 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAVE: Flow-based Average Velocity Establishment for Sequential Recommendation
Apr 06, 2026Generative recommendation has emerged as a transformative paradigm for capturing the dynamic evolution of user intents in sequential recommendation. While flow-based methods improve the efficiency of diffusion models, they remain hindered by the ``Noise-to-Data'' paradigm, which introduces two critical inefficiencies: prior mismatch, where generation starts from uninformative noise, forcing a lengthy recovery trajectory; and linear redundancy, where iterative solvers waste computation on modeling deterministic preference transitions. To address these limitations, we propose a Flow-based Average Velocity Establishment (Fave) framework for one-step generation recommendation that learns a direct trajectory from an informative prior to the target distribution. Fave is structured via a progressive two-stage training strategy. In Stage 1, we establish a stable preference space through dual-end semantic alignment, applying constraints at both the source (user history) and target (next item) to prevent representation collapse. In Stage 2, we directly resolve the efficiency bottlenecks by introducing a semantic anchor prior, which initializes the flow with a masked embedding from the user's interaction history, providing an informative starting point. Then we learn a global average velocity, consolidating the multi-step trajectory into a single displacement vector, and enforce trajectory straightness via a JVP-based consistency constraint to ensure one-step generation. Extensive experiments on three benchmarks demonstrate that Fave not only achieves state-of-the-art recommendation performance but also delivers an order-of-magnitude improvement in inference efficiency, making it practical for latency-sensitive scenarios.
PACE: Prefix-Protected and Difficulty-Aware Compression for Efficient Reasoning
Feb 12, 2026Language Reasoning Models (LRMs) achieve strong performance by scaling test-time computation but often suffer from ``overthinking'', producing excessively long reasoning traces that increase latency and memory usage. Existing LRMs typically enforce conciseness with uniform length penalties, which over-compress crucial early deduction steps at the sequence level and indiscriminately penalize all queries at the group level. To solve these limitations, we propose \textbf{\model}, a dual-level framework for prefix-protected and difficulty-aware compression under hierarchical supervision. At the sequence level, prefix-protected optimization employs decaying mixed rollouts to maintain valid reasoning paths while promoting conciseness. At the group level, difficulty-aware penalty dynamically scales length constraints based on query complexity, maintaining exploration for harder questions while curbing redundancy on easier ones. Extensive experiments on DeepSeek-R1-Distill-Qwen (1.5B/7B) demonstrate that \model achieves a substantial reduction in token usage (up to \textbf{55.7\%}) while simultaneously improving accuracy (up to \textbf{4.1\%}) on math benchmarks, with generalization ability to code, science, and general domains.
Beyond Superficial Forgetting: Thorough Unlearning through Knowledge Density Estimation and Block Re-insertion
Nov 11, 2025Machine unlearning, which selectively removes harmful knowledge from a pre-trained model without retraining from scratch, is crucial for addressing privacy, regulatory compliance, and ethical concerns in Large Language Models (LLMs). However, existing unlearning methods often struggle to thoroughly remove harmful knowledge, leaving residual harmful knowledge that can be easily recovered. To address these limitations, we propose Knowledge Density-Guided Unlearning via Blocks Reinsertion (KUnBR), a novel approach that first identifies layers with rich harmful knowledge and then thoroughly eliminates the harmful knowledge via re-insertion strategy. Our method introduces knowledge density estimation to quantify and locate layers containing the most harmful knowledge, enabling precise unlearning. Additionally, we design a layer re-insertion strategy that extracts and re-inserts harmful knowledge-rich layers into the original LLM, bypassing gradient obstruction caused by cover layers and ensuring effective gradient propagation during unlearning. Extensive experiments conducted on several unlearning and general capability benchmarks demonstrate that KUnBR achieves state-of-the-art forgetting performance while maintaining model utility.
TOOL4POI: A Tool-Augmented LLM Framework for Next POI Recommendation
Nov 09, 2025Next Point-of-Interest (POI) recommendation is a fundamental task in location-based services. While recent advances leverage Large Language Model (LLM) for sequential modeling, existing LLM-based approaches face two key limitations: (i) strong reliance on the contextual completeness of user histories, resulting in poor performance on out-of-history (OOH) scenarios; (ii) limited scalability, due to the restricted context window of LLMs, which limits their ability to access and process a large number of candidate POIs. To address these challenges, we propose Tool4POI, a novel tool-augmented framework that enables LLMs to perform open-set POI recommendation through external retrieval and reasoning. Tool4POI consists of three key modules: preference extraction module, multi-turn candidate retrieval module, and reranking module, which together summarize long-term user interests, interact with external tools to retrieve relevant POIs, and refine final recommendations based on recent behaviors. Unlike existing methods, Tool4POI requires no task-specific fine-tuning and is compatible with off-the-shelf LLMs in a plug-and-play manner. Extensive experiments on three real-world datasets show that Tool4POI substantially outperforms state-of-the-art baselines, achieving up to 40% accuracy on challenging OOH scenarios where existing methods fail, and delivering average improvements of 20% and 30% on Acc@5 and Acc@10, respectively.
Explainable Deep Learning Based Adversarial Defense for Automatic Modulation Classification
Sep 19, 2025Deep learning (DL) has been widely applied to enhance automatic modulation classification (AMC). However, the elaborate AMC neural networks are susceptible to various adversarial attacks, which are challenging to handle due to the generalization capability and computational cost. In this article, an explainable DL based defense scheme, called SHapley Additive exPlanation enhanced Adversarial Fine-Tuning (SHAP-AFT), is developed in the perspective of disclosing the attacking impact on the AMC network. By introducing the concept of cognitive negative information, the motivation of using SHAP for defense is theoretically analyzed first. The proposed scheme includes three stages, i.e., the attack detection, the information importance evaluation, and the AFT. The first stage indicates the existence of the attack. The second stage evaluates contributions of the received data and removes those data positions using negative Shapley values corresponding to the dominating negative information caused by the attack. Then the AMC network is fine-tuned based on adversarial adaptation samples using the refined received data pattern. Simulation results show the effectiveness of the Shapley value as the key indicator as well as the superior defense performance of the proposed SHAP-AFT scheme in face of different attack types and intensities.
CESRec: Constructing Pseudo Interactions for Sequential Recommendation via Conversational Feedback
Sep 11, 2025Sequential Recommendation Systems (SRS) have become essential in many real-world applications. However, existing SRS methods often rely on collaborative filtering signals and fail to capture real-time user preferences, while Conversational Recommendation Systems (CRS) excel at eliciting immediate interests through natural language interactions but neglect historical behavior. To bridge this gap, we propose CESRec, a novel framework that integrates the long-term preference modeling of SRS with the real-time preference elicitation of CRS. We introduce semantic-based pseudo interaction construction, which dynamically updates users'historical interaction sequences by analyzing conversational feedback, generating a pseudo-interaction sequence that seamlessly combines long-term and real-time preferences. Additionally, we reduce the impact of outliers in historical items that deviate from users'core preferences by proposing dual alignment outlier items masking, which identifies and masks such items using semantic-collaborative aligned representations. Extensive experiments demonstrate that CESRec achieves state-of-the-art performance by boosting strong SRS models, validating its effectiveness in integrating conversational feedback into SRS.
TTPA: Token-level Tool-use Preference Alignment Training Framework with Fine-grained Evaluation
May 26, 2025Existing tool-learning methods usually rely on supervised fine-tuning, they often overlook fine-grained optimization of internal tool call details, leading to limitations in preference alignment and error discrimination. To overcome these challenges, we propose Token-level Tool-use Preference Alignment Training Framework (TTPA), a training paradigm for constructing token-level tool-use preference datasets that align LLMs with fine-grained preferences using a novel error-oriented scoring mechanism. TTPA first introduces reversed dataset construction, a method for creating high-quality, multi-turn tool-use datasets by reversing the generation flow. Additionally, we propose Token-level Preference Sampling (TPS) to capture fine-grained preferences by modeling token-level differences during generation. To address biases in scoring, we introduce the Error-oriented Scoring Mechanism (ESM), which quantifies tool-call errors and can be used as a training signal. Extensive experiments on three diverse benchmark datasets demonstrate that TTPA significantly improves tool-using performance while showing strong generalization ability across models and datasets.
CulFiT: A Fine-grained Cultural-aware LLM Training Paradigm via Multilingual Critique Data Synthesis
May 26, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks, yet they often exhibit a specific cultural biases, neglecting the values and linguistic diversity of low-resource regions. This cultural bias not only undermines universal equality, but also risks reinforcing stereotypes and perpetuating discrimination. To address this, we propose CulFiT, a novel culturally-aware training paradigm that leverages multilingual data and fine-grained reward modeling to enhance cultural sensitivity and inclusivity. Our approach synthesizes diverse cultural-related questions, constructs critique data in culturally relevant languages, and employs fine-grained rewards to decompose cultural texts into verifiable knowledge units for interpretable evaluation. We also introduce GlobalCultureQA, a multilingual open-ended question-answering dataset designed to evaluate culturally-aware responses in a global context. Extensive experiments on three existing benchmarks and our GlobalCultureQA demonstrate that CulFiT achieves state-of-the-art open-source model performance in cultural alignment and general reasoning.
Beyond Profile: From Surface-Level Facts to Deep Persona Simulation in LLMs
Feb 18, 2025Previous approaches to persona simulation large language models (LLMs) have typically relied on learning basic biographical information, or using limited role-play dialogue datasets to capture a character's responses. However, a holistic representation of an individual goes beyond surface-level facts or conversations to deeper thoughts and thinking. In this work, we introduce CharacterBot, a model designed to replicate both the linguistic patterns and distinctive thought processes of a character. Using Lu Xun, a renowned Chinese writer, as a case study, we propose four training tasks derived from his 17 essay collections. These include a pre-training task focused on mastering external linguistic structures and knowledge, as well as three fine-tuning tasks: multiple-choice question answering, generative question answering, and style transfer, each aligning the LLM with Lu Xun's internal ideation and writing style. To optimize learning across these tasks, we introduce a CharLoRA parameter updating mechanism, where a general linguistic style expert collaborates with other task-specific experts to better study both the language style and the understanding of deeper thoughts. We evaluate CharacterBot on three tasks for linguistic accuracy and opinion comprehension, demonstrating that it significantly outperforms the baselines on our adapted metrics. We hope that this work inspires future research on deep character persona simulation LLM.
LLMs are Also Effective Embedding Models: An In-depth Overview
Dec 17, 2024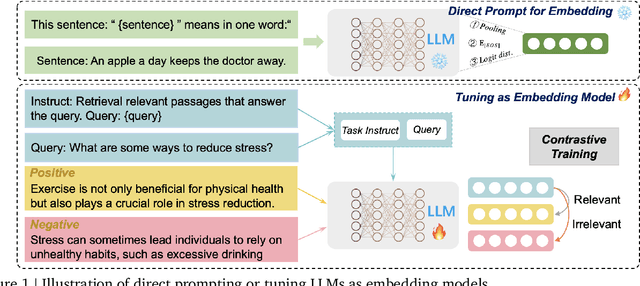
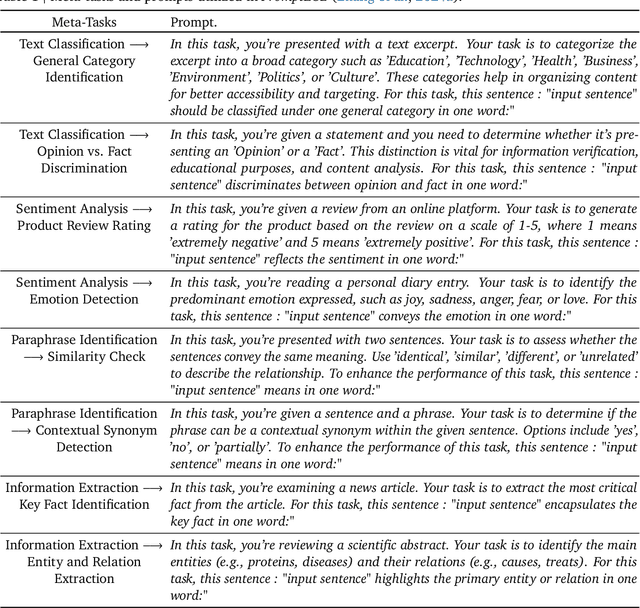

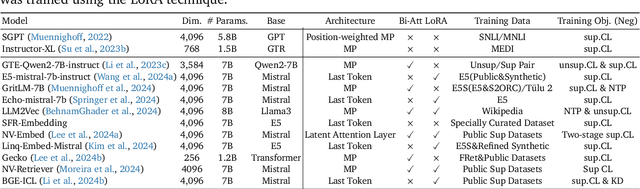
Large language models (LLMs) have revolutionized natural language processing by achieving state-of-the-art performance across various tasks. Recently, their effectiveness as embedding models has gained attention, marking a paradigm shift from traditional encoder-only models like ELMo and BERT to decoder-only, large-scale LLMs such as GPT, LLaMA, and Mistral. This survey provides an in-depth overview of this transition, beginning with foundational techniques before the LLM era, followed by LLM-based embedding models through two main strategies to derive embeddings from LLMs. 1) Direct prompting: We mainly discuss the prompt designs and the underlying rationale for deriving competitive embeddings. 2) Data-centric tuning: We cover extensive aspects that affect tuning an embedding model, including model architecture, training objectives, data constructions, etc. Upon the above, we also cover advanced methods, such as handling longer texts, and multilingual and cross-modal data. Furthermore, we discuss factors affecting choices of embedding models, such as performance/efficiency comparisons, dense vs sparse embeddings, pooling strategies, and scaling law. Lastly, the survey highlights the limitations and challenges in adapting LLMs for embeddings, including cross-task embedding quality, trade-offs between efficiency and accuracy, low-resource, long-context, data bias, robustness, etc. This survey serves as a valuable resource for researchers and practitioners by synthesizing current advancements, highlighting key challenges, and offering a comprehensive framework for future work aimed at enhancing the effectiveness and efficiency of LLMs as embedding models.