 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnify Graph Learning with Text: Unleashing LLM Potentials for Session Search
May 20, 2025Session search involves a series of interactive queries and actions to fulfill user's complex information need. Current strategies typically prioritize sequential modeling for deep semantic understanding, overlooking the graph structure in interactions. While some approaches focus on capturing structural information, they use a generalized representation for documents, neglecting the word-level semantic modeling. In this paper, we propose Symbolic Graph Ranker (SGR), which aims to take advantage of both text-based and graph-based approaches by leveraging the power of recent Large Language Models (LLMs). Concretely, we first introduce a set of symbolic grammar rules to convert session graph into text. This allows integrating session history, interaction process, and task instruction seamlessly as inputs for the LLM. Moreover, given the natural discrepancy between LLMs pre-trained on textual corpora, and the symbolic language we produce using our graph-to-text grammar, our objective is to enhance LLMs' ability to capture graph structures within a textual format. To achieve this, we introduce a set of self-supervised symbolic learning tasks including link prediction, node content generation, and generative contrastive learning, to enable LLMs to capture the topological information from coarse-grained to fine-grained. Experiment results and comprehensive analysis on two benchmark datasets, AOL and Tiangong-ST, confirm the superiority of our approach. Our paradigm also offers a novel and effective methodology that bridges the gap between traditional search strategies and modern LLMs.
Bridge the Gap between Past and Future: Siamese Model Optimization for Context-Aware Document Ranking
May 20, 2025In the realm of information retrieval, users often engage in multi-turn interactions with search engines to acquire information, leading to the formation of sequences of user feedback behaviors. Leveraging the session context has proven to be beneficial for inferring user search intent and document ranking. A multitude of approaches have been proposed to exploit in-session context for improved document ranking. Despite these advances, the limitation of historical session data for capturing evolving user intent remains a challenge. In this work, we explore the integration of future contextual information into the session context to enhance document ranking. We present the siamese model optimization framework, comprising a history-conditioned model and a future-aware model. The former processes only the historical behavior sequence, while the latter integrates both historical and anticipated future behaviors. Both models are trained collaboratively using the supervised labels and pseudo labels predicted by the other. The history-conditioned model, referred to as ForeRanker, progressively learns future-relevant information to enhance ranking, while it singly uses historical session at inference time. To mitigate inconsistencies during training, we introduce the peer knowledge distillation method with a dynamic gating mechanism, allowing models to selectively incorporate contextual information. Experimental results on benchmark datasets demonstrate the effectiveness of our ForeRanker, showcasing its superior performance compared to existing methods.
Exploring the Inquiry-Diagnosis Relationship with Advanced Patient Simulators
Jan 16, 2025


Online medical consultation (OMC) restricts doctors to gathering patient information solely through inquiries, making the already complex sequential decision-making process of diagnosis even more challenging. Recently, the rapid advancement of large language models has demonstrated a significant potential to transform OMC. However, most studies have primarily focused on improving diagnostic accuracy under conditions of relatively sufficient information, while paying limited attention to the "inquiry" phase of the consultation process. This lack of focus has left the relationship between "inquiry" and "diagnosis" insufficiently explored. In this paper, we first extract real patient interaction strategies from authentic doctor-patient conversations and use these strategies to guide the training of a patient simulator that closely mirrors real-world behavior. By inputting medical records into our patient simulator to simulate patient responses, we conduct extensive experiments to explore the relationship between "inquiry" and "diagnosis" in the consultation process. Experimental results demonstrate that inquiry and diagnosis adhere to the Liebig's law: poor inquiry quality limits the effectiveness of diagnosis, regardless of diagnostic capability, and vice versa. Furthermore, the experiments reveal significant differences in the inquiry performance of various models. To investigate this phenomenon, we categorize the inquiry process into four types: (1) chief complaint inquiry; (2) specification of known symptoms; (3) inquiry about accompanying symptoms; and (4) gathering family or medical history. We analyze the distribution of inquiries across the four types for different models to explore the reasons behind their significant performance differences. We plan to open-source the weights and related code of our patient simulator at https://github.com/LIO-H-ZEN/PatientSimulator.
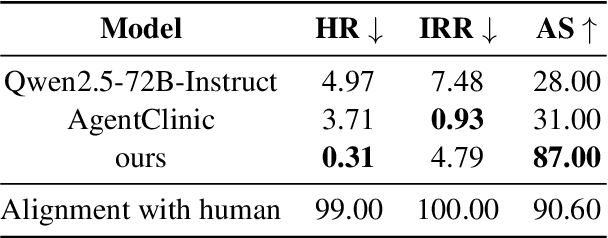
360°REA: Towards A Reusable Experience Accumulation with 360° Assessment for Multi-Agent System
Apr 08, 2024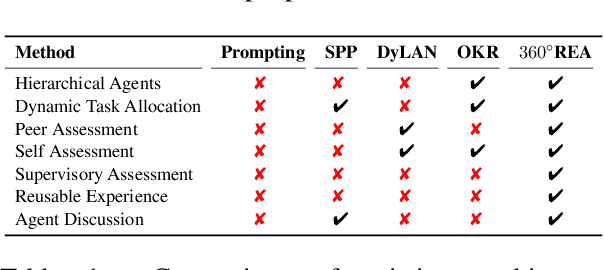
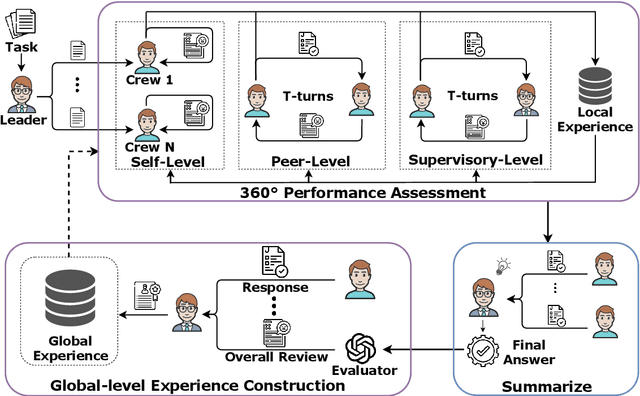
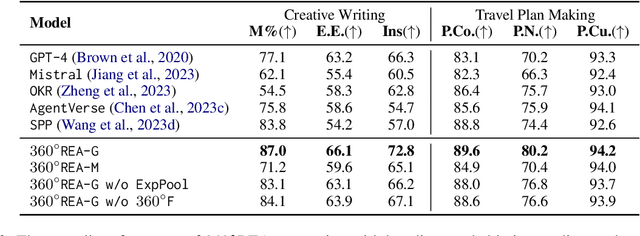
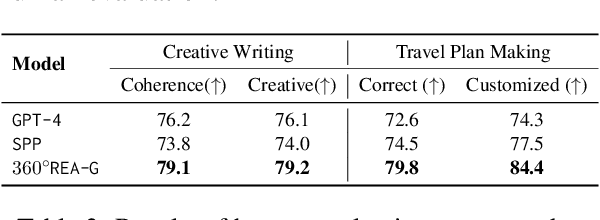
Large language model agents have demonstrated remarkable advancements across various complex tasks. Recent works focus on optimizing the agent team or employing self-reflection to iteratively solve complex tasks. Since these agents are all based on the same LLM, only conducting self-evaluation or removing underperforming agents does not substantively enhance the capability of the agents. We argue that a comprehensive evaluation and accumulating experience from evaluation feedback is an effective approach to improving system performance. In this paper, we propose Reusable Experience Accumulation with 360{\deg} Assessment (360{\deg}REA), a hierarchical multi-agent framework inspired by corporate organizational practices. The framework employs a novel 360{\deg} performance assessment method for multi-perspective performance evaluation with fine-grained assessment. To enhance the capability of agents in addressing complex tasks, we introduce dual-level experience pool for agents to accumulate experience through fine-grained assessment. Extensive experiments on complex task datasets demonstrate the effectiveness of 360{\deg}REA.
StyleChat: Learning Recitation-Augmented Memory in LLMs for Stylized Dialogue Generation
Mar 18, 2024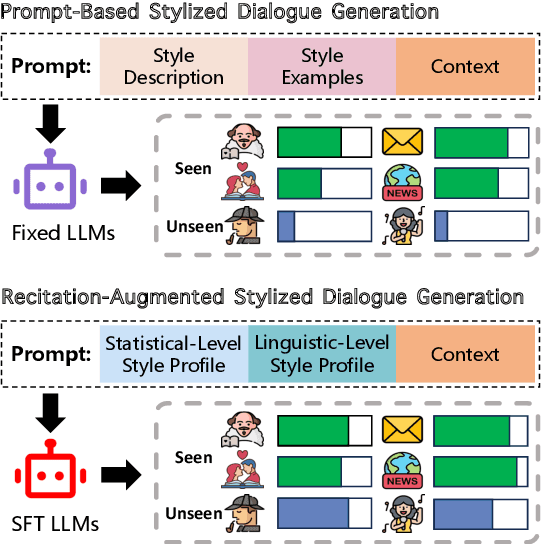
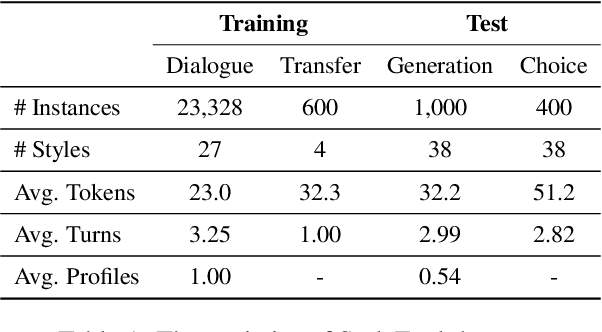
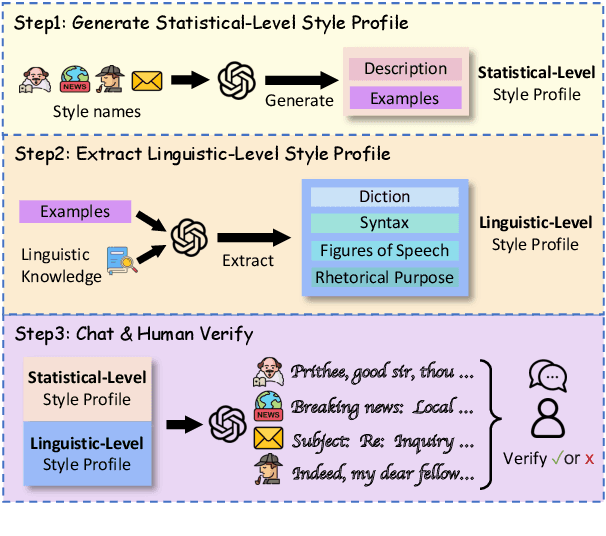
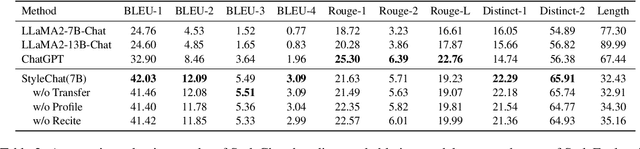
Large Language Models (LLMs) demonstrate superior performance in generative scenarios and have attracted widespread attention. Among them, stylized dialogue generation is essential in the context of LLMs for building intelligent and engaging dialogue agent. However the ability of LLMs is data-driven and limited by data bias, leading to poor performance on specific tasks. In particular, stylized dialogue generation suffers from a severe lack of supervised data. Furthermore, although many prompt-based methods have been proposed to accomplish specific tasks, their performance in complex real-world scenarios involving a wide variety of dialog styles further enhancement. In this work, we first introduce a stylized dialogue dataset StyleEval with 38 styles by leveraging the generative power of LLMs comprehensively, which has been carefully constructed with rigorous human-led quality control. Based on this, we propose the stylized dialogue framework StyleChat via recitation-augmented memory strategy and multi-task style learning strategy to promote generalization ability. To evaluate the effectiveness of our approach, we created a test benchmark that included both a generation task and a choice task to comprehensively evaluate trained models and assess whether styles and preferences are remembered and understood. Experimental results show that our proposed framework StyleChat outperforms all the baselines and helps to break the style boundary of LLMs.
StreamingDialogue: Prolonged Dialogue Learning via Long Context Compression with Minimal Losses
Mar 13, 2024



Standard Large Language Models (LLMs) struggle with handling dialogues with long contexts due to efficiency and consistency issues. According to our observation, dialogue contexts are highly structured, and the special token of \textit{End-of-Utterance} (EoU) in dialogues has the potential to aggregate information. We refer to the EoU tokens as ``conversational attention sinks'' (conv-attn sinks). Accordingly, we introduce StreamingDialogue, which compresses long dialogue history into conv-attn sinks with minimal losses, and thus reduces computational complexity quadratically with the number of sinks (i.e., the number of utterances). Current LLMs already demonstrate the ability to handle long context window, e.g., a window size of 200k or more. To this end, by compressing utterances into EoUs, our method has the potential to handle more than 200k of utterances, resulting in a prolonged dialogue learning. In order to minimize information losses from reconstruction after compression, we design two learning strategies of short-memory reconstruction (SMR) and long-memory reactivation (LMR). Our method outperforms strong baselines in dialogue tasks and achieves a 4 $\times$ speedup while reducing memory usage by 18 $\times$ compared to dense attention recomputation.
"In Dialogues We Learn": Towards Personalized Dialogue Without Pre-defined Profiles through In-Dialogue Learning
Mar 12, 2024
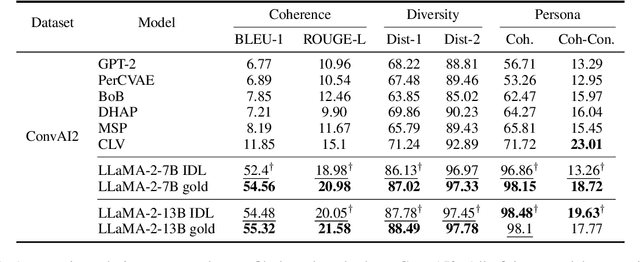
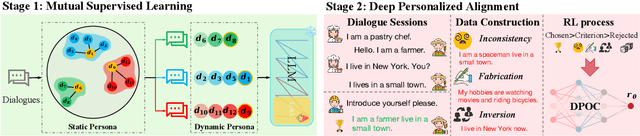
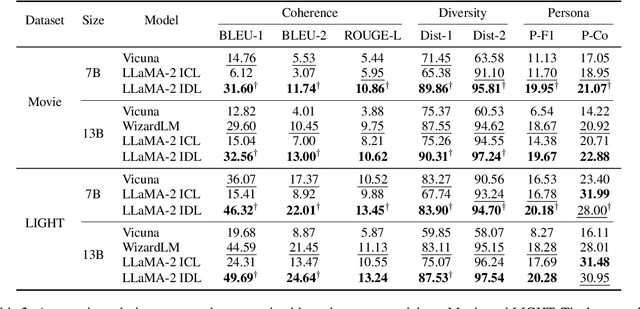
Personalized dialogue systems have gained significant attention in recent years for their ability to generate responses in alignment with different personas. However, most existing approaches rely on pre-defined personal profiles, which are not only time-consuming and labor-intensive to create but also lack flexibility. We propose In-Dialogue Learning (IDL), a fine-tuning framework that enhances the ability of pre-trained large language models to leverage dialogue history to characterize persona for completing personalized dialogue generation tasks without pre-defined profiles. Our experiments on three datasets demonstrate that IDL brings substantial improvements, with BLEU and ROUGE scores increasing by up to 200% and 247%, respectively. Additionally, the results of human evaluations further validate the efficacy of our proposed method.
Generative News Recommendation
Mar 06, 2024Most existing news recommendation methods tackle this task by conducting semantic matching between candidate news and user representation produced by historical clicked news. However, they overlook the high-level connections among different news articles and also ignore the profound relationship between these news articles and users. And the definition of these methods dictates that they can only deliver news articles as-is. On the contrary, integrating several relevant news articles into a coherent narrative would assist users in gaining a quicker and more comprehensive understanding of events. In this paper, we propose a novel generative news recommendation paradigm that includes two steps: (1) Leveraging the internal knowledge and reasoning capabilities of the Large Language Model (LLM) to perform high-level matching between candidate news and user representation; (2) Generating a coherent and logically structured narrative based on the associations between related news and user interests, thus engaging users in further reading of the news. Specifically, we propose GNR to implement the generative news recommendation paradigm. First, we compose the dual-level representation of news and users by leveraging LLM to generate theme-level representations and combine them with semantic-level representations. Next, in order to generate a coherent narrative, we explore the news relation and filter the related news according to the user preference. Finally, we propose a novel training method named UIFT to train the LLM to fuse multiple news articles in a coherent narrative. Extensive experiments show that GNR can improve recommendation accuracy and eventually generate more personalized and factually consistent narratives.
CharacterEval: A Chinese Benchmark for Role-Playing Conversational Agent Evaluation
Jan 09, 2024Recently, the advent of large language models (LLMs) has revolutionized generative agents. Among them, Role-Playing Conversational Agents (RPCAs) attract considerable attention due to their ability to emotionally engage users. However, the absence of a comprehensive benchmark impedes progress in this field. To bridge this gap, we introduce CharacterEval, a Chinese benchmark for comprehensive RPCA assessment, complemented by a tailored high-quality dataset. The dataset comprises 1,785 multi-turn role-playing dialogues, encompassing 23,020 examples and featuring 77 characters derived from Chinese novels and scripts. It was carefully constructed, beginning with initial dialogue extraction via GPT-4, followed by rigorous human-led quality control, and enhanced with in-depth character profiles sourced from Baidu Baike. CharacterEval employs a multifaceted evaluation approach, encompassing thirteen targeted metrics on four dimensions. Comprehensive experiments on CharacterEval demonstrate that Chinese LLMs exhibit more promising capabilities than GPT-4 in Chinese role-playing conversation. Source code, data source and reward model will be publicly accessible at https://github.com/morecry/CharacterEval.
Are We Falling in a Middle-Intelligence Trap? An Analysis and Mitigation of the Reversal Curse
Nov 16, 2023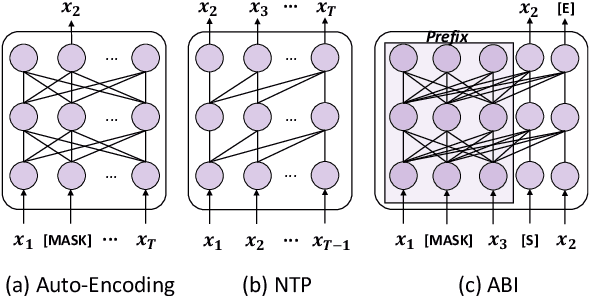
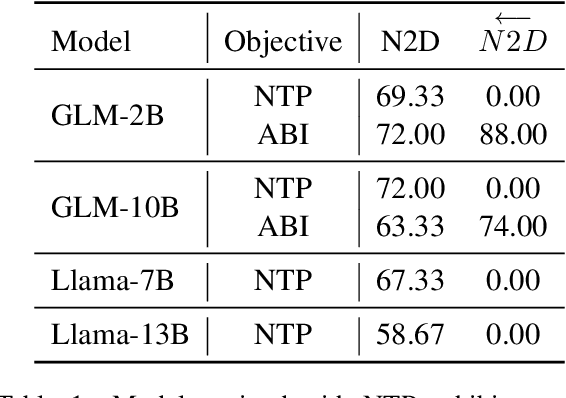

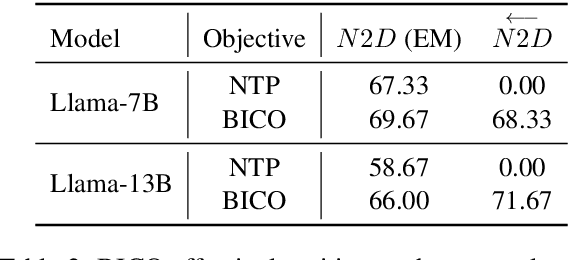
Recent studies have highlighted a phenomenon in large language models (LLMs) known as "the reversal curse," in which the order of knowledge entities in the training data biases the models' comprehension. For example, if a model is trained on sentences where entity A consistently appears before entity B, it can respond to queries about A by providing B as the answer. However, it may encounter confusion when presented with questions concerning B. We contend that the reversal curse is partially a result of specific model training objectives, particularly evident in the prevalent use of the next-token prediction within most causal language models. For the next-token prediction, models solely focus on a token's preceding context, resulting in a restricted comprehension of the input. In contrast, we illustrate that the GLM, trained using the autoregressive blank infilling objective where tokens to be predicted have access to the entire context, exhibits better resilience against the reversal curse. We propose a novel training method, BIdirectional Casual language modeling Optimization (BICO), designed to mitigate the reversal curse when fine-tuning pretrained causal language models on new data. BICO modifies the causal attention mechanism to function bidirectionally and employs a mask denoising optimization. In the task designed to assess the reversal curse, our approach improves Llama's accuracy from the original 0% to around 70%. We hope that more attention can be focused on exploring and addressing these inherent weaknesses of the current LLMs, in order to achieve a higher level of intelligence.