 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHTAA: Enhancing LLM Planning via Hybrid Toolset Agentization & Adaptation
Apr 13, 2026Enabling large language models to scale and reliably use hundreds of tools is critical for real-world applications, yet challenging due to the inefficiency and error accumulation inherent in flat tool-calling architectures. To address this, we propose Hybrid Toolset Agentization & Adaptation (HTAA), a hierarchical framework for scalable tool-use planning. We propose a novel toolset agentization paradigm, which encapsulates frequently co-used tools into specialized agent tools, thereby reducing the planner's action space and mitigating redundancy. To ensure effective coordination, we design Asymmetric Planner Adaptation, a trajectory-based training paradigm that aligns the high-level planner with agent tools via backward reconstruction and forward refinement. To validate the performance of HTAA, we conduct experiments on a real-world internal dataset, InfoVerify, based on the POI validation workflow of China's largest online large-scale ride-hailing platform, featuring long-horizon executable tool trajectories. Experiments on InfoVerify and widely-used benchmarks show that HTAA consistently achieves higher task success rates, requires short tool calling trajectories, and significantly reduces context overhead compared to strong baselines. Furthermore, in a production deployment, HTAA substantially reduces manual validation effort and operational cost, demonstrating its practical efficacy.
TOOL4POI: A Tool-Augmented LLM Framework for Next POI Recommendation
Nov 09, 2025Next Point-of-Interest (POI) recommendation is a fundamental task in location-based services. While recent advances leverage Large Language Model (LLM) for sequential modeling, existing LLM-based approaches face two key limitations: (i) strong reliance on the contextual completeness of user histories, resulting in poor performance on out-of-history (OOH) scenarios; (ii) limited scalability, due to the restricted context window of LLMs, which limits their ability to access and process a large number of candidate POIs. To address these challenges, we propose Tool4POI, a novel tool-augmented framework that enables LLMs to perform open-set POI recommendation through external retrieval and reasoning. Tool4POI consists of three key modules: preference extraction module, multi-turn candidate retrieval module, and reranking module, which together summarize long-term user interests, interact with external tools to retrieve relevant POIs, and refine final recommendations based on recent behaviors. Unlike existing methods, Tool4POI requires no task-specific fine-tuning and is compatible with off-the-shelf LLMs in a plug-and-play manner. Extensive experiments on three real-world datasets show that Tool4POI substantially outperforms state-of-the-art baselines, achieving up to 40% accuracy on challenging OOH scenarios where existing methods fail, and delivering average improvements of 20% and 30% on Acc@5 and Acc@10, respectively.
TTPA: Token-level Tool-use Preference Alignment Training Framework with Fine-grained Evaluation
May 26, 2025Existing tool-learning methods usually rely on supervised fine-tuning, they often overlook fine-grained optimization of internal tool call details, leading to limitations in preference alignment and error discrimination. To overcome these challenges, we propose Token-level Tool-use Preference Alignment Training Framework (TTPA), a training paradigm for constructing token-level tool-use preference datasets that align LLMs with fine-grained preferences using a novel error-oriented scoring mechanism. TTPA first introduces reversed dataset construction, a method for creating high-quality, multi-turn tool-use datasets by reversing the generation flow. Additionally, we propose Token-level Preference Sampling (TPS) to capture fine-grained preferences by modeling token-level differences during generation. To address biases in scoring, we introduce the Error-oriented Scoring Mechanism (ESM), which quantifies tool-call errors and can be used as a training signal. Extensive experiments on three diverse benchmark datasets demonstrate that TTPA significantly improves tool-using performance while showing strong generalization ability across models and datasets.
What Affects the Stability of Tool Learning? An Empirical Study on the Robustness of Tool Learning Frameworks
Jul 03, 2024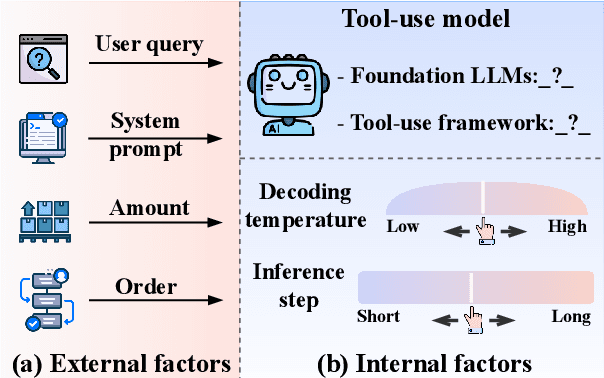

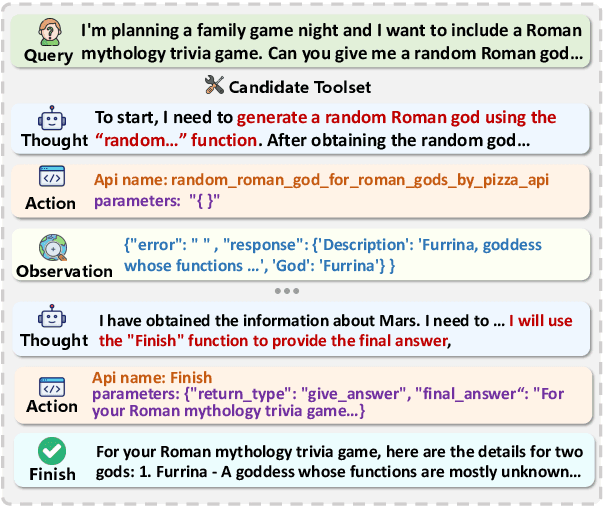
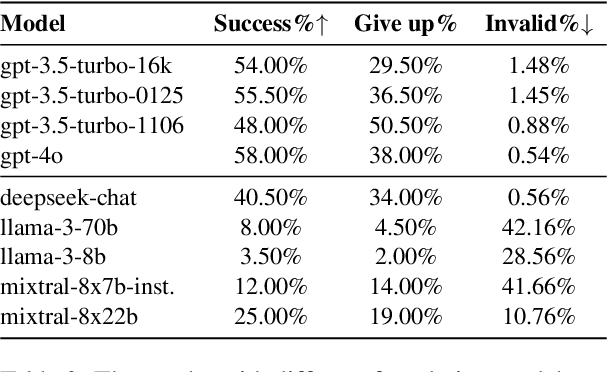
Tool learning methods have enhanced the ability of large language models (LLMs) to interact with real-world applications. Many existing works fine-tune LLMs or design prompts to enable LLMs to select appropriate tools and correctly invoke them to meet user requirements. However, it is observed in previous works that the performance of tool learning varies from tasks, datasets, training settings, and algorithms. Without understanding the impact of these factors, it can lead to inconsistent results, inefficient model deployment, and suboptimal tool utilization, ultimately hindering the practical integration and scalability of LLMs in real-world scenarios. Therefore, in this paper, we explore the impact of both internal and external factors on the performance of tool learning frameworks. Through extensive experiments on two benchmark datasets, we find several insightful conclusions for future work, including the observation that LLMs can benefit significantly from increased trial and exploration. We believe our empirical study provides a new perspective for future tool learning research.
360°REA: Towards A Reusable Experience Accumulation with 360° Assessment for Multi-Agent System
Apr 08, 2024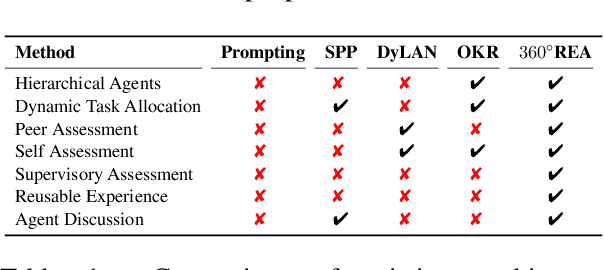
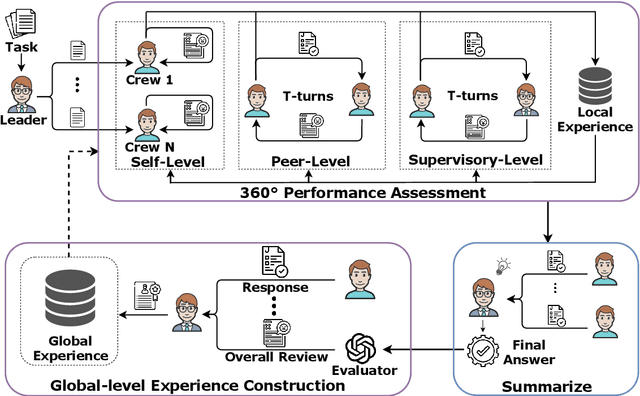
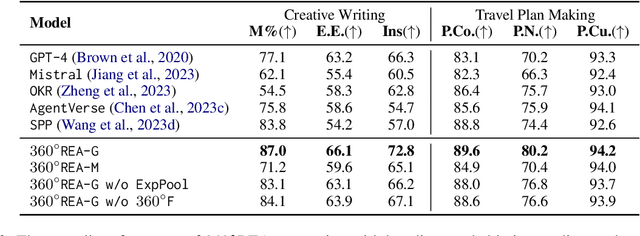
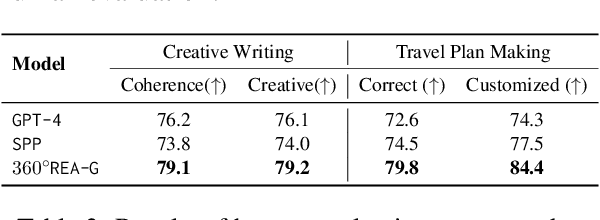
Large language model agents have demonstrated remarkable advancements across various complex tasks. Recent works focus on optimizing the agent team or employing self-reflection to iteratively solve complex tasks. Since these agents are all based on the same LLM, only conducting self-evaluation or removing underperforming agents does not substantively enhance the capability of the agents. We argue that a comprehensive evaluation and accumulating experience from evaluation feedback is an effective approach to improving system performance. In this paper, we propose Reusable Experience Accumulation with 360{\deg} Assessment (360{\deg}REA), a hierarchical multi-agent framework inspired by corporate organizational practices. The framework employs a novel 360{\deg} performance assessment method for multi-perspective performance evaluation with fine-grained assessment. To enhance the capability of agents in addressing complex tasks, we introduce dual-level experience pool for agents to accumulate experience through fine-grained assessment. Extensive experiments on complex task datasets demonstrate the effectiveness of 360{\deg}REA.