specific metric to rerank the retrieved quotations from the knowledge base. Extensive experiments show that our metrics strongly correlate with human preferences. Existing LLMs struggle to generate desired quotes, but our quotation knowledge base and reranking metric help narrow this gap. Our dataset and code are publicly available at https://github.com/GraceXiaoo/QUILL.
SEGMENT+: Long Text Processing with Short-Context Language Models
Oct 09, 2024



There is a growing interest in expanding the input capacity of language models (LMs) across various domains. However, simply increasing the context window does not guarantee robust performance across diverse long-input processing tasks, such as understanding extensive documents and extracting detailed information from lengthy and noisy data. In response, we introduce SEGMENT+, a general framework that enables LMs to handle extended inputs within limited context windows efficiently. SEGMENT+ utilizes structured notes and a filtering module to manage information flow, resulting in a system that is both controllable and interpretable. Our extensive experiments across various model sizes, focusing on long-document question-answering and Needle-in-a-Haystack tasks, demonstrate the effectiveness of SEGMENT+ in improving performance.
Teaching Large Language Models to Express Knowledge Boundary from Their Own Signals
Jun 16, 2024Large language models (LLMs) have achieved great success, but their occasional content fabrication, or hallucination, limits their practical application. Hallucination arises because LLMs struggle to admit ignorance due to inadequate training on knowledge boundaries. We call it a limitation of LLMs that they can not accurately express their knowledge boundary, answering questions they know while admitting ignorance to questions they do not know. In this paper, we aim to teach LLMs to recognize and express their knowledge boundary, so they can reduce hallucinations caused by fabricating when they do not know. We propose CoKE, which first probes LLMs' knowledge boundary via internal confidence given a set of questions, and then leverages the probing results to elicit the expression of the knowledge boundary. Extensive experiments show CoKE helps LLMs express knowledge boundaries, answering known questions while declining unknown ones, significantly improving in-domain and out-of-domain performance.
SLMRec: Empowering Small Language Models for Sequential Recommendation
May 28, 2024



The sequential Recommendation (SR) task involves predicting the next item a user is likely to interact with, given their past interactions. The SR models examine the sequence of a user's actions to discern more complex behavioral patterns and temporal dynamics. Recent research demonstrates the great impact of LLMs on sequential recommendation systems, either viewing sequential recommendation as language modeling or serving as the backbone for user representation. Although these methods deliver outstanding performance, there is scant evidence of the necessity of a large language model and how large the language model is needed, especially in the sequential recommendation scene. Meanwhile, due to the huge size of LLMs, it is inefficient and impractical to apply a LLM-based model in real-world platforms that often need to process billions of traffic logs daily. In this paper, we explore the influence of LLMs' depth by conducting extensive experiments on large-scale industry datasets. Surprisingly, we discover that most intermediate layers of LLMs are redundant. Motivated by this insight, we empower small language models for SR, namely SLMRec, which adopt a simple yet effective knowledge distillation method. Moreover, SLMRec is orthogonal to other post-training efficiency techniques, such as quantization and pruning, so that they can be leveraged in combination. Comprehensive experimental results illustrate that the proposed SLMRec model attains the best performance using only 13% of the parameters found in LLM-based recommendation models, while simultaneously achieving up to 6.6x and 8.0x speedups in training and inference time costs, respectively.
Learning Neural Templates for Recommender Dialogue System
Sep 25, 2021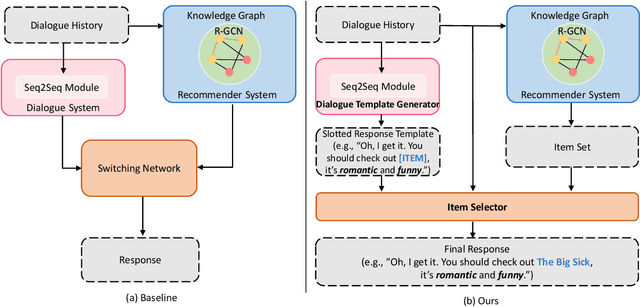

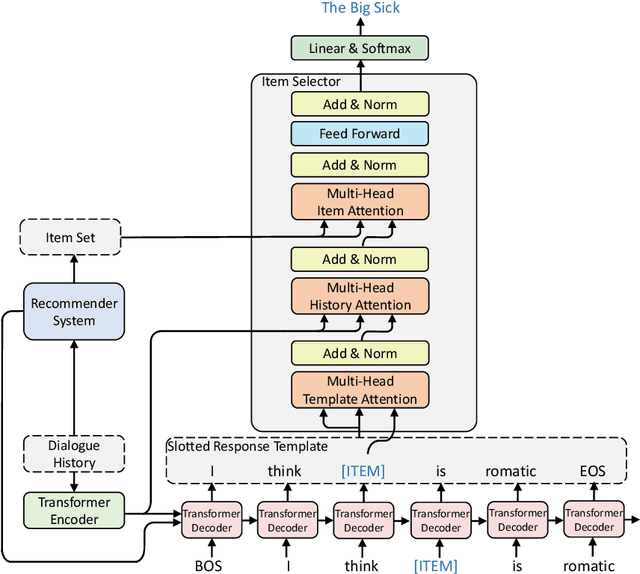

Though recent end-to-end neural models have shown promising progress on Conversational Recommender System (CRS), two key challenges still remain. First, the recommended items cannot be always incorporated into the generated replies precisely and appropriately. Second, only the items mentioned in the training corpus have a chance to be recommended in the conversation. To tackle these challenges, we introduce a novel framework called NTRD for recommender dialogue system that decouples the dialogue generation from the item recommendation. NTRD has two key components, i.e., response template generator and item selector. The former adopts an encoder-decoder model to generate a response template with slot locations tied to target items, while the latter fills in slot locations with the proper items using a sufficient attention mechanism. Our approach combines the strengths of both classical slot filling approaches (that are generally controllable) and modern neural NLG approaches (that are generally more natural and accurate). Extensive experiments on the benchmark ReDial show our NTRD significantly outperforms the previous state-of-the-art methods. Besides, our approach has the unique advantage to produce novel items that do not appear in the training set of dialogue corpus. The code is available at \url{https://github.com/jokieleung/NTRD}.