 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCGA: A Multi-task Classical Chinese Literary Genre Audio Corpus
Jan 14, 2026With the rapid advancement of Multimodal Large Language Models (MLLMs), their potential has garnered significant attention in Chinese Classical Studies (CCS). While existing research has primarily focused on text and visual modalities, the audio corpus within this domain remains largely underexplored. To bridge this gap, we propose the Multi-task Classical Chinese Literary Genre Audio Corpus (MCGA). It encompasses a diverse range of literary genres across six tasks: Automatic Speech Recognition (ASR), Speech-to-Text Translation (S2TT), Speech Emotion Captioning (SEC), Spoken Question Answering (SQA), Speech Understanding (SU), and Speech Reasoning (SR). Through the evaluation of ten MLLMs, our experimental results demonstrate that current models still face substantial challenges when processed on the MCGA test set. Furthermore, we introduce an evaluation metric for SEC and a metric to measure the consistency between the speech and text capabilities of MLLMs. We release MCGA and our code to the public to facilitate the development of MLLMs with more robust multidimensional audio capabilities in CCS. MCGA Corpus: https://github.com/yxduir/MCGA
HierSearch: A Hierarchical Enterprise Deep Search Framework Integrating Local and Web Searches
Aug 11, 2025Recently, large reasoning models have demonstrated strong mathematical and coding abilities, and deep search leverages their reasoning capabilities in challenging information retrieval tasks. Existing deep search works are generally limited to a single knowledge source, either local or the Web. However, enterprises often require private deep search systems that can leverage search tools over both local and the Web corpus. Simply training an agent equipped with multiple search tools using flat reinforcement learning (RL) is a straightforward idea, but it has problems such as low training data efficiency and poor mastery of complex tools. To address the above issue, we propose a hierarchical agentic deep search framework, HierSearch, trained with hierarchical RL. At the low level, a local deep search agent and a Web deep search agent are trained to retrieve evidence from their corresponding domains. At the high level, a planner agent coordinates low-level agents and provides the final answer. Moreover, to prevent direct answer copying and error propagation, we design a knowledge refiner that filters out hallucinations and irrelevant evidence returned by low-level agents. Experiments show that HierSearch achieves better performance compared to flat RL, and outperforms various deep search and multi-source retrieval-augmented generation baselines in six benchmarks across general, finance, and medical domains.
Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge
Jun 26, 2025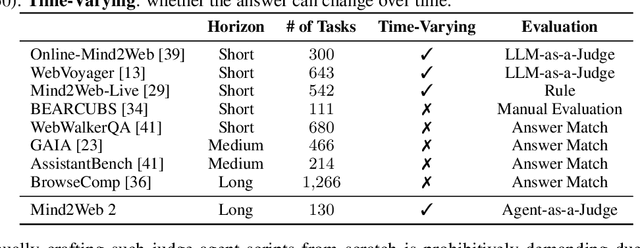
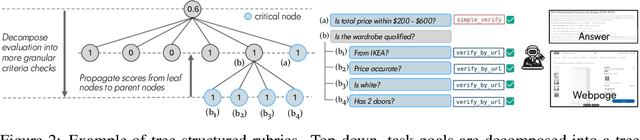

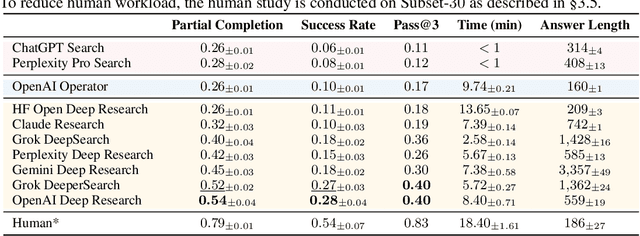
Agentic search such as Deep Research systems, where large language models autonomously browse the web, synthesize information, and return comprehensive citation-backed answers, represents a major shift in how users interact with web-scale information. While promising greater efficiency and cognitive offloading, the growing complexity and open-endedness of agentic search have outpaced existing evaluation benchmarks and methodologies, which largely assume short search horizons and static answers. In this paper, we introduce Mind2Web 2, a benchmark of 130 realistic, high-quality, and long-horizon tasks that require real-time web browsing and extensive information synthesis, constructed with over 1,000 hours of human labor. To address the challenge of evaluating time-varying and complex answers, we propose a novel Agent-as-a-Judge framework. Our method constructs task-specific judge agents based on a tree-structured rubric design to automatically assess both answer correctness and source attribution. We conduct a comprehensive evaluation of nine frontier agentic search systems and human performance, along with a detailed error analysis to draw insights for future development. The best-performing system, OpenAI Deep Research, can already achieve 50-70% of human performance while spending half the time, showing a great potential. Altogether, Mind2Web 2 provides a rigorous foundation for developing and benchmarking the next generation of agentic search systems.
Efficient Medical VIE via Reinforcement Learning
Jun 16, 2025Visual Information Extraction (VIE) converts unstructured document images into structured formats like JSON, critical for medical applications such as report analysis and online consultations. Traditional methods rely on OCR and language models, while end-to-end multimodal models offer direct JSON generation. However, domain-specific schemas and high annotation costs limit their effectiveness in medical VIE. We base our approach on the Reinforcement Learning with Verifiable Rewards (RLVR) framework to address these challenges using only 100 annotated samples. Our approach ensures dataset diversity, a balanced precision-recall reward mechanism to reduce hallucinations and improve field coverage, and innovative sampling strategies to enhance reasoning capabilities. Fine-tuning Qwen2.5-VL-7B with our RLVR method, we achieve state-of-the-art performance on medical VIE tasks, significantly improving F1, precision, and recall. While our models excel on tasks similar to medical datasets, performance drops on dissimilar tasks, highlighting the need for domain-specific optimization. Case studies further demonstrate the value of reasoning during training and inference for VIE.
ARM: Adaptive Reasoning Model
May 26, 2025



While large reasoning models demonstrate strong performance on complex tasks, they lack the ability to adjust reasoning token usage based on task difficulty. This often leads to the "overthinking" problem -- excessive and unnecessary reasoning -- which, although potentially mitigated by human intervention to control the token budget, still fundamentally contradicts the goal of achieving fully autonomous AI. In this work, we propose Adaptive Reasoning Model (ARM), a reasoning model capable of adaptively selecting appropriate reasoning formats based on the task at hand. These formats include three efficient ones -- Direct Answer, Short CoT, and Code -- as well as a more elaborate format, Long CoT. To train ARM, we introduce Ada-GRPO, an adaptation of Group Relative Policy Optimization (GRPO), which addresses the format collapse issue in traditional GRPO. Ada-GRPO enables ARM to achieve high token efficiency, reducing tokens by an average of 30%, and up to 70%, while maintaining performance comparable to the model that relies solely on Long CoT. Furthermore, not only does it improve inference efficiency through reduced token generation, but it also brings a 2x speedup in training. In addition to the default Adaptive Mode, ARM supports two additional reasoning modes: 1) Instruction-Guided Mode, which allows users to explicitly specify the reasoning format via special tokens -- ideal when the appropriate format is known for a batch of tasks. 2) Consensus-Guided Mode, which aggregates the outputs of the three efficient formats and resorts to Long CoT in case of disagreement, prioritizing performance with higher token usage.
SIFT-50M: A Large-Scale Multilingual Dataset for Speech Instruction Fine-Tuning
Apr 12, 2025We introduce SIFT (Speech Instruction Fine-Tuning), a 50M-example dataset designed for instruction fine-tuning and pre-training of speech-text large language models (LLMs). SIFT-50M is built from publicly available speech corpora, which collectively contain 14K hours of speech, and leverages LLMs along with off-the-shelf expert models. The dataset spans five languages, encompassing a diverse range of speech understanding as well as controllable speech generation instructions. Using SIFT-50M, we train SIFT-LLM, which outperforms existing speech-text LLMs on instruction-following benchmarks while achieving competitive performance on foundational speech tasks. To support further research, we also introduce EvalSIFT, a benchmark dataset specifically designed to evaluate the instruction-following capabilities of speech-text LLMs.
UniEDU: A Unified Language and Vision Assistant for Education Applications
Mar 26, 2025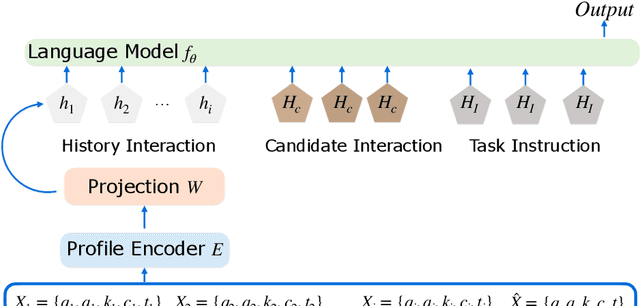
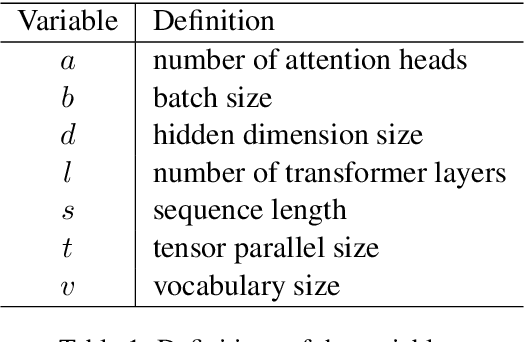
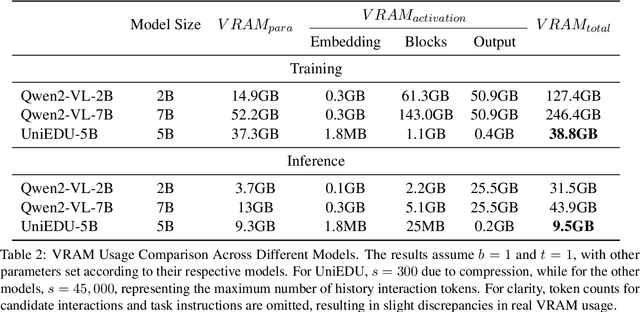
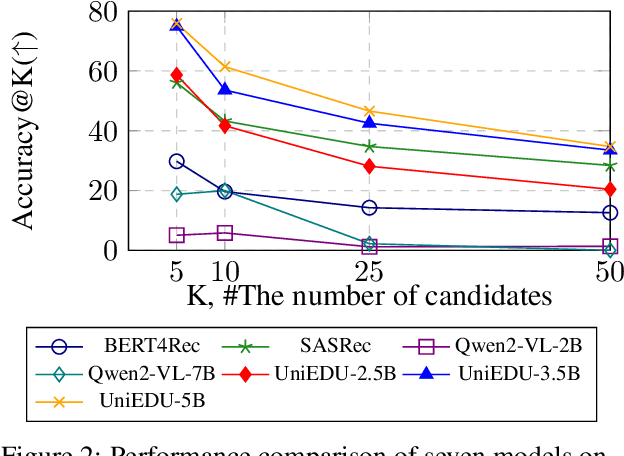
Education materials for K-12 students often consist of multiple modalities, such as text and images, posing challenges for models to fully understand nuanced information in these materials. In this paper, we propose a unified language and vision assistant UniEDU designed for various educational applications, including knowledge recommendation, knowledge tracing, time cost prediction, and user answer prediction, all within a single model. Unlike conventional task-specific models, UniEDU offers a unified solution that excels across multiple educational tasks while maintaining strong generalization capabilities. Its adaptability makes it well-suited for real-world deployment in diverse learning environments. Furthermore, UniEDU is optimized for industry-scale deployment by significantly reducing computational overhead-achieving approximately a 300\% increase in efficiency-while maintaining competitive performance with minimal degradation compared to fully fine-tuned models. This work represents a significant step toward creating versatile AI systems tailored to the evolving demands of education.
LLM Agents for Education: Advances and Applications
Mar 14, 2025Large Language Model (LLM) agents have demonstrated remarkable capabilities in automating tasks and driving innovation across diverse educational applications. In this survey, we provide a systematic review of state-of-the-art research on LLM agents in education, categorizing them into two broad classes: (1) \emph{Pedagogical Agents}, which focus on automating complex pedagogical tasks to support both teachers and students; and (2) \emph{Domain-Specific Educational Agents}, which are tailored for specialized fields such as science education, language learning, and professional development. We comprehensively examine the technological advancements underlying these LLM agents, including key datasets, benchmarks, and algorithmic frameworks that drive their effectiveness. Furthermore, we discuss critical challenges such as privacy, bias and fairness concerns, hallucination mitigation, and integration with existing educational ecosystems. This survey aims to provide a comprehensive technological overview of LLM agents for education, fostering further research and collaboration to enhance their impact for the greater good of learners and educators alike.
Implicit Reasoning in Transformers is Reasoning through Shortcuts
Mar 10, 2025Test-time compute is emerging as a new paradigm for enhancing language models' complex multi-step reasoning capabilities, as demonstrated by the success of OpenAI's o1 and o3, as well as DeepSeek's R1. Compared to explicit reasoning in test-time compute, implicit reasoning is more inference-efficient, requiring fewer generated tokens. However, why does the advanced reasoning capability fail to emerge in the implicit reasoning style? In this work, we train GPT-2 from scratch on a curated multi-step mathematical reasoning dataset and conduct analytical experiments to investigate how language models perform implicit reasoning in multi-step tasks. Our findings reveal: 1) Language models can perform step-by-step reasoning and achieve high accuracy in both in-domain and out-of-domain tests via implicit reasoning. However, this capability only emerges when trained on fixed-pattern data. 2) Conversely, implicit reasoning abilities emerging from training on unfixed-pattern data tend to overfit a specific pattern and fail to generalize further. Notably, this limitation is also observed in state-of-the-art large language models. These findings suggest that language models acquire implicit reasoning through shortcut learning, enabling strong performance on tasks with similar patterns while lacking generalization.
Exploring the Inquiry-Diagnosis Relationship with Advanced Patient Simulators
Jan 16, 2025
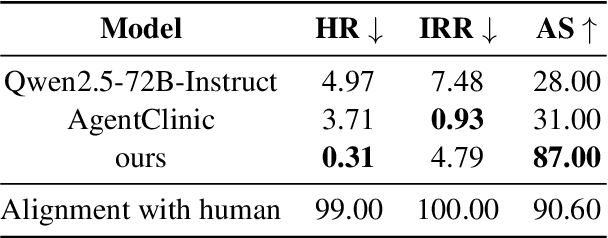


Online medical consultation (OMC) restricts doctors to gathering patient information solely through inquiries, making the already complex sequential decision-making process of diagnosis even more challenging. Recently, the rapid advancement of large language models has demonstrated a significant potential to transform OMC. However, most studies have primarily focused on improving diagnostic accuracy under conditions of relatively sufficient information, while paying limited attention to the "inquiry" phase of the consultation process. This lack of focus has left the relationship between "inquiry" and "diagnosis" insufficiently explored. In this paper, we first extract real patient interaction strategies from authentic doctor-patient conversations and use these strategies to guide the training of a patient simulator that closely mirrors real-world behavior. By inputting medical records into our patient simulator to simulate patient responses, we conduct extensive experiments to explore the relationship between "inquiry" and "diagnosis" in the consultation process. Experimental results demonstrate that inquiry and diagnosis adhere to the Liebig's law: poor inquiry quality limits the effectiveness of diagnosis, regardless of diagnostic capability, and vice versa. Furthermore, the experiments reveal significant differences in the inquiry performance of various models. To investigate this phenomenon, we categorize the inquiry process into four types: (1) chief complaint inquiry; (2) specification of known symptoms; (3) inquiry about accompanying symptoms; and (4) gathering family or medical history. We analyze the distribution of inquiries across the four types for different models to explore the reasons behind their significant performance differences. We plan to open-source the weights and related code of our patient simulator at https://github.com/LIO-H-ZEN/PatientSimulator.