 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoVLM: Dynamic Mixture-of-Experts Vision-Language Model for Universal Ultrasound Intelligence
Sep 18, 2025Ultrasound imaging has become the preferred imaging modality for early cancer screening due to its advantages of non-ionizing radiation, low cost, and real-time imaging capabilities. However, conventional ultrasound diagnosis heavily relies on physician expertise, presenting challenges of high subjectivity and low diagnostic efficiency. Vision-language models (VLMs) offer promising solutions for this issue, but existing general-purpose models demonstrate limited knowledge in ultrasound medical tasks, with poor generalization in multi-organ lesion recognition and low efficiency across multi-task diagnostics. To address these limitations, we propose EchoVLM, a vision-language model specifically designed for ultrasound medical imaging. The model employs a Mixture of Experts (MoE) architecture trained on data spanning seven anatomical regions. This design enables the model to perform multiple tasks, including ultrasound report generation, diagnosis and visual question-answering (VQA). The experimental results demonstrated that EchoVLM achieved significant improvements of 10.15 and 4.77 points in BLEU-1 scores and ROUGE-1 scores respectively compared to Qwen2-VL on the ultrasound report generation task. These findings suggest that EchoVLM has substantial potential to enhance diagnostic accuracy in ultrasound imaging, thereby providing a viable technical solution for future clinical applications. Source code and model weights are available at https://github.com/Asunatan/EchoVLM.
PowerAttention: Exponentially Scaling of Receptive Fields for Effective Sparse Attention
Mar 05, 2025Large Language Models (LLMs) face efficiency bottlenecks due to the quadratic complexity of the attention mechanism when processing long contexts. Sparse attention methods offer a promising solution, but existing approaches often suffer from incomplete effective context and/or require complex implementation of pipeline. We present a comprehensive analysis of sparse attention for autoregressive LLMs from the respective of receptive field, recognize the suboptimal nature of existing methods for expanding the receptive field, and introduce PowerAttention, a novel sparse attention design that facilitates effective and complete context extension through the theoretical analysis. PowerAttention achieves exponential receptive field growth in $d$-layer LLMs, allowing each output token to attend to $2^d$ tokens, ensuring completeness and continuity of the receptive field. Experiments demonstrate that PowerAttention outperforms existing static sparse attention methods by $5\sim 40\%$, especially on tasks demanding long-range dependencies like Passkey Retrieval and RULER, while maintaining a comparable time complexity to sliding window attention. Efficiency evaluations further highlight PowerAttention's superior speedup in both prefilling and decoding phases compared with dynamic sparse attentions and full attention ($3.0\times$ faster on 128K context), making it a highly effective and user-friendly solution for processing long sequences in LLMs.
A Retrospective Systematic Study on Hierarchical Sparse Query Transformer-assisted Ultrasound Screening for Early Hepatocellular Carcinoma
Feb 06, 2025Hepatocellular carcinoma (HCC) ranks as the third leading cause of cancer-related mortality worldwide, with early detection being crucial for improving patient survival rates. However, early screening for HCC using ultrasound suffers from insufficient sensitivity and is highly dependent on the expertise of radiologists for interpretation. Leveraging the latest advancements in artificial intelligence (AI) in medical imaging, this study proposes an innovative Hierarchical Sparse Query Transformer (HSQformer) model that combines the strengths of Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) to enhance the accuracy of HCC diagnosis in ultrasound screening. The HSQformer leverages sparse latent space representations to capture hierarchical details at various granularities without the need for complex adjustments, and adopts a modular, plug-and-play design philosophy, ensuring the model's versatility and ease of use. The HSQformer's performance was rigorously tested across three distinct clinical scenarios: single-center, multi-center, and high-risk patient testing. In each of these settings, it consistently outperformed existing state-of-the-art models, such as ConvNext and SwinTransformer. Notably, the HSQformer even matched the diagnostic capabilities of senior radiologists and comprehensively surpassed those of junior radiologists. The experimental results from this study strongly demonstrate the effectiveness and clinical potential of AI-assisted tools in HCC screening. The full code is available at https://github.com/Asunatan/HSQformer.
Chain-of-Knowledge: Integrating Knowledge Reasoning into Large Language Models by Learning from Knowledge Graphs
Jun 30, 2024Large Language Models (LLMs) have exhibited impressive proficiency in various natural language processing (NLP) tasks, which involve increasingly complex reasoning. Knowledge reasoning, a primary type of reasoning, aims at deriving new knowledge from existing one.While it has been widely studied in the context of knowledge graphs (KGs), knowledge reasoning in LLMs remains underexplored. In this paper, we introduce Chain-of-Knowledge, a comprehensive framework for knowledge reasoning, including methodologies for both dataset construction and model learning. For dataset construction, we create KnowReason via rule mining on KGs. For model learning, we observe rule overfitting induced by naive training. Hence, we enhance CoK with a trial-and-error mechanism that simulates the human process of internal knowledge exploration. We conduct extensive experiments with KnowReason. Our results show the effectiveness of CoK in refining LLMs in not only knowledge reasoning, but also general reasoning benchmarkms.
Teaching Large Language Models to Express Knowledge Boundary from Their Own Signals
Jun 16, 2024Large language models (LLMs) have achieved great success, but their occasional content fabrication, or hallucination, limits their practical application. Hallucination arises because LLMs struggle to admit ignorance due to inadequate training on knowledge boundaries. We call it a limitation of LLMs that they can not accurately express their knowledge boundary, answering questions they know while admitting ignorance to questions they do not know. In this paper, we aim to teach LLMs to recognize and express their knowledge boundary, so they can reduce hallucinations caused by fabricating when they do not know. We propose CoKE, which first probes LLMs' knowledge boundary via internal confidence given a set of questions, and then leverages the probing results to elicit the expression of the knowledge boundary. Extensive experiments show CoKE helps LLMs express knowledge boundaries, answering known questions while declining unknown ones, significantly improving in-domain and out-of-domain performance.
From Persona to Personalization: A Survey on Role-Playing Language Agents
Apr 28, 2024



Recent advancements in large language models (LLMs) have significantly boosted the rise of Role-Playing Language Agents (RPLAs), i.e., specialized AI systems designed to simulate assigned personas. By harnessing multiple advanced abilities of LLMs, including in-context learning, instruction following, and social intelligence, RPLAs achieve a remarkable sense of human likeness and vivid role-playing performance. RPLAs can mimic a wide range of personas, ranging from historical figures and fictional characters to real-life individuals. Consequently, they have catalyzed numerous AI applications, such as emotional companions, interactive video games, personalized assistants and copilots, and digital clones. In this paper, we conduct a comprehensive survey of this field, illustrating the evolution and recent progress in RPLAs integrating with cutting-edge LLM technologies. We categorize personas into three types: 1) Demographic Persona, which leverages statistical stereotypes; 2) Character Persona, focused on well-established figures; and 3) Individualized Persona, customized through ongoing user interactions for personalized services. We begin by presenting a comprehensive overview of current methodologies for RPLAs, followed by the details for each persona type, covering corresponding data sourcing, agent construction, and evaluation. Afterward, we discuss the fundamental risks, existing limitations, and future prospects of RPLAs. Additionally, we provide a brief review of RPLAs in AI applications, which reflects practical user demands that shape and drive RPLA research. Through this work, we aim to establish a clear taxonomy of RPLA research and applications, and facilitate future research in this critical and ever-evolving field, and pave the way for a future where humans and RPLAs coexist in harmony.
SurveyAgent: A Conversational System for Personalized and Efficient Research Survey
Apr 09, 2024In the rapidly advancing research fields such as AI, managing and staying abreast of the latest scientific literature has become a significant challenge for researchers. Although previous efforts have leveraged AI to assist with literature searches, paper recommendations, and question-answering, a comprehensive support system that addresses the holistic needs of researchers has been lacking. This paper introduces SurveyAgent, a novel conversational system designed to provide personalized and efficient research survey assistance to researchers. SurveyAgent integrates three key modules: Knowledge Management for organizing papers, Recommendation for discovering relevant literature, and Query Answering for engaging with content on a deeper level. This system stands out by offering a unified platform that supports researchers through various stages of their literature review process, facilitated by a conversational interface that prioritizes user interaction and personalization. Our evaluation demonstrates SurveyAgent's effectiveness in streamlining research activities, showcasing its capability to facilitate how researchers interact with scientific literature.
Can Large Language Models Understand Real-World Complex Instructions?
Sep 17, 2023


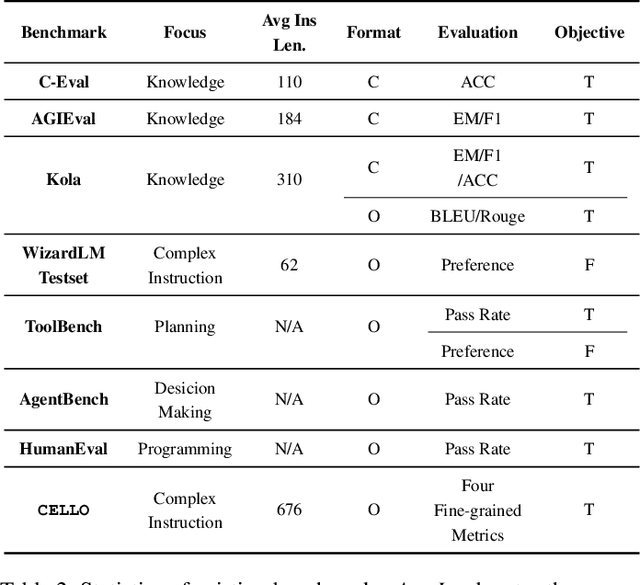
Large language models (LLMs) can understand human instructions, showing their potential for pragmatic applications beyond traditional NLP tasks. However, they still struggle with complex instructions, which can be either complex task descriptions that require multiple tasks and constraints, or complex input that contains long context, noise, heterogeneous information and multi-turn format. Due to these features, LLMs often ignore semantic constraints from task descriptions, generate incorrect formats, violate length or sample count constraints, and be unfaithful to the input text. Existing benchmarks are insufficient to assess LLMs' ability to understand complex instructions, as they are close-ended and simple. To bridge this gap, we propose CELLO, a benchmark for evaluating LLMs' ability to follow complex instructions systematically. We design eight features for complex instructions and construct a comprehensive evaluation dataset from real-world scenarios. We also establish four criteria and develop corresponding metrics, as current ones are inadequate, biased or too strict and coarse-grained. We compare the performance of representative Chinese-oriented and English-oriented models in following complex instructions through extensive experiments. Resources of CELLO are publicly available at https://github.com/Abbey4799/CELLO.