 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Learn to Map the World from Local Descriptions?
May 27, 2025Recent advances in Large Language Models (LLMs) have demonstrated strong capabilities in tasks such as code and mathematics. However, their potential to internalize structured spatial knowledge remains underexplored. This study investigates whether LLMs, grounded in locally relative human observations, can construct coherent global spatial cognition by integrating fragmented relational descriptions. We focus on two core aspects of spatial cognition: spatial perception, where models infer consistent global layouts from local positional relationships, and spatial navigation, where models learn road connectivity from trajectory data and plan optimal paths between unconnected locations. Experiments conducted in a simulated urban environment demonstrate that LLMs not only generalize to unseen spatial relationships between points of interest (POIs) but also exhibit latent representations aligned with real-world spatial distributions. Furthermore, LLMs can learn road connectivity from trajectory descriptions, enabling accurate path planning and dynamic spatial awareness during navigation.
LLM Agents for Education: Advances and Applications
Mar 14, 2025Large Language Model (LLM) agents have demonstrated remarkable capabilities in automating tasks and driving innovation across diverse educational applications. In this survey, we provide a systematic review of state-of-the-art research on LLM agents in education, categorizing them into two broad classes: (1) \emph{Pedagogical Agents}, which focus on automating complex pedagogical tasks to support both teachers and students; and (2) \emph{Domain-Specific Educational Agents}, which are tailored for specialized fields such as science education, language learning, and professional development. We comprehensively examine the technological advancements underlying these LLM agents, including key datasets, benchmarks, and algorithmic frameworks that drive their effectiveness. Furthermore, we discuss critical challenges such as privacy, bias and fairness concerns, hallucination mitigation, and integration with existing educational ecosystems. This survey aims to provide a comprehensive technological overview of LLM agents for education, fostering further research and collaboration to enhance their impact for the greater good of learners and educators alike.
MCiteBench: A Benchmark for Multimodal Citation Text Generation in MLLMs
Mar 05, 2025Multimodal Large Language Models (MLLMs) have advanced in integrating diverse modalities but frequently suffer from hallucination. A promising solution to mitigate this issue is to generate text with citations, providing a transparent chain for verification. However, existing work primarily focuses on generating citations for text-only content, overlooking the challenges and opportunities of multimodal contexts. To address this gap, we introduce MCiteBench, the first benchmark designed to evaluate and analyze the multimodal citation text generation ability of MLLMs. Our benchmark comprises data derived from academic papers and review-rebuttal interactions, featuring diverse information sources and multimodal content. We comprehensively evaluate models from multiple dimensions, including citation quality, source reliability, and answer accuracy. Through extensive experiments, we observe that MLLMs struggle with multimodal citation text generation. We also conduct deep analyses of models' performance, revealing that the bottleneck lies in attributing the correct sources rather than understanding the multimodal content.
Unraveling Cross-Modality Knowledge Conflicts in Large Vision-Language Models
Oct 11, 2024



Large Vision-Language Models (LVLMs) have demonstrated impressive capabilities for capturing and reasoning over multimodal inputs. However, these models are prone to parametric knowledge conflicts, which arise from inconsistencies of represented knowledge between their vision and language components. In this paper, we formally define the problem of $\textbf{cross-modality parametric knowledge conflict}$ and present a systematic approach to detect, interpret, and mitigate them. We introduce a pipeline that identifies conflicts between visual and textual answers, showing a persistently high conflict rate across modalities in recent LVLMs regardless of the model size. We further investigate how these conflicts interfere with the inference process and propose a contrastive metric to discern the conflicting samples from the others. Building on these insights, we develop a novel dynamic contrastive decoding method that removes undesirable logits inferred from the less confident modality components based on answer confidence. For models that do not provide logits, we also introduce two prompt-based strategies to mitigate the conflicts. Our methods achieve promising improvements in accuracy on both the ViQuAE and InfoSeek datasets. Specifically, using LLaVA-34B, our proposed dynamic contrastive decoding improves an average accuracy of 2.24%.
Unraveling Cross-Modality Knowledge Conflict in Large Vision-Language Models
Oct 04, 2024Large Vision-Language Models (LVLMs) have demonstrated impressive capabilities for capturing and reasoning over multimodal inputs. However, these models are prone to parametric knowledge conflicts, which arise from inconsistencies of represented knowledge between their vision and language components. In this paper, we formally define the problem of $\textbf{cross-modality parametric knowledge conflict}$ and present a systematic approach to detect, interpret, and mitigate them. We introduce a pipeline that identifies conflicts between visual and textual answers, showing a persistently high conflict rate across modalities in recent LVLMs regardless of the model size. We further investigate how these conflicts interfere with the inference process and propose a contrastive metric to discern the conflicting samples from the others. Building on these insights, we develop a novel dynamic contrastive decoding method that removes undesirable logits inferred from the less confident modality components based on answer confidence. For models that do not provide logits, we also introduce two prompt-based strategies to mitigate the conflicts. Our methods achieve promising improvements in accuracy on both the ViQuAE and InfoSeek datasets. Specifically, using LLaVA-34B, our proposed dynamic contrastive decoding improves an average accuracy of 2.24%.
From Persona to Personalization: A Survey on Role-Playing Language Agents
Apr 28, 2024



Recent advancements in large language models (LLMs) have significantly boosted the rise of Role-Playing Language Agents (RPLAs), i.e., specialized AI systems designed to simulate assigned personas. By harnessing multiple advanced abilities of LLMs, including in-context learning, instruction following, and social intelligence, RPLAs achieve a remarkable sense of human likeness and vivid role-playing performance. RPLAs can mimic a wide range of personas, ranging from historical figures and fictional characters to real-life individuals. Consequently, they have catalyzed numerous AI applications, such as emotional companions, interactive video games, personalized assistants and copilots, and digital clones. In this paper, we conduct a comprehensive survey of this field, illustrating the evolution and recent progress in RPLAs integrating with cutting-edge LLM technologies. We categorize personas into three types: 1) Demographic Persona, which leverages statistical stereotypes; 2) Character Persona, focused on well-established figures; and 3) Individualized Persona, customized through ongoing user interactions for personalized services. We begin by presenting a comprehensive overview of current methodologies for RPLAs, followed by the details for each persona type, covering corresponding data sourcing, agent construction, and evaluation. Afterward, we discuss the fundamental risks, existing limitations, and future prospects of RPLAs. Additionally, we provide a brief review of RPLAs in AI applications, which reflects practical user demands that shape and drive RPLA research. Through this work, we aim to establish a clear taxonomy of RPLA research and applications, and facilitate future research in this critical and ever-evolving field, and pave the way for a future where humans and RPLAs coexist in harmony.
How Easily do Irrelevant Inputs Skew the Responses of Large Language Models?
Apr 04, 2024By leveraging the retrieval of information from external knowledge databases, Large Language Models (LLMs) exhibit enhanced capabilities for accomplishing many knowledge-intensive tasks. However, due to the inherent flaws of current retrieval systems, there might exist irrelevant information within those retrieving top-ranked passages. In this work, we present a comprehensive investigation into the robustness of LLMs to different types of irrelevant information under various conditions. We initially introduce a framework to construct high-quality irrelevant information that ranges from semantically unrelated, partially related, and related to questions. Furthermore, our analysis demonstrates that the constructed irrelevant information not only scores highly on similarity metrics, being highly retrieved by existing systems, but also bears semantic connections to the context. Our investigation reveals that current LLMs still face challenges in discriminating highly semantically related information and can be easily distracted by these irrelevant yet misleading contents. Besides, we also find that current solutions for handling irrelevant information have limitations in improving the robustness of LLMs to such distractions. Resources are available at https://github.com/Di-viner/LLM-Robustness-to-Irrelevant-Information.
TravelPlanner: A Benchmark for Real-World Planning with Language Agents
Feb 05, 2024
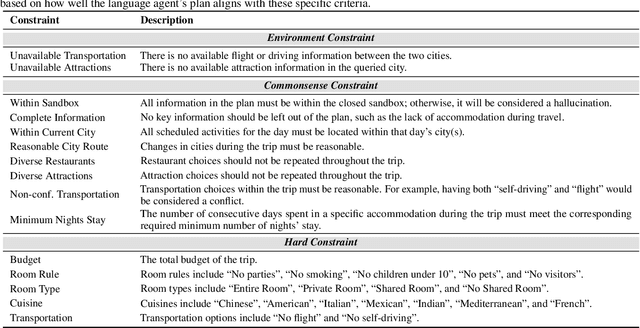

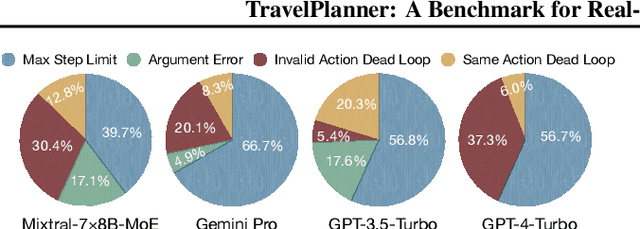
Planning has been part of the core pursuit for artificial intelligence since its conception, but earlier AI agents mostly focused on constrained settings because many of the cognitive substrates necessary for human-level planning have been lacking. Recently, language agents powered by large language models (LLMs) have shown interesting capabilities such as tool use and reasoning. Are these language agents capable of planning in more complex settings that are out of the reach of prior AI agents? To advance this investigation, we propose TravelPlanner, a new planning benchmark that focuses on travel planning, a common real-world planning scenario. It provides a rich sandbox environment, various tools for accessing nearly four million data records, and 1,225 meticulously curated planning intents and reference plans. Comprehensive evaluations show that the current language agents are not yet capable of handling such complex planning tasks-even GPT-4 only achieves a success rate of 0.6%. Language agents struggle to stay on task, use the right tools to collect information, or keep track of multiple constraints. However, we note that the mere possibility for language agents to tackle such a complex problem is in itself non-trivial progress. TravelPlanner provides a challenging yet meaningful testbed for future language agents.
Deductive Beam Search: Decoding Deducible Rationale for Chain-of-Thought Reasoning
Feb 04, 2024Recent advancements have significantly augmented the reasoning capabilities of Large Language Models (LLMs) through various methodologies, especially chain-of-thought (CoT) reasoning. However, previous methods fail to address reasoning errors in intermediate steps, leading to accumulative errors. In this paper, we propose Deductive Beam Search (DBS), which seamlessly integrates CoT and deductive reasoning with step-wise beam search for LLMs. Our approach deploys a verifier, verifying the deducibility of a reasoning step and its premises, thus alleviating the error accumulation. Furthermore, we introduce a scalable and labor-free data construction method to amplify our model's verification capabilities. Extensive experiments demonstrate that our approach significantly enhances the base performance of LLMs of various scales (7B, 13B, 70B, and ChatGPT) across 8 reasoning datasets from 3 diverse reasoning genres, including arithmetic, commonsense, and symbolic. Moreover, our analysis proves DBS's capability of detecting diverse and subtle reasoning errors and robustness on different model scales.
Towards Visual Taxonomy Expansion
Sep 12, 2023Taxonomy expansion task is essential in organizing the ever-increasing volume of new concepts into existing taxonomies. Most existing methods focus exclusively on using textual semantics, leading to an inability to generalize to unseen terms and the "Prototypical Hypernym Problem." In this paper, we propose Visual Taxonomy Expansion (VTE), introducing visual features into the taxonomy expansion task. We propose a textual hypernymy learning task and a visual prototype learning task to cluster textual and visual semantics. In addition to the tasks on respective modalities, we introduce a hyper-proto constraint that integrates textual and visual semantics to produce fine-grained visual semantics. Our method is evaluated on two datasets, where we obtain compelling results. Specifically, on the Chinese taxonomy dataset, our method significantly improves accuracy by 8.75 %. Additionally, our approach performs better than ChatGPT on the Chinese taxonomy dataset.